一种关于低代码平台(LCDP)建设实践与设计思路

背景
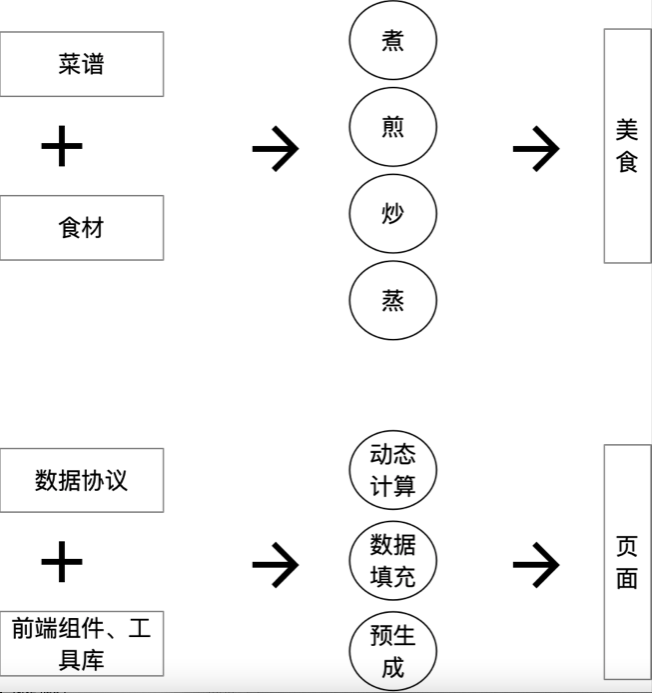
什么是LCDP
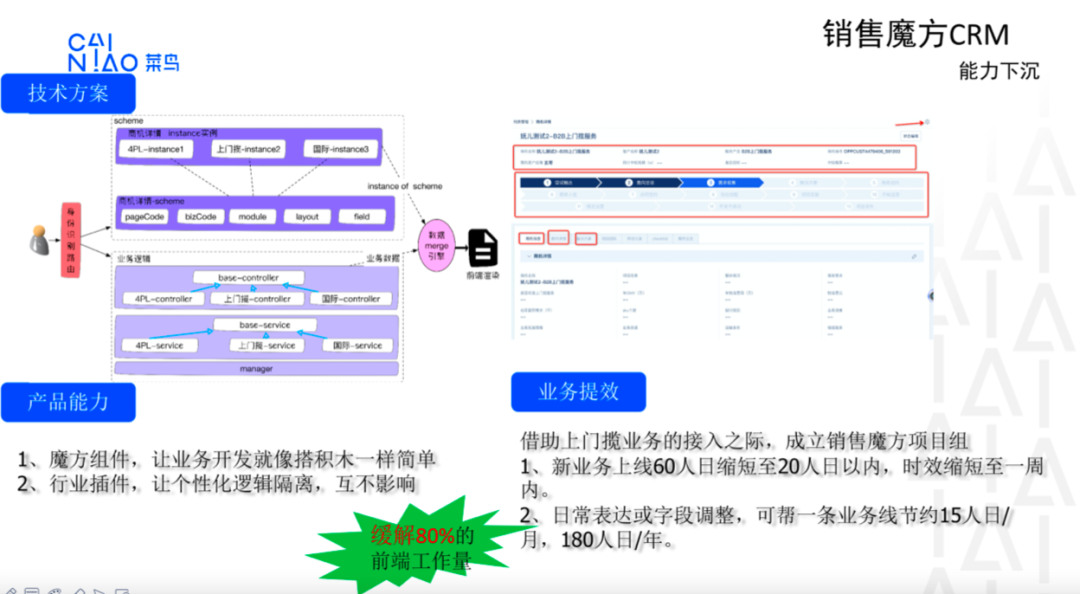
魔方核心能力
产品能力
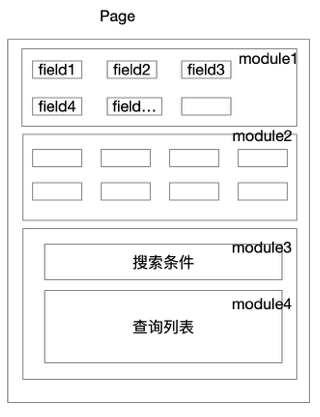
页面的千行千面(千人千面),包含同一个页面不同布局、不同字段、不同样式
数据模块的千行千面(千人千面),根据不同身份执行不同的业务技术逻辑和服务编排
page一键创建,在没有新的业务组建和新的module情况无需开发接入,0代码上线,运营同学自行配置页面。
前端组件复用,在没有新前端组件,前端无需参与开发,后端只需编写module对应的业务接口。
实现module可复用,module数据渲染、数据写入,查询条件、浮层、半推页面、页面操作
新增字段扩展0代码,模型字段可以自定义,动态扩展,可定义来自本地数据库、远程HSF接口数据
环境可隔离,测试、预发、生产
平台和业务代码分离,业务上线只需关注业务逻辑本身的代码。
DO DTO可定义,动态映射
数据枚举动态定义,动态绑定
魔方的设计
产品界面

用户
产品模块
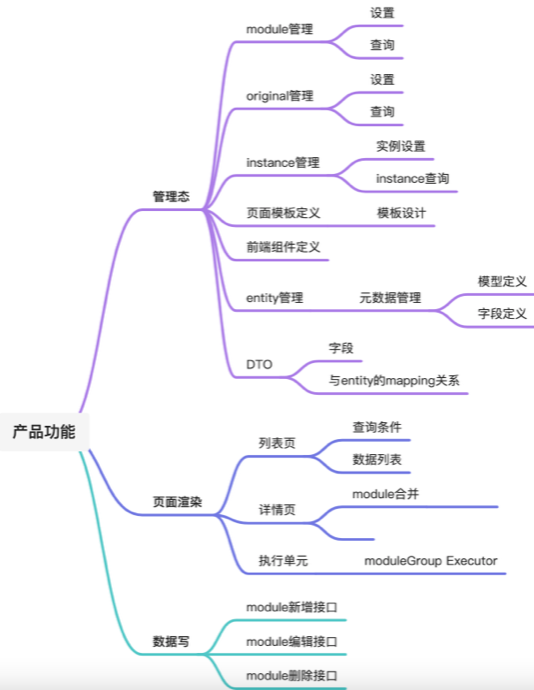
核心逻辑
前端渲染
后端绑定
模型设计
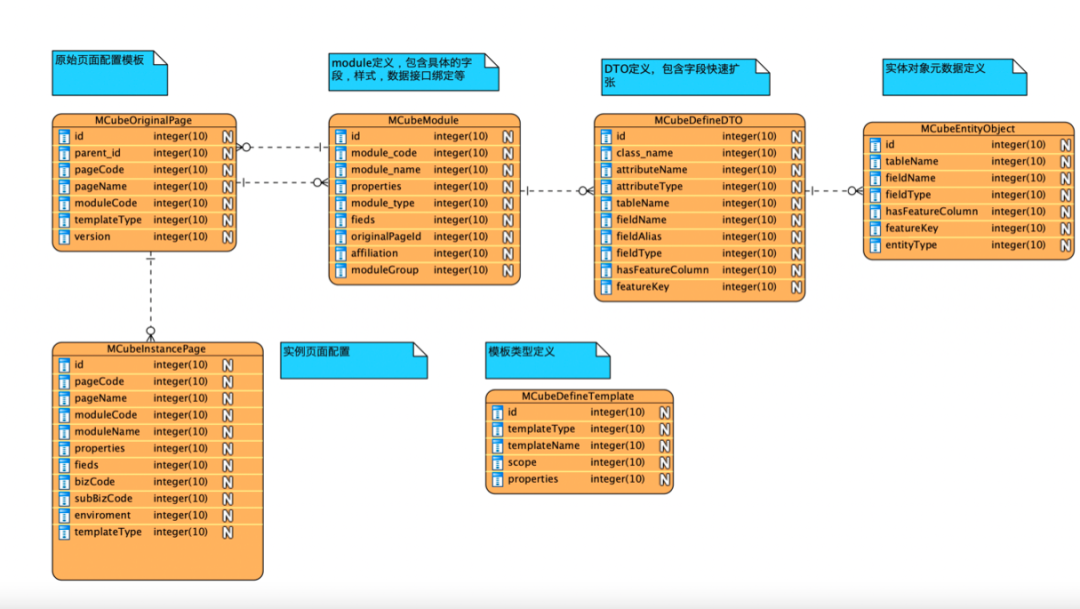
template定义
-
列表页面 -
详情页面 -
半开页面 -
表单提交页面
page定义
page_code
custom_dimension
biz_code
sub_biz_code
enviroment
module定义
module_type 定义
McubeContextAware
public class McubeContextAware implements ApplicationContextAware {private static volatile ApplicationContext alc;private ModuleBeanFactory moduleBeanFactory;private ModuleGroupBeanFactory moduleGroupBeanFactory;public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {alc = applicationContext;}public void init(){setModuleBeanMap();setModuleGroupBeanMap();}private void setModuleBeanMap() {Map<String, McubeModuleExecutor> beanMap = alc.getBeansOfType(McubeModuleExecutor.class);if (beanMap != null) {beanMap.values().stream().forEach(m -> {McubeModule module = AnnotationUtils.findAnnotation(m.getClass(), McubeModule.class);if (module != null) {String code = module.code();String name = module.name();if (code != null) {moduleBeanFactory.getMcubeBeanMap().put(code, m);}}});}}private void setModuleGroupBeanMap() {Map<String, McubeModuleExecutor> beanMap = alc.getBeansOfType(McubeModuleExecutor.class);if (beanMap != null) {beanMap.values().stream().forEach(m -> {McubeModuleGroup module = AnnotationUtils.findAnnotation(m.getClass(), McubeModuleGroup.class);if (module != null) {String code = module.code();String name = module.name();moduleGroupBeanFactory.getMcubeBeanMap().put(code,m);}});}}}
执行单元(moduleGroup executor)
/*** Created by hzliuxuan on 2022/5/27.* @author hzliuxuan* 模块接口*/public interface McubeModuleExecutor<T,V> {/*** 填充数据,页面渲染,一般是read接口* @param value* @return*/T populate(V value);/*** 编辑模块* @param value* @return*/void edit(V value);/*** 写接口* @param value* @return*/void add(V value);/*** 删除接口* @param value* @return*/void delete(V value);}
@Inherited@Component@Target({ElementType.TYPE})@Retention(RetentionPolicy.RUNTIME)public @interface McubeModuleGroup {/*** moduleGroup code (必填,唯一标识)*/@NotNullString code();/*** 对应module code值*/@NotNullString[] moduleCodes();/*** moduleGroup name*/String name();@NotNullModuleGroupType type();}
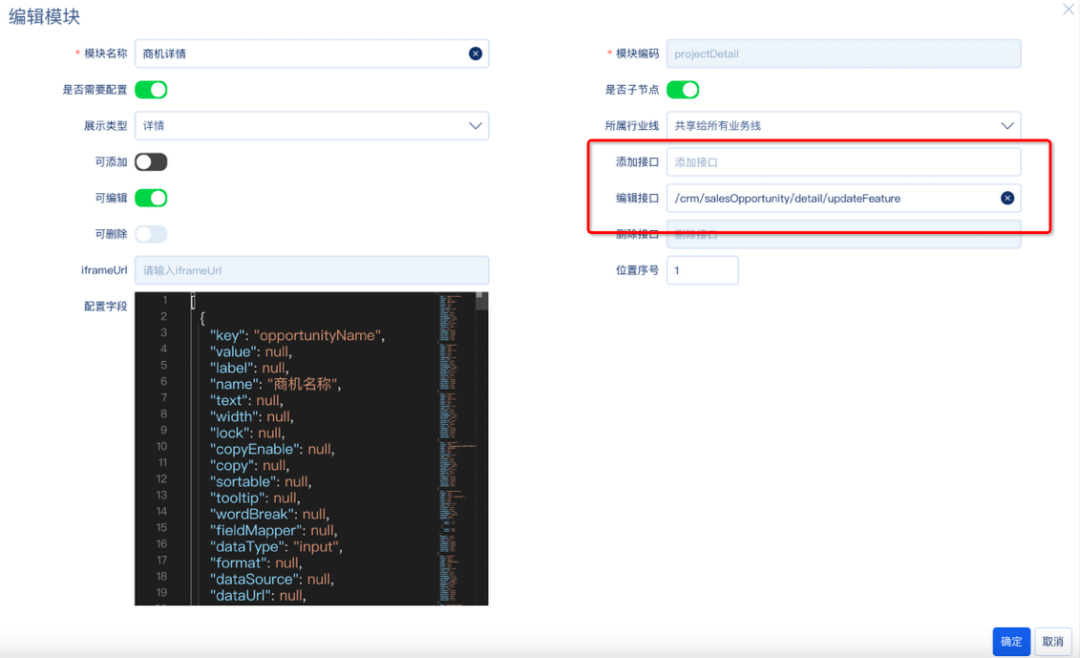
field定义
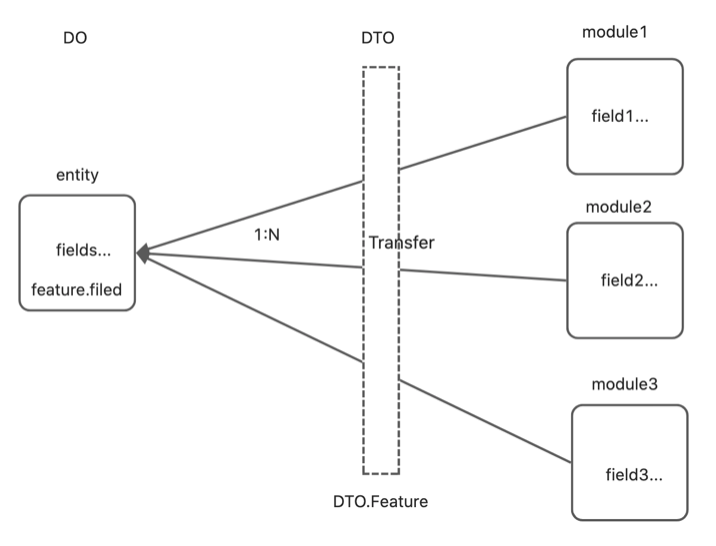
field数据结构定义
[{"key": "equityInvestment","value": null,"label": null,"name": "权益投放记录","text": null,"width": null,"lock": null,"copyEnable": null,"copy": null,"sortable": null,"tooltip": null,"wordBreak": null,"fieldMapper": null,/**数据类型取值input, select, date, address(地址), switch(开关), staffSelector(花名选择),textArea,upload(上传)**/"dataType": "input",private String dataType;"format": null,"dataSource": null,"dataUrl": null,"required": null,"unit": null,"readOnly": false,"isHidden": false,"multiple": false,"features": null,"showTime": null,"maxLength": null}]
page 数据结构
public class McubePageBeanDTO {/*** 页面编码*/@CrmOperateLogBizCodeprivate String pageCode;/*** 业务线*/private String bizCode;/*** 配置类型*/private TemplateTypeEnum templateType;/*** 配置模块*/private List<McubeModuleBeanDTO> originalModules;/*** 配置字段*/private Map<String, List<McubeField>> originalFields;/*** 实例的模块*/private List<McubeModuleBeanDTO> instanceModules;private List<String> instanceModulesList;/*** 实例的字段*/private Map<String, List<McubeField>> instanceFields;private String subBizCode;/*** 元页面version*/private Byte originVersion;/*** 实例version*/private Byte instanceVersion;/*** module version*/private Byte moduleVersion;/*** 属性集合*/private List<Property> properties;///**// * 显示的模块// *///private List<String> instanceModulesList;private Boolean isCache;@Datapublic static class Property {/*** property*/private Boolean checkable;private Boolean isEdit;private Boolean selectable;private Boolean isLeaf;private Boolean isAdd;private Boolean isDelete;private String showType;private Integer level;private String extendedField;}}
page渲染运行时序图
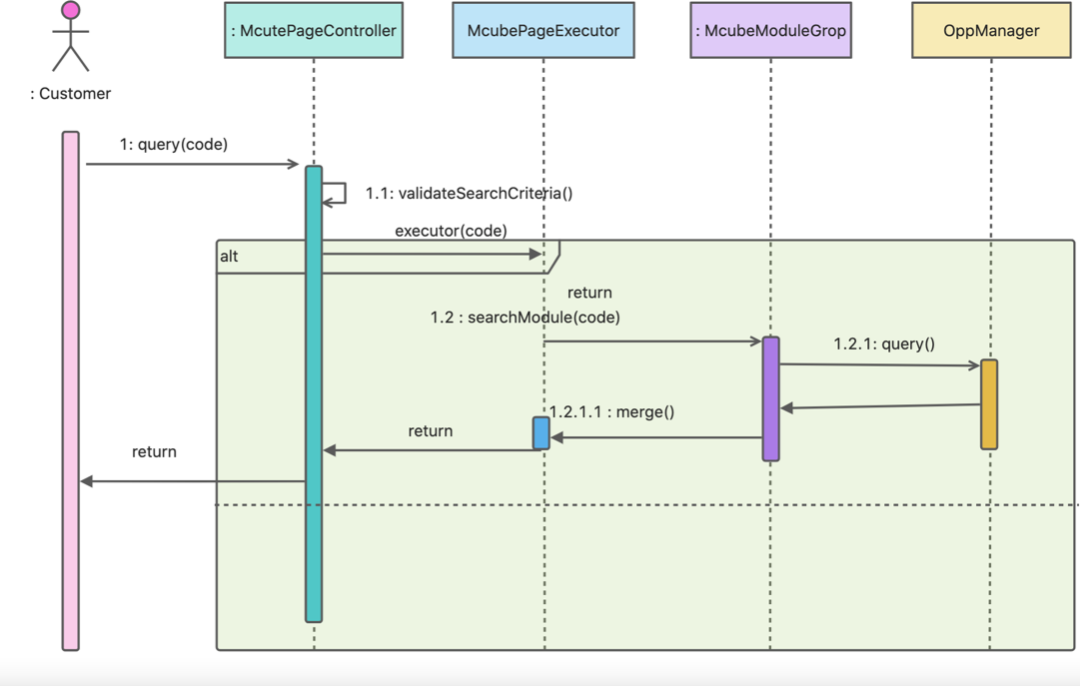
运行时类设计图
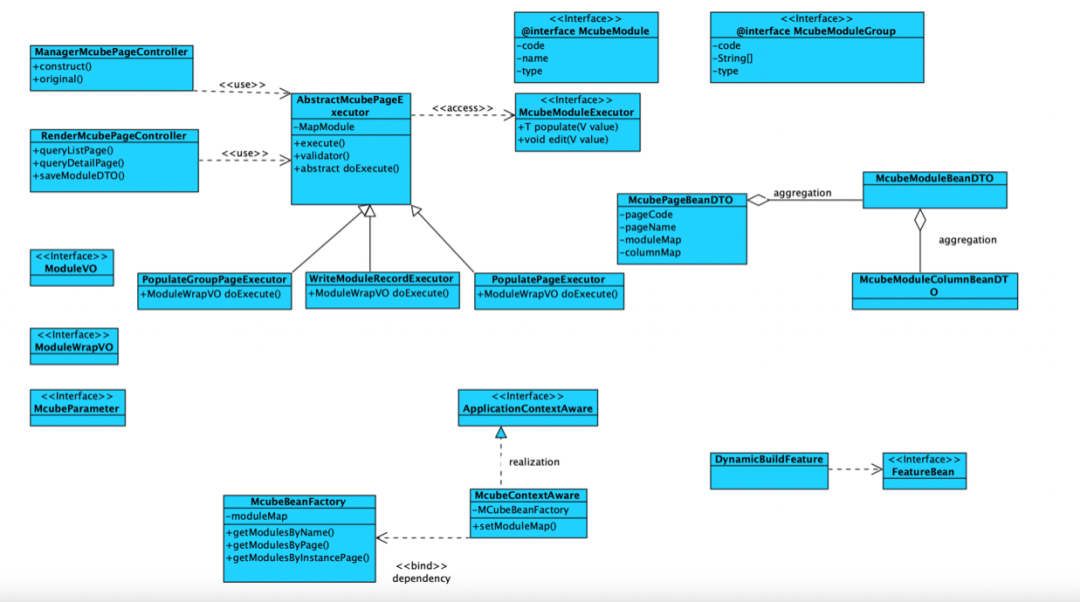
总结
阿里云产品评测—阿里云容器镜像服务 ACR
免费试用体验面向容器镜像、Helm Chart 等符合 OCI 标准的云原生制品安全托管及高效分发平台,发布你的评测更有机会获得千元机械键盘,限量定制礼品。
点击阅读原文查看详情。
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月24日
Arxiv
0+阅读 · 2022年11月23日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月24日
Arxiv
0+阅读 · 2022年11月23日