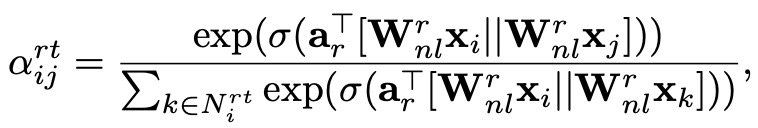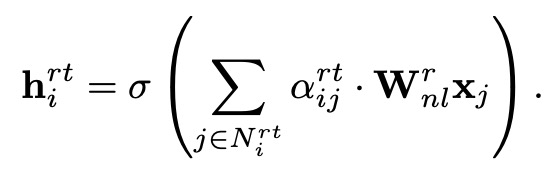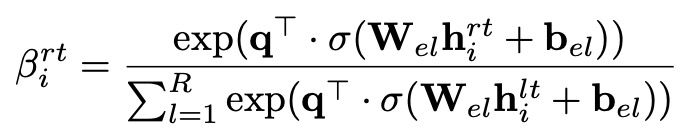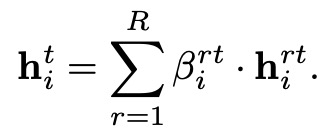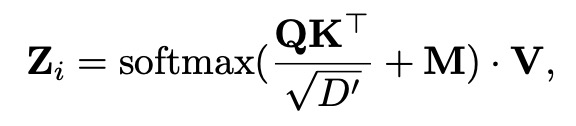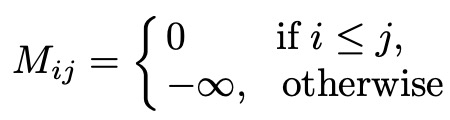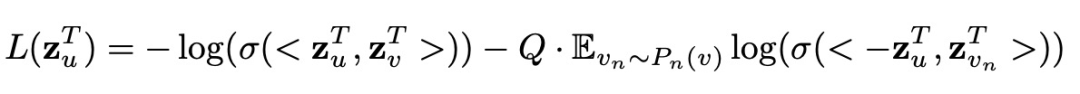![]()
导读:
在现实生活中,用户对于一件事物的关注度即关系图往往是会随着时间
而改变的
。
按照静态图的建模方法将
不能显示地建模用户在
时序上的兴趣变化。
动态网络表征学习
不仅能学习到当前网络的结构信息,而且也能学习到网络在时间上的变化
,
但是目前主要还是针对动态同构网络
,
本文
在此基础上
提出了基于层次化注意力机制的动态图表征算法
,
是
推荐底层算法模型上的一次突破
。
01
背景介绍
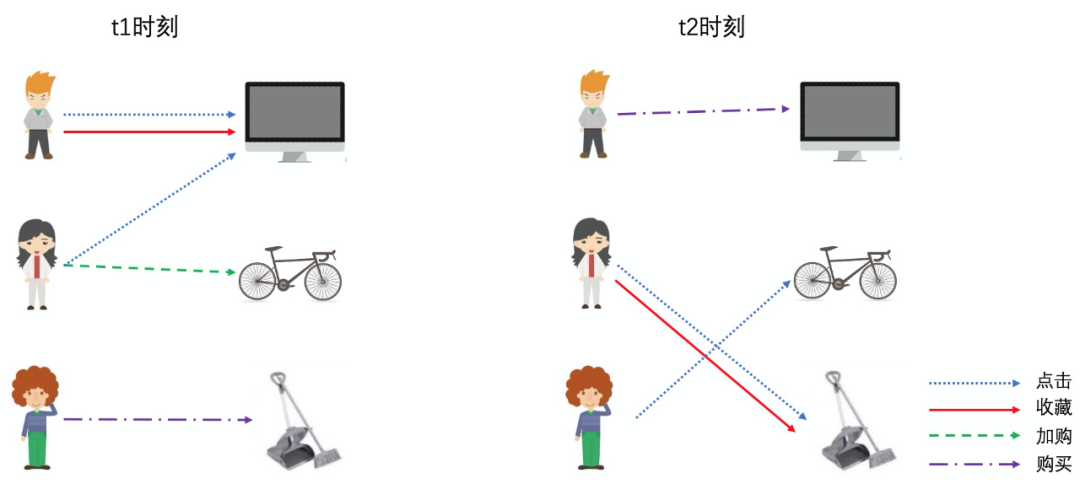
目前大多数 Graph Embedding 的方法如 node2vec、GCN、GraphSAGE 和 GAT 等主要是针对静态图模型的方法,也就是假设图是不会改变的。但是在现实生活中,关系图往往是会随着时间而改变。比如用户在一段时间内对连衣裙的兴趣会慢慢转移到高跟鞋,在关系图上的表现就是前一段时间用户的邻居主要都是连衣裙,但是后面一段时间用户的邻居主要都是高跟鞋。如果按照静态图的建模方法,连衣裙和高跟鞋都会出现在同一张图上,虽然可以在关系边上加上时间信息,但是其只能作为控制游走或聚合的权重,并不能显示地建模用户在时序上的兴趣变化。
动态网络表征学习也叫做 Dynamic Graph Embedding ( Dynamic Network Embedding ),不仅能学习到当前网络的结构信息,而且也能学习到网络在时间上的变化,是目前 Graph Embedding 的一个热门方向。近年来在动态网络表征学习方面相关的算法也如雨后春笋般被提出,如 DynamicTriad、DySAT 等。但是目前主要还是针对动态同构网络,受到 DySAT 和 HAN 算法的启发,我们在动态异构网络方面提出了基于层次化注意力机制的动态图表征算法 ( DyHAN ),在离线测评上都优于目前现有的方法。
在业务落地上,考虑到开发难度和线上曝光情况,我们在之前 GraphSAGE i2i 基础上,引入动态模型更好地学习时序信息,在业务上取得了一定效果。
在创新层面,针对用户和商品的动态异构图,我们提出基于层次化注意力机制的动态图表征算法 ( DyHAN, short for Dynamic Heterogeneous Graph Embedding using Hierarchical Attentions )。
这里主要描述一下我们自己的数据集的构建信息,其他的数据集也是类似的。我们使用用户历史行为日志来构建。
边类型:点击、询盘 ( AB ) 和 Order 等。
时间分片:每天的用户行为作为一个时间分片,取 10 天的时间分片来训练,第 11 天的来做评测。
节点信息:节点 id ( 这里为了方便实验,直接使用节点id特征,如果图有其他特征也可以加入进去 )。
![]()
这样构建的关系图就是一个具有 11 个时间分片,2 个节点类型和 3 个边类型的异构动态图。在一个时间分片下,如果只看点击类型的边,我们就得到了这个时间分片下点击边类型的子图。
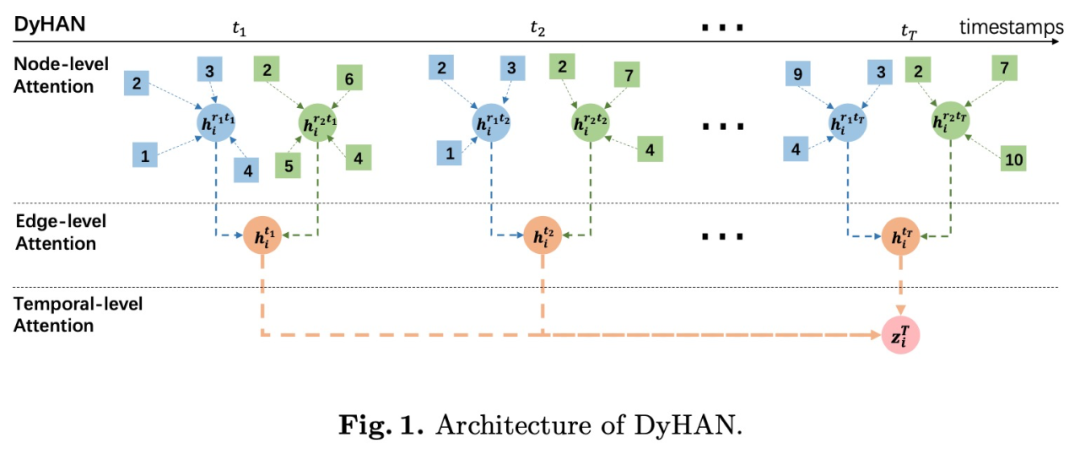
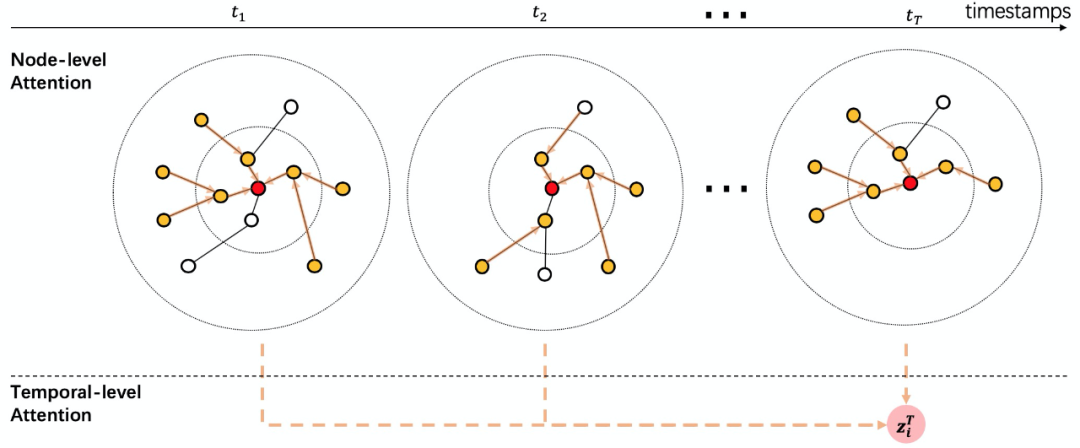
算法主要为三层注意力机制,模型结构如图1所示。这里三层的融合分别是节点层级、边层级和时序层级上的聚合。在 DyHAN 里我们都使用了注意力机制,但是实际上这三个模块都可以替换成其他聚合方法,如节点层级的聚合可以使用 GraphSAGE 的 mean、mean-pooling 和 max-pooling 的方法。时间层级的聚合可以使用 RNN 类的方法,如 LSTM 和 GRU 等。
![]()
节点层级的聚合 ( Node-level Attention ),目的为每个时间分片下每个边类型子图里的节点都做一个 attention 融合自身与其邻居的信息。这样融合后的向量能表示这个节点在这一类边类型下的语义信息。query 为节点本身,key 为节点的邻居 ( 包括自己 )。
![]()
![]()
边层级的聚合 ( Edge-level Attention ), 主要作用为对每个时间分片下节点的边类型向量进行汇聚,某一类型的边类型向量可能对这个节点的贡献比较大。比如 order 的边类型向量对于交易品的贡献就比较大。
![]()
![]()
时序层级的聚合 ( Temporal-level Attention ),主要把每个时间分片上的节点向量聚合起来。这里使用一个标准的 Scaled-Dot-Product Attention。M 为一个 mask 矩阵,主要是为了使节点向量只能看到过去的节点向量。
![]()
![]()
为了增加 expressive 的能力,每一层的聚合都可以使用 multi-head 机制。
损失函数选取 Cross Entropy,正负样本只在最后一个时间分片上选取。
![]()
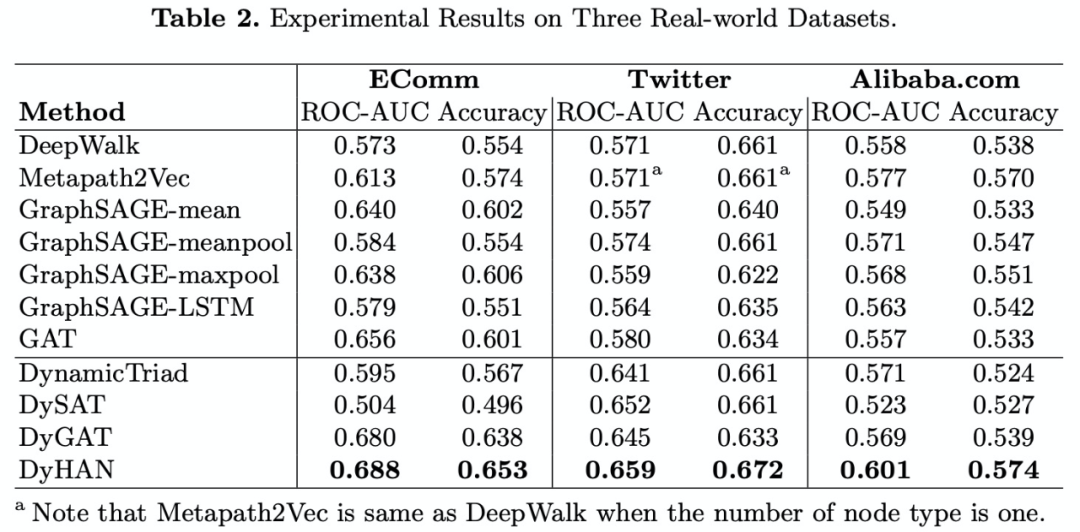
推荐的向量化召回就是计算两个节点的相似度来预测用户潜在感兴趣的商品,为了更好地贴合业务,我们选择边预测作为我们的实验任务。Baseline 选取了静态和动态图表征上比较有代表性的算法,如静态的主要有 DeepWalk、metapath2vec、GraphSAGE、GAT;动态的主要有 DynamicTriad、DySAT 等。我们在两个公开数据集和我们自己的数据集上进行了实验,下面是实验结果。
![]()
Luwei Yang, Zhibo Xiao, Wen Jiang, Yi Wei, Yi Hu, and Hao Wang, “Dynamic heterogeneous graph embedding using hierarchical attentions,” in Proceedings of the 42nd European Conference on Information Retrieval, 2020
03
实践探索
考虑到目前 ICBU 推荐引擎的机制对用户向量化的曝光比例较低,在动态图表征的上线落地上我们首选在 i2i 上进行尝试,即直接在 GraphSAGE i2i 的基础上引入动态模型。
每个时间分片图的构建沿用之前 GraphSAGE i2i 的模式,由于工程上实现的机制,只对最后一个时间分片上的节点 infer 出节点向量。因此为了不减少商品覆盖度,每一个时间分片的设置为 90 天,时间分片之间设置适当的 overlapping。
这样模型其实就变成了前文详述的 DyHAN 的简化版,其分为了两层结构,第一层为GraphSAGE 的聚合机制,主要为对每个时间分片计算出节点向量。第二层为时序层级上的聚合,采用上文介绍的 Scaled-Dot-Product Attention。最后的训练是无监督训练,无监督学习样本的选取做了一些优化,同时损失函数使用 Triplet Loss。
![]()
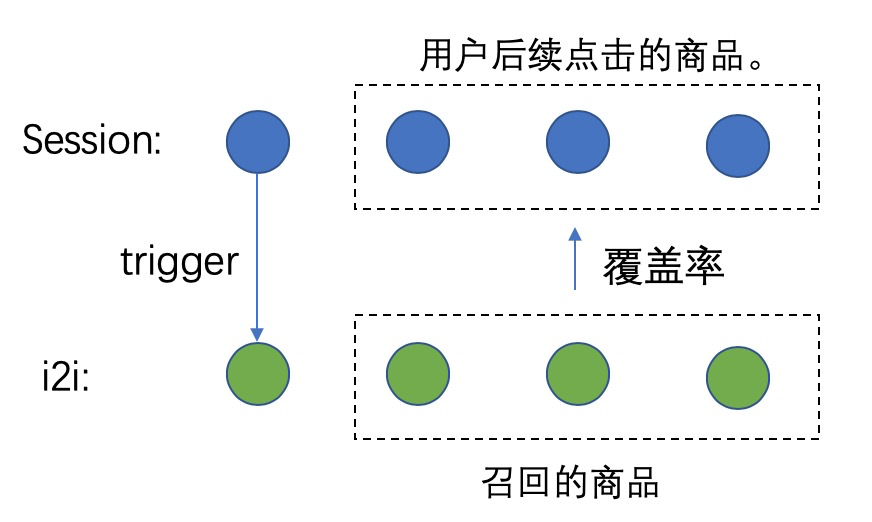
离线评测:我们随机选取 session 下第一个商品作为 trigger,计算同 session 后续点击的 distinct 商品的覆盖率。这样的样本选取一万个, 原 graphsage_i2i 的覆盖率增量为 4.2%,使用 dynamic_i2i 的覆盖率增量为 10.9%。
![]()
线上效果:在 Detail 跨店推荐上线,L-AB 转化率提升 3.54%,L-O 转化率提升 14.23%。在整体 Detail 页的转化方面,D-AB 转化率提升 0.85%,D-O 转化率提升 2.57%。
04
总结
在动态图表征学习上我们创新地提出了 DyHAN 的方法用于异构动态图建模,同时在阿里巴巴国际站 ( ICBU ) 推荐领域引入动态图表征模型,在业务上取得了一定的效果。同时我们也发现这种时间分片的动态图表征模式运算开销比较大,因为每一个时间分片都要运行一个静态的图表征模型,如何减小运算开销是未来的一个研究方向。同时在时间维度上如何更好地融合时序信息也是未来的一个研究方向。
05
参考资料
【1】Grover, Aditya, and Jure Leskovec. "node2vec: Scalable feature learning for networks." Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016.
【2】Kipf, Thomas N., and Max Welling. "Semi-supervised classification with graph convolutio
nal networks." arXiv preprint arXiv:1609.02907 (2016).
【3】Hamilton, Will, Zhitao Ying, and Jure Leskovec. "Inductive representation learning on large graphs." Advances in neural information processing systems. 2017.
【4】Veličković, Petar, et al. "Graph attention networks." arXiv preprint arXiv:1710.10903 (2017).
【5】Zhou, Lekui, et al. "Dynamic network embedding by modeling triadic closure process." Thirty-Second AAAI Conference on Artificial I
ntelligence. 2018.
【6】Wang, X., Ji, H., Shi, C., Wang, B., Ye, Y., Cui, P., & Yu, P. S. (2019, May). Heterogeneous graph attention network. In The World
Wide Web Conference (pp. 2022-2032).
【7】Sankar, Aravind, et al. "DySAT: Deep Neural Representation Learning on Dynamic Graphs via Self-Attention Networks." Proceedings of the 13th International Conference on Web Search and Data Mining. 2020.
【8】L. Yang, et al. “Dynamic heterogeneous graph embedding using hierarchical attentions,” in Proceedings of the 42nd European Conference on Information Retrieval, 2020
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
会员推荐:
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:
![]()
文章推荐:
阿里新一代Rank技术
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。
![]()
🧐分享、点赞、在看,给个三连击呗!👇