只要一句话、一段文字,想让奥巴马说啥他就说啥
十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
“嘿!Siri,我能看看你的脸吗?”
“没问题,什么样的脸我都能给你呈现。”
不仅如此,现在还可以根据你自己的声音或是一段文字,再选择一张脸,就能让TA说话。
这个黑科技叫Neural Voice Puppetry,来自慕尼黑科技大学和马普所。

只要一句话,一段文字,随便一张脸就能说话
Neural Voice Puppetry是音频驱动的面部视频合成技术。
只要输入一段音频,就能根据它生成人物说话的视频,而且还十分逼真。
下图就是生成的奥巴马演讲视频,从嘴型到说话的神态都非常自然。

给出一段文字,也可以生成人说话的视频。

根据下面的这段文字,生成了美国四位总统的演讲视频,跟我们印象中他们说话的样子如出一辙。
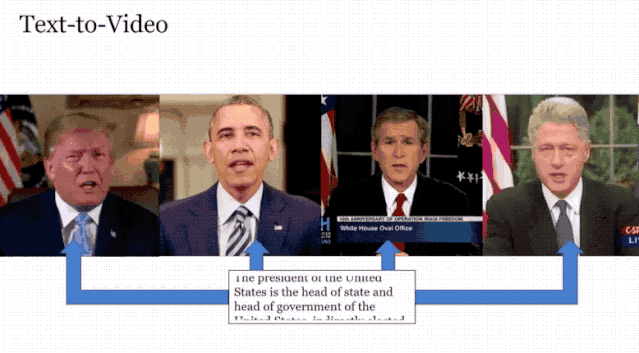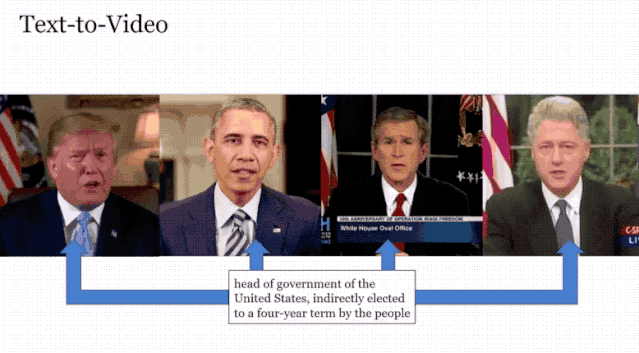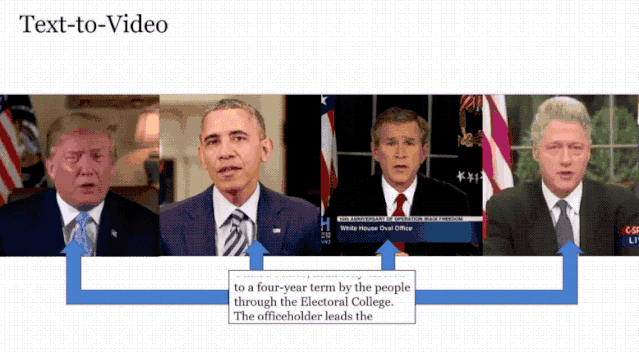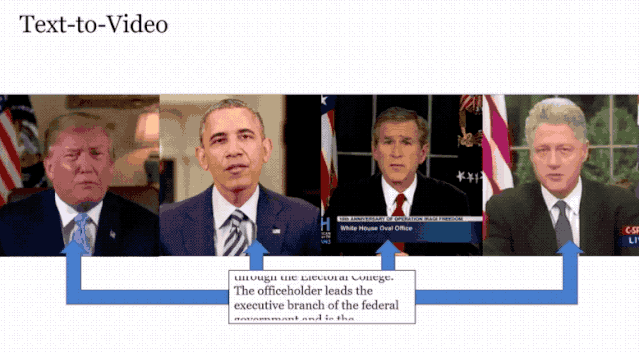
类似于这样的技术之前也是有过,但从效果和功能上看,Neural Voice Puppetry取得了一定的进步。
与最先进的基于音频驱动的面部视频合成技术相比,该方法能够适用于多个目标。

与VOCA相比,只需要一个3D代理(proxy)作为中间步骤,并没有对视频做特殊处理。

和基于2D的“You said that?”(基于GAN)方法相比,虽然它们不需要3D模型就可以工作,但作者的这项工作能够保证输出视频的3D一致性。
并且生成的是视频,而不是标准化的图像。

在人物表情非常扭曲的时候,输出的结果也是非常稳健的。

△观看文章开头视频效果更佳
不仅如此,还能对不同语言做处理。
什么原理?
为了实现根据一句话就能再现逼真的面部视频,研究人员采用3D面部模型作为面部运动的中间表示。
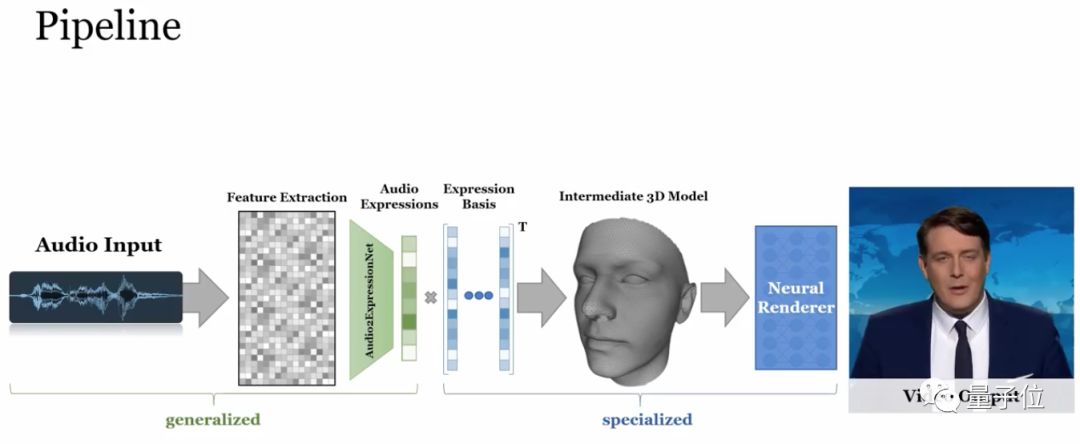
Neural Voice Puppetry的关键部分是基于声音的面部表情估计,采用了一个两阶段的过程。
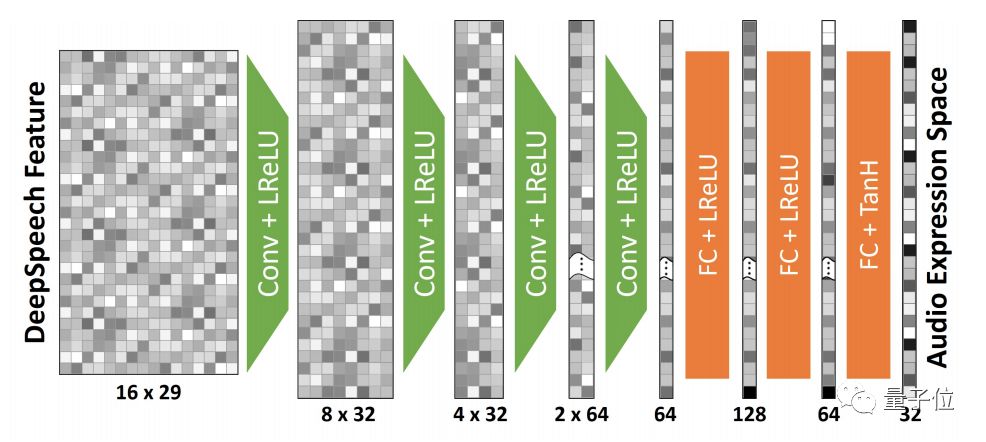
首先是Audio2ExpressionNet,根据DeepSpeech特征来估计每一帧的表征。
这个网络的输出是长度为32的音频表征向量。
这个音频表征是有时间噪声的,使用一个表征感知过滤网络进行过滤,该网络可以与每帧表征估计网络一起训练。
使用了5个核尺寸为3的一维卷积滤波器,将特征空间从32×8 、16×8、8×8、4×8、2×8到1×8依次缩小。
其次是Rendering network。
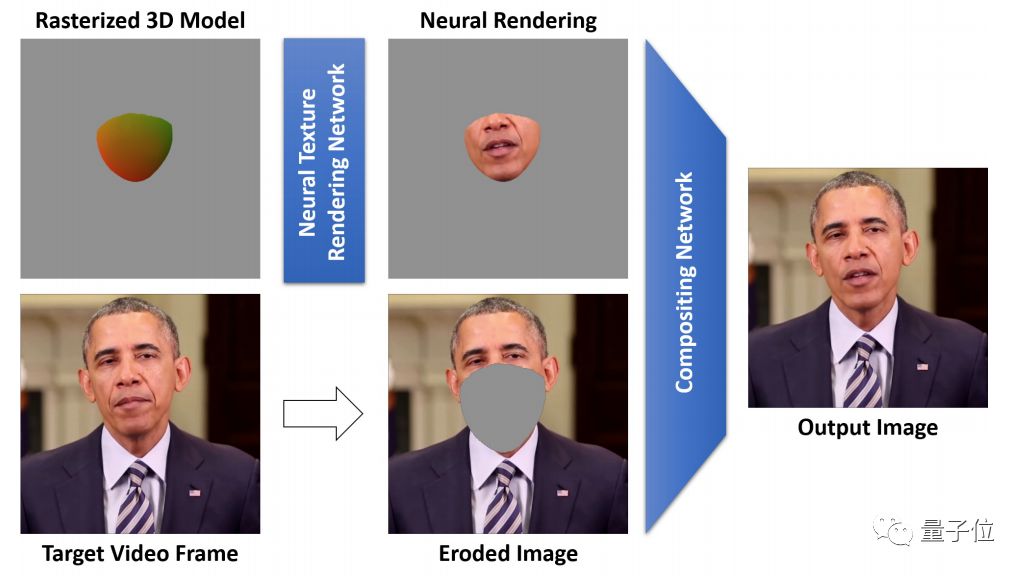
基于驱动人脸模型的表情预测,对目标视频图像空间进行神经纹理处理。
这一步包括两个网络。第一个网络用于将从神经纹理中采样的神经描述符转换为RGB颜色值。第二个网络将此图像嵌入到目标视频帧中。
最后,采用了一种新的延迟神经渲染(deferred neural rendering)技术来生成最终的输出图像。
下一步工作
虽然Neural Voice Puppetry对不同的音频源和目标视频效果很好,但它仍然有局限性。
特别是在音频流中有多个声音的情况下,该方法会失效。
另外还有一个局限性是谈话风格较为固定。
因为研究人员假设目标参与者在一个目标序列中的谈话风格是不变得。
在后续的工作中,研究人员计划从语音信号来估计说话风格,以此来控制面部动作的表现力。
团队介绍

△Justus Thies
Justus Thies,慕尼黑工业大学视觉计算组的博士后。2017年,获得埃尔朗根-纽伦堡大学的博士学位,主要研究面部表情的无标记运动捕捉及其应用。近期专注于神经图像合成技术,允许视频编辑和创作。工作领域结合了计算机视觉、机器学习和计算机图形学视觉。

△Mohamed Elgharib
Mohamed Elgharib,马普所计算机图形学部分。主要研究领域包括可视真实感渲染、3D重建及视频后期制作等。

△Ayush Tewari
Ayush Tewari,马普所计算机图形学部门。

△Christian Theobalt
Christian Theobalt,马普所图形、视觉和视频研究小组组长,沙尔大学计算机科学教授。

△Matthias Nießner
Matthias Nießner,慕尼黑工业大学教授,可视化计算小组。研究领域包括计算机视觉、图形学和机器学习的交叉领域。对3D 重建、语义3D 场景理解、视频编辑和人工智能驱动的视频合成等尖端技术特别感兴趣。
传送门
论文地址:
https://arxiv.org/pdf/1912.05566.pdf
— 完 —
大咖齐聚!量子位MEET大会精彩回放
量子位 MEET 2020 智能未来大会精彩回放来袭!李开复、倪光南、景鲲、周伯文、吴明辉、曹旭东、叶杰平、唐文斌、王砚峰、黄刚、马原等AI大咖与你一起读懂人工智能。扫码观看回放吧~ ~

跟大咖交流 | 进入AI社群


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



