![]()
来源:Nature
编辑:小智、QJP
【新智元导读】在人工智能时代,NumPy可谓是家喻户晓。它是 Python 中最常用的数组编程库,在物理学、化学、工程学、金融和经济学等多个领域的研究分析中发挥着重要作用。近日,NumPy团队在Nature上发布了论文,回顾了NumPy的「前世今生」。「2020创新之源大会将于9月22日在中关村软件园召开,详细信息见文末海报,欢迎报名!」
NumPy是一个强大、紧凑和表达力强的语法来访问、操作和计算向量、矩阵和高维数组的科学计算库。
NumPy 是构建Python 科学计算生态系统的基础。一些有特定需求的项目已经开发了它们自己的类似 NumPy 的接口和数组对象。
由于其在生态系统中的核心地位,NumPy 越来越多地充当这些数组计算库之间的「互操作层」,并与其应用程序编程接口(API)一起提供了一个灵活的框架,以支持未来的科学计算和工业分析。
早在上世纪90年代还没有NumPy的时候,当时流行的是「Numeric」,它是基于C语言编写的,在Python中提供了数组对象和array-aware函数。它最早的用途之一是引导 C+ + 应用于劳伦斯利弗莫尔国家实验室的惯性约束聚变研究。
为了处理来自哈勃空间望远镜的大型天文图像,「Numarray 」重新实现了 Numeric,增加了对于结构化数组、灵活索引、内存映射、字节顺序变量、高效的内存使用、 IEEE 754标准错误处理以及更好的类型转换规则的支持。
尽管 Numarray 与 Numeric 高度兼容,但这两个软件包的差异已经足够让整个开发者社区分成两个派系。
而2005年 NumPy 的横空出世,成为了「两个世界中的最佳的统一」,它结合了 Numarray 的特性和Numeric 的small数组性能,同时也提供了丰富的C API。
15年后的今天,NumPy 支撑着几乎所有进行科学计算的 Python 库,包括 SciPy、Matplotlib、 pandas、 scikit-learn和 scikit-image等等。
NumPy 是一个社区开发的开放源码库,它提供了一个多维 Python 数组对象以及对其进行操作的array-aware函数。但由于其的简单易用的特性,NumPy array是 Python 中数组数据的实际上的交换格式。
NumPy 使用CPU对内存数组进行操作。为了利用现代化的、专门化的存储和硬件,最近几年出现了大量 Python 数组包。与 Numarray和Numeric 不同的是,这些新出现的库现在产生一些分歧,因为大量的工作都是构建在NumPy之上。
然而,为了向开发者社区提供新的和探索性的技术,NumPy 正在过渡到一种中央协调机制,这种机制指定一个定义良好的数组编程 API,并根据需要将其分配给专门的数组实现。
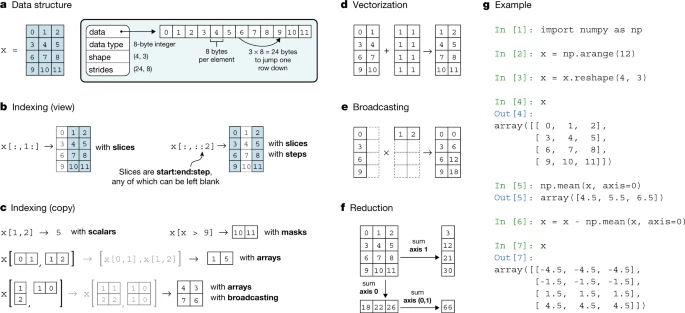
NumPy中的array是一种数据结构,可以有效地存储和访问多维数组(也称为张量) ,并支持各种科学计算。
它包括一个指针以及用于解释存储在其中的数据的元数据metadata,特别是「数据类型」、「形状」和「步长」。
数据类型data type用来描述存储在数组中的元素的性质。数组元素具有相同的数据类型,数组中的每个元素在内存中占用相同的字节数。数据类型包括实数、复数、字符串、时间戳和指向 Python 对象的指针等。
数组的形状决定了每个轴上的元素数量,轴的数量是数组的维数。例如,向量可以存储为一维数组,视频信息是形状为 (t,m,n,3) 的四维数组。
步长是要将线性存储元素的计算机内存解释为多维数组的必要条件,它描述在内存中向前移动的字节数,从一行跳到另一行,从一列跳到另一列等等。
例如,一个形状为(4,3)的二维浮点数组,其中每个元素在内存中占用8个字节,要在连续的列之间移动,我们需要在内存中向前跳转8个字节,并访问下一行,即3 × 8 = 24个字节。因此,该数组的步幅为(24,8)。
NumPy 可以按 C 或 Fortran 内存顺序存储数组,首先对行或列进行迭代。这也代表允许用这些语言编写的外部库直接访问内存中的 NumPy 数组数据。
用户使用「indexing」索引来访问子数组或单个元素、「operators」如,+ 、-和 × 用于向量化操作、「@」用于矩阵乘法,以及array-aware函数与 NumPy 数组进行交互;。
这些方法和操作一起为数组提供了易读、表达性强的高级 API,同时还可以通过底层来保证快速的运算。
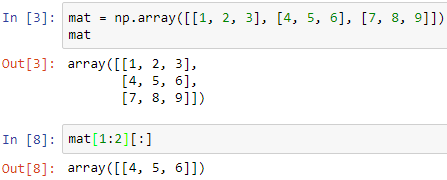
对数组进行索引和切片可以返回满足特定条件的单个元素、子数组等。数组甚至可以使用其他数组进行索引。检索子数组的索引将返回原始数组的“视图” ,这样两个数组之间就可以共享数据,这为在限制内存使用的同时对数组数据的子集进行操作提供了一种强大的方法。
为了补充数组语法,NumPy 对数组执行向量化计算的函数,包括算术、统计和三角图形学等。「矢量化」、「在整个数组而不是单个元素上操作」对于数组编程来说是必不可少的。
这意味着以往使用C语言需要数十行代码才能表示的操作通常可以使用一个简单清晰的Python表达式即可实现。这将产生简洁的代码,使得用户专注于他们分析的细节,同时NumPy还以近乎最优的方式处理数组元素循环。
在具有相同形状的两个数组上执行向量化操作时,应该发生什么是显而易见的。NumPy通过「广播」机制来允许维度不同的数组之间进行运算,并产生符合直觉的结果。例如可以把数组和标量进行相加,但是广播也可以推广到更复杂的例子,比如缩放数组的每一列或者生成坐标网格。
NumPy 还可以对数组进行其他一系列操作,如:reshape,concatenate,padding,search,sort,count等。它也为生成伪随机数提供了广泛的支持,并且可以使用一些后端来执行加速线性代数,比如 OpenBLAS或者 Intel MKL。
总而言之,NumPy在内存中的数组表示法,类似数学的语法,以及各种效用函数的组合形成了一个有效的和强有力的数组编程语言。
Python 是一种开源的、通用型的解释型编程语言,非常适合标准的编程任务,比如清理数据、与 web 资源交互以及解析文本等。加上快速的数组运算和线性代数,科学家们可以用一种编程语言来完成所有的工作。这种语言的优势在于易于学习和教学,许多大学将其作为主要学习语言就是明证。
尽管 NumPy 不是 Python 标准库的一部分,但是它受益于与 Python 开发者的良好关系。多年来,Python 语言增加了新的特性和特殊的语法,使得 NumPy 具有更简洁、更容易阅读的数组表示。但是,由于它不是标准库的一部分,因此 NumPy 能够指定自己的发布策略和开发模式。
SciPy 和 Matplotlib 与 NumPy 联系是非常密切的。SciPy 提供科学计算的基本算法,包括数学、科学和工程等。Matplotlib 则可以生成图形和可视化。
NumPy,SciPy 和 Matplotlib 的结合,加上先进的交互式环境,如 IPython或者 Jupyter,为 Python 中的数组编程提供了坚实的基础。
科学的 Python 生态系统建立在这个基础之上,提供了几个广泛使用的库,这些库反过来又构成了许多领域特定项目的基础。NumPy 是array-aware库生态系统的基础,它设置文档标准,提供数组测试基础设施,并增加对 Fortran 和其他编译器的构建支持。
许多研究小组设计了大型、复杂的科学计算的库,为生态系统增加了特定于应用程序的功能。例如,由EHT合作开发的用于射电干涉成像、分析和模拟的 eht-imaging 库,依赖于科学 Python 生态系统中许多较低层次的组件。
尤其是,EHT 使用这个库进行了第一次黑洞成像。在 eht-imaging 中,NumPy 数组用于存储和处理处理链中的每个步骤中的数字数据: 从原始数据到校准和图像重建。
SciPy 为一般的图像处理任务提供支持工具,如过滤和图像对齐,而 scikit-image 是一个扩展 SciPy 的图像处理库,提供更高级的功能,如边缘过滤器和 Hough 变换、优化模块执行最优化操作等。
NetworkX是一个用于复杂网络分析的软件包,用于验证图像比较的一致性。Astropy处理标准的天文文件格式并计算时间坐标转换。Matplotlib 用于数据可视化和生成黑洞的最终图像。
这个生态系统还提供了IPython 或Jupyter等 非常适合探索性数据分析的工具。用户可以流畅地检查、操作和可视化他们的数据,并快速迭代以优化编程语句。
这些语句被拼接成命令式或函数式程序,或者同时包含计算和叙述的Notebook。探索性工作的科学计算通常在文本编辑器或集成开发环境(IDE)(如 Spyder)中完成。这种丰富和高效的环境使 Python 在科学研究中受到欢迎。
近年来,数据科学、机器学习和人工智能的快速发展进一步大大推动了 Python 的科学应用。其重要应用的例子,如 eht 图像库,现在几乎存在于自然科学和社会科学的每一个学科。这些工具已经成为许多领域的主要软件环境。
NumPy和它的 API 一样已经变得无处不在
。
NumPy 在 CPU上提供内存中的多维均匀类型的数组。它可以在从嵌入式设备到世界上最大的超级计算机上运行,其性能接近编译语言。
然而,科学数据集现在经常超过单台机器的内存容量,可能存储在多台机器上或云端。此外,最近对加速深度学习和人工智能应用的需求导致了专门的加速器硬件的出现,包括GPU,TPU,FPGA等。
由于其内存中的数据模型,NumPy 目前无法直接利用这种存储和专用硬件。但是分布式数据以及 gpu、 gpu 和 fpga 的并行执行都很好地映射到了数组编程的模式: 因此现代硬件架构与利用其计算能力所需工具之间还存在着差距。
Commuinty为填补这一空白所做的努力导致了数组实现的激增。例如,每个深度学习框架都创建了自己的数组; PyTorch、 Tensorflow、 Apache MXNet和 JAX 数组都具有以分布式方式在 cpu 和 gpu 上运行的能力,它们使用延迟计算来支持额外的性能优化。
SciPy 和 PyData/Sparse 都提供稀疏数组,稀疏数组通常包含很少的非零值,并且只在内存中存储这些值以提高效率。
此外,还有一些项目将 NumPy 数组构建为数据容器,并扩展其功能。通过这种方式,Dask 使分布式数组成为可能。
这样的库通常会模仿 NumPy API,因为这降低了新用户进入的门槛,并且为更广泛的社区提供了一个稳定的数组编程/服务接口,同时反过来又防止了破坏性的分裂,比如 Numeric 和 Numarray 之间的分歧。
但是,探索使用数组的新方法本质上还处于试验阶段,事实上,一些库(如 Theano 和 Caffe)已经停止了发展。每当用户决定尝试新技术时,他们必须更改 import 语句并确保新库实现了他们当前使用的 NumPy API 的所有部分。
理想情况下,使用 NumPy 函数或语义在专门的数组上进行操作,可以简单地工作,这样用户就可以一次性编写代码,然后在 NumPy 数组、 GPU 数组、分布式数组等适当的数组之间进行切换,非常方便。
![]() NumPy 的API和数组协议向生态系统提供了新的数组
这些数组协议现在是 NumPy 的一个关键特性,预计只会越来越重要。NumPy 开发人员(其中许多人是本文的作者)反复改进和添加协议设计,以提高实用性和简化使用的方式。
NumPy 的API和数组协议向生态系统提供了新的数组
这些数组协议现在是 NumPy 的一个关键特性,预计只会越来越重要。NumPy 开发人员(其中许多人是本文的作者)反复改进和添加协议设计,以提高实用性和简化使用的方式。
NumPy最初是由学生、教职员工和研究人员开发的,目的是为 Python 提供一个先进的、开放源码的数组编程库,该库可以免费使用,不受许可证服务器和软件保护和加密的限制。
一开始只是尝试向 Python 添加一个数组对象,后来成为一个充满活力的生态系统的基础。现在,大量的科学工作依赖于 NumPy ,它不再是一个小型的社区项目,而是核心的科学基础设施。
新的设备将会被开发出来,现有的专业硬件将面临摩尔定律逐渐失效的情况。将会有更多的数据科学从业者使用 NumPy以外的工具。新一代语言、解释器和编译器,如 Rust55、 Julia56和 LLVM57,将创建新的概念和数据结构,来挑战NumPy的地位。
但不论如何,NumPy准备好了迎接这样一个不断变化的环境,并继续在交互式科学计算中发挥领导作用,不断满足下一个十年的科学计算需求。
https://www.nature.com/articles/s41586-020-2649-2
中关村软件园20周年,品牌活动“创新之源”大会再升级!
9月22日,2020创新之源大会 —“科技力量创变未来”在中关村软件园国际会议中心召开。大会由中关村软件园主办,中关村软件园孵化器、新智元、北京银行共同承办,邀请到清华大学副校长、北京量子信息科学研究院院长薛其坤院士,清华大学电子工程系主任、信息科学技术学院副院长汪玉,科大讯飞联合创始人、讯飞创投董事长徐景明,搜狗公司CEO王小川,网易集团副总裁、网易有道CEO周枫,达闼科技创始人兼CEO黄晓庆,浪潮信息副总裁、浪潮AI&HPC总经理刘军 ,腾讯自动驾驶业务中心总经理苏奎峰,新智元创始人兼CEO杨静等重磅嘉宾出席。
最新议程曝光,扫描二维码即刻报名,资格经审核后可免费参会!点击阅读原文,查看详细会议信息。








 NumPy 的API和数组协议向生态系统提供了新的数组
NumPy 的API和数组协议向生态系统提供了新的数组