作者:Terence Shin
机器之心编译
机器之心编辑部
想要成为一名合格的 AI 工程师,并不是一件简单的事情,需要掌握各种机器学习算法。对于小白来说,入行 AI 还是比较困难的。
为了让初学者更好的学习 AI,网络上出现了各种各样的学习资料,也不乏很多 AI 大牛提供免费的授课视频提供帮助。
近日,来自佐治亚理工学院的理学硕士 Terence Shin 在博客发布平台 Medium 撰文《2022 年你应该知道的所有机器学习算法》。文中涵盖了 5 类最重要的机器学习算法:集成学习算法;可解释算法;聚类算法;降维算法;相似性算法。
![]()
目前,Terence Shin 在 Medium 显示为 Top 1000 作者,有 62K 关注者,目前这篇文章已经有 1.4K 点赞。
![]()
为了理解什么是集成学习算法,你首先需要知道什么是集成学习。简单来讲,集成学习是一种同时使用多个模型以获得比单个模型性能更好的方法。
更形象的解释,我们以一个学生和一个班级的学生为例:
![]()
想象一下,一个学生解决一个数学问题 VS 一个班级学生解决相同的问题。作为班级,所有学生可以相互检查彼此的答案,并一致找出正确答案解决问题。另一方面,作为学生的个人,如果他 / 她的答案是错误的,那么没有其他人可以验证他 / 她的答案正确与否。
因此,由学生组成的班级类似集成学习算法,其中几个较小的算法协同工作以制定最终响应。
关于集成学习的更多信息请参考:https://towardsdatascience.com/ensemble-learning-bagging-and-boosting-explained-in-3-minutes-2e6d2240ae21
集成学习算法对于回归和分类问题或监督学习问题最有用。由于其固有的性质,它优于传统的朴素贝叶斯、支持向量机、决策树等机器学习算法。集成学习的代表方法有:Random Forests、XGBoost、LightGBM、CatBoost.
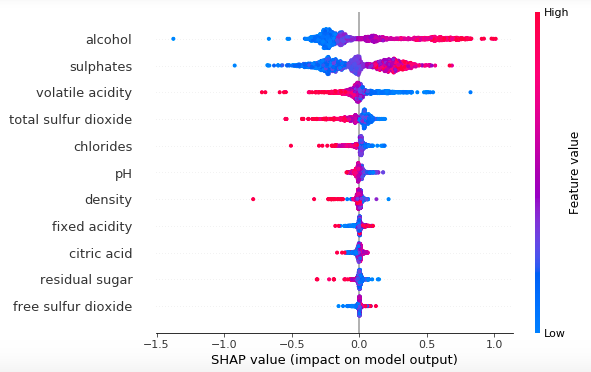
可解释算法帮助我们识别和理解与结果有显著关系的变量。因此,与其创建一个模型来预测响应变量的值,我们可以创建可解释模型来理解模型中变量之间的关系。
![]()
当你想要了解模型为什么做出这个决策、或者你想要理解两个或多个变量是如何相互关联的,可解释模型能够提供帮助。在实践中,解释机器学习模型能够实现的性能和机器学习模型本身一样重要。如果你不能解释一个模型是如何工作的,那么将不会有人愿意使用它。
目前基于假设检验的传统可解释模型主要包括:线性回归、逻辑回归;此外,可解释模型还包括 SHAP 和 LIME 这两种流行技术,它们被用来解释机器学习模型。
聚类是按照某个特定标准 (如距离) 把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
![]()
聚类的一般过程包括数据准备、特征选择、特征提取、聚类、聚类结果评估。
聚类算法可用于进行聚类分析,它是一项无监督学习任务,可以将数据分组到聚类中。与目标变量已知的监督学习不同,聚类分析中没有目标变量。
聚类能够发现数据中的自然模式和趋势。k-means 聚类和层次聚类是最常见的两种聚类算法。
数据降维算法是机器学习算法中的大家族,它的目标是将向量投影到低维空间,以达到可视化、分类等目的。
![]()
降维技术在很多情况下都很有用:在数据集中有数百甚至数千个特征并且用户需要选择少数特征时,需要用到降维;当 ML 模型过度拟合数据也需要降维,这意味着用户需要减少输入特征的数量。
目前已经存在大量的数据降维算法,可以从不同的维度进行分类。按照是否有使用样本的标签值,可以将降维算法分为有监督降维和无监督降维;按照降维算法使用的映射函数,可以将算法分为线性降维与非线性降维。其中,主成分分析 PCA、线性判别分析 LDA 为线性降维。
![]()
在机器学习中,我们经常需要知道个体间差异的大小,进而评价个体的相似性和类别。相似性算法是计算节点、数据点、文本对相似性的算法,如欧几里得距离,也有计算文本相似度的相似度算法,如 Levenshtein 算法。
相似性算法主要包括:K 近邻算法、欧几里得距离、余弦相似度、奇异值分解等。其中,K 近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 K 个实例,这 K 个实例的多数属于某个类,就把该输入实例分类到这个类中。欧几里得距离是欧几里得空间中两点间普通(即直线)距离。余弦相似度是通过计算两个向量的夹角余弦值来评估他们的相似度。
https://towardsdatascience.com/all-machine-learning-algorithms-you-should-know-in-2022-db5b4ccdf32f
基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。
DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com