十个有用的软件开发原则

我总结了一些软件开发原则。在这些原则中,大多数都是以简化系统为核心。在我看来,简单的系统会更可靠,更容易修改,而且一般更容易使用。当观念发生改变时,我希望更新它们。
我把这一点排第一,是因为我认为它是最重要、最强大的原则之一。
你可能在定义类型时听到过这个词,但其实这个原则适用于所有与表示数据相关的地方——例如数据库设计。
它不仅可以减少系统的状态数量(从而变得更简单),还能减少无效状态的数量!你的系统不需要处理这些无效状态,因为它们在你的程序中实际上是不可表示的。
这不只是一个小技巧,它可以极大简化你的系统,并防止出现各种类型的 bug。这有一些例子。
https://kevinmahoney.co.uk/articles/applying-misu/
对数据施加一致性规则,减少了系统需要处理的状态数量。这是从上一个原则派生而来的。
这里说的是一致性的普遍含义:即数据遵循某些规则,并且在任意时刻都始终遵循这些规则。这一定义与 ACID 有关,但不要与 CAP 混淆起来了。
规则可以是任何东西,例如,你的信用永远不能变成负数,或者私密的帖子不应该被其他人看到。它不仅限于外键或惟一索引,尽管它们也是有效的规则。
和数据库一样,应用程序也可以通过使用 ACID 事务来加强一致性。如果能在数据库级别强制保持一致性是最好的,但在实际中,对稍微复杂一点的东西来说,这样做并不常见。
任何限制或损害一致性的行为都会导致复杂性。这就引出了以下这些实用的建议:
让系统更简单:
更少的数据库 (理想情况下是一个)
规范化,减少冗余数据
一个“好的”数据库设计
ACID 事务
更多的数据约束
让系统更复杂:
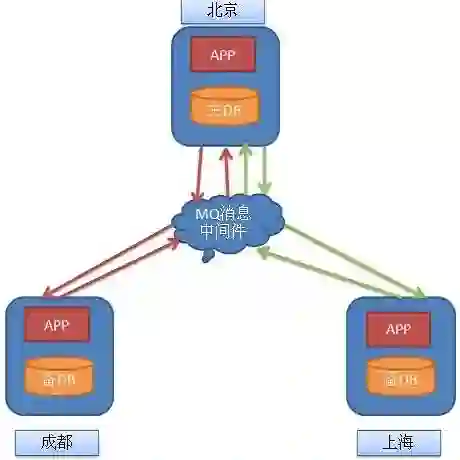
多个数据库
冗余或非正规化数据
糟糕的数据库设计
较少(或没有)数据约束
当然,有时候让系统变复杂也是有正当理由的,我并不想让复杂性变成一个“肮脏的”词。请参阅后面的一个原则“杀鸡不要用牛刀”。
我认为这个原则是当今软件工程中最被低估的原则之一。一致性问题经常被忽视。很多问题,我敢说大多数问题,基本上都是一致性问题——数据不符合某些期望。
参见附录,了解不一致性是如何导致复杂性的。
https://kevinmahoney.co.uk/articles/my-principles-for-building-software/#appendix-a-inconsistency-results-in-complexity
这个问题,“代码还是数据?”,哪一个在 10 年后更有可能继续存在。
代码可以被丢掉重写,但数据很少会这样。
数据比代码更重要。代码的唯一目的是转换数据。
在设计新系统时,最好先从数据库和数据结构开始,并在此基础上开发代码。要考虑可以在数据上施加的约束并实施它们,理想情况下是通过表示数据的方式进行的。
代码设计是数据设计的下一步。数据模型越简单、越一致,代码就会越简单。
你们把流程图给我看,但把表藏起来,我就一头雾水。你们把表给我看,通常我就不需要你们的流程图,它们会不言自明。—— Fred Brooks
糟糕的程序员关心代码。好的程序员关心数据结构和它们之间的关系。—— Linux 之父 Linus Torvalds
这是软件开发人员最常犯的错误。
这个原则是说,当你在做需要付出复杂性代价的权衡时,要确保权衡的必要性得到经验证据的支持。
常见错误:
试图构建一个复杂的“可伸缩”系统,可以伸缩到你可能永远都不需要的规模。
在不考虑需求或成本的情况下,让服务尽可能地小。
在非性能瓶颈的地方优化性能,增加不一致性或复杂性。
建议:
尽可能从最简单、最正确的系统开始
对性能进行度量
如果不能解决实际问题,就不要付出复杂性代价或违反其他原则。
有些优化可以不进行度量,因为它们的成本非常低或为零。例如,为了保证你想要执行的操作具有你想要的性能,使用正确的数据结构。
的确,有时候经验本身就能告诉你是否做出了正确的权衡。但如果你能证明,那就更好了。
当你必须做出选择时,请选择正确性和简单性,而不是性能。
在某些情况下,正确而简单的代码是性能最好的代码!
真正的问题是程序员在错误的地方和错误的时间花了太多的时间在担心效率上。过早优化是编程中所有(或者至少是大部分)罪恶的根源。——计算机科学家 Donald Knuth
也就是避免为了让系统的一部分变得更简单,而导致整个系统变得更复杂。
这种交换通常是不平等的。追求局部的简单性会导致全局复杂性的增加,而且是数量级的。
例如,使用较小的服务可以让这些服务变得更简单,但一致性的降低和对更多进程间通信的需求让系统变得更加复杂。
有时候事情本身就很复杂,你不能把问题简单化。
任何这样的尝试都只会让系统变得更加复杂。
深入理解一小部分技术要比只是表面理解很多技术好。
更少的技术意味着更少的东西要学习和更少的运维复杂性。
不要太关心技术的复杂细节,因为你可以随时查阅它们。你要学习底层的基本概念。
技术会变化,概念却是永恒的。你学到的概念将被用在更新的技术中,你就可以更快地学会新技术。
例如,不要太关注 React、Kubernetes、Haskell、Rust 的表面细节。
重点学习:
纯函数式编程
关系型模型
规范的方法
逻辑编程
代数数据类型
类型类 (通用的和特定的)
借位检查器 (仿射 / 线性类型)
依赖类型
Curry-Howard 同构
宏
同像性(Homoiconicity)
VirtualDOM
线性回归
......
有时候,具有一致性的代码比“正确”的代码更重要。如果你想要改变代码库中某些代码的行为,就要修改它所有的实例。否则的话,就只能忍受。
代码的可读性更多地与一致性(而不是简单性)有关。人们通过模式识别来理解代码,所以请重复 (和记录) 模式!
如果你和队友之间的共同原则越多,就能越好地在一起工作,而且你会越喜欢和他们在一起工作。
这是我能想到的最简单的例子,希望能毫不费力地与现实问题联系起来。
假设一个数据库有两个布尔变量 x 和 y,你的应用程序有一个规则,即 x = y,可以通过使用一个事务修改这两个变量来执行这个规则。
如果这个规则被正确执行,那么数据只有两种状态:(x = True,y = True) 或 (x = False,y = False)。
基于这个规则的函数“toggle”就非常简单。你可以读取其中一个值,并将两个值都设置为反向值。
现在,假设你将这两个变量放到不同的数据库中,并且不能再被一起修改,那么会发生什么?
因为你不能确保 x = y 的一致性,所以数据可以有两种以上的状态:(x = True,y = False) 或 (x = False,y = True)。
如果你的系统处于这些状态中的一种,你应该使用哪个值?
当处于其中的一种状态时,“toggle”函数的行为是怎样的?
在写入新值时,如何确保两次写入都成功?
这些问题没有正确的答案。
当然,如果我们一开始就遵循“剔除无效状态”的原则,那么将只有一个变量!
原文链接:
https://kevinmahoney.co.uk/articles/my-principles-for-building-software/
InfoQ 写作平台欢迎所有热爱技术、热爱创作、热爱分享的内容创作者入驻!
还有更多超值活动等你来!
扫描下方二维码
填写申请,成为作者


点个在看少个 bug 👇