初创公司如何训练大型深度学习模型

本文最初发表于 AssemblyAI 网站,经原作者 Dylan Fox 授权,InfoQ 中文站翻译并分享。
OpenAI 的 GPT-3 是一个令人印象深刻的深度学习模型,但是它有 1750 亿个参数,相当占用资源。尽管有不同的估计,但是这种规模的模型在一个 GPU 上的训练需要数百年。
幸好 OpenAI 有一个由微软提供的 NVIDIA V100 GPU 的高带宽集群,这让 OpenAI 可以在几个星期而不是几年内就能训练 GPT-3。这个集群到底有多大?根据本文所述,在 1024 个 NVIDIA A100 GPU 上训练 GPT-3 大约需要 34 天。
这个 GPU 的数量真是令人难以置信。每张 A100 GPU 的售价为 9900 美元,而我们讨论的是构建这样一个庞大的集群需要花费将近 1000 万美元。我们甚至还没有考虑到电力成本,或者你实际上必须安装 GPU 的服务器机架,或者维护这种类型的硬件的人力成本,以及其他成本。
如今,你可以从谷歌云这样的公有云提供商那里租用 A100 GPU,但按每小时 2.933908 美元计算,运行 1024 张 A100 GPU 34 天,加起来需要 2451526.58 美元。请记住,这个价格是针对单一的训练运行的价格。
我可以继续说下去,但问题是,训练大型模型既昂贵又缓慢。在 AssemblyAI,我们没有训练 1750 亿个参数范围内的模型(谢天谢地),但是我们的语音识别模型是非常庞大的 Transformer,正在快速接近 10 亿个参数。作为一家初创公司,速度和成本是我们必须不断优化的两件事。
这个问题的主要解决方法是在更多的 GPU 上训练模型,但是这需要很高的成本,往往是初创公司无法承受的。近几年来,我们学到了一些关于大型模型训练的经验,希望与大家分享。
在 AssemblyAI,我们构建了大型、准确的自动语音识别(Automatic Speech Recognition,ASR)模型,并通过简单的 语音到文本的 API 进行公开。开发人员使用我们的 API 来开发应用,来实现转录电话、Zoom 视频会议、播客、视频以及其他类型的媒体内容。
我们性能最好的自动语音识别模型是大型 Transformer,在 48 张 V100 GPU 上需要大约 3 周的时间来训练。

为什么我们这个模型的训练需要如此长的时间和如此多的 GPU?主要原因有三个:
计算出每隔 10 毫秒左右的一个音频文件的声谱图,并将其作为神经网络的输入特征。声谱图的形状 / 尺寸取决于音频数据的采样率,但是如果采样率是 8000 赫兹,那么声谱图中的特征数将是 81。如果是一个 16 秒的音频样本,它的形状会是 [1600, 81],这是一个相当大的特征输入!
下面是声谱图作为矩阵的一个例子:
[[[-5.7940, -5.7940, -4.1437, ..., 0.0000, 0.0000, 0.0000],[-5.9598, -5.9598, -4.2630, ..., 0.0000, 0.0000, 0.0000],[-5.9575, -5.9575, -4.2736, ..., 0.0000, 0.0000, 0.0000],...,[-4.6040, -4.6040, -3.5919, ..., 0.0000, 0.0000, 0.0000],[-4.4804, -4.4804, -3.5587, ..., 0.0000, 0.0000, 0.0000],[-4.4797, -4.4797, -3.6041, ..., 0.0000, 0.0000, 0.0000]]],[[[-5.7940, -5.7940, -5.7940, ..., 0.0000, 0.0000, 0.0000],[-5.9598, -5.9598, -5.9598, ..., 0.0000, 0.0000, 0.0000],[-5.9575, -5.9575, -5.9575, ..., 0.0000, 0.0000, 0.0000],...,[-4.6040, -4.6040, -4.6040, ..., 0.0000, 0.0000, 0.0000],[-4.4804, -4.4804, -4.4804, ..., 0.0000, 0.0000, 0.0000],[-4.4797, -4.4797, -4.4797, ..., 0.0000, 0.0000, 0.0000]]],[[[-5.7940, -5.7940, -5.7940, ..., 0.0000, 0.0000, 0.0000],[-5.9598, -5.9598, -5.9598, ..., 0.0000, 0.0000, 0.0000],[-5.9575, -5.9575, -5.9575, ..., 0.0000, 0.0000, 0.0000],...,[-4.6040, -4.6040, -4.6040, ..., 0.0000, 0.0000, 0.0000],[-4.4804, -4.4804, -4.4804, ..., 0.0000, 0.0000, 0.0000],[-4.4797, -4.4797, -4.4797, ..., 0.0000, 0.0000, 0.0000]]]
对于基于 Transformer 的神经网络,更大的网络通常会更好。很多论文都支持这一观点,其中 GPT-3 是最流行的例子。无论是在研究社区,还是在我们自己的内部研究中,我们都发现这种趋势同样适用于自动语音识别模型。
我们性能最好的模型是一个大型 Transformer,它包含近 5 亿个参数。随着参数的增加,在反向传播过程中,梯度更新所需要的计算能力就越大。神经网络的训练基本上可归结为进行一堆矩阵运算。模型中的参数越多,矩阵就越大。大型矩阵需要更多的计算和 GPU 内存资源。
大型模型具有更强的建模能力,这要归功于其参数数量的增加,为了充分利用这种建模能力,我们在近 10 万小时的已标记的语音数据上对模型进行。举例来说,GPT-3 是在 45TB 的文本数据上训练的,它也可以视为 1099511626800 字左右的文本。
训练神经网络时,需要对数据集进行多次迭代(每次迭代都被称为“轮数”)。数据集越大,每次迭代或“轮数”的时间就越长。即使提前停止,在一个大的数据集上训练一个大的模型,进行 20~50 次的迭代,也会花费很多时间。
初创公司面临着一项艰巨的任务:在短期内取得重大进展。被誉为“突围型”的初创公司通常都会在最短的时间内取得最大进步。
对于一家刚起步的深度学习公司来说,这是一个艰难的挑战。如果你的模型需要 3~4 个星期进行训练,你是如何快速迭代的?
减少训练时间的最简单方法是在更多的 GPU 上训练模型。更多的 GPU 意味着可以使用更多的 GPU 内存来训练运行。例如,假设你可以在一个 GPU 上安装大小为 8 的 mini-batch。如果数据集中有 1000 个样本需要迭代,这意味着需要迭代 125 个 mini-batch(每个大小为 8)。如果每次迭代需要 1 秒,那么就需要 125 秒来迭代所有 125 个 mini-batch。
如果你有 4 个 GPU,你可以一次并行地迭代 4 个 mini-batch,而不是 1 个 mini-batch。这就是说,要完成所有 125 个 Mini-batch,只需要 32 次迭代。假定每一次迭代在 4 个 GPU 上花费 1.5 秒,这是因为 4 个 GPU 有额外的通信开销——然而,你仍然能够在 48 秒内迭代完整个数据集(32*1.5)。这个速度几乎是单个 GPU 的 3 倍。
不过,值得注意的是,更大的批量(batch)并不总是等同于更快的训练时间。如果你的有效批量大小过大,你的模型的总体收敛性将开始受到影响。选择适当的批量大小来训练是你必须试验的一项超参数,目前正针对不同的优化器(例如 LAMB 和 LARS)进行研究,这些优化器有助于缓解过大的批量大小损害收敛性的问题。
训练的 GPU 越多,通信的开销就越大。因此,在 8 个 GPU 上训练的速度并不会比在单个 GPU 上训练快 8 倍。在 AssemblyAI,我们使用 Horovod 来管理跨多个 GPU 上的分布式训练运行。Horovod 是一个很棒的库,当你在训练集群中增加更多的 GPU 时,它可以帮助你获得更高的效率。
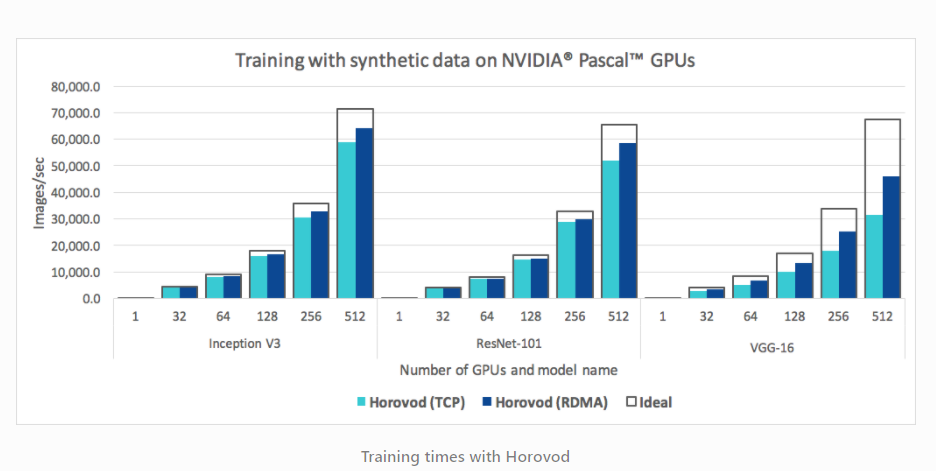
在测试中,我们发现 Horovod 速度大大快于 DistributedTensorFlow 和 PyTorch DistributedDataParallel。尽管如此,PyTorch 还是在积极地开发,并在快速改进。在我们的测试中,我们发现 PyTorch DistributedDataParallel 在单台服务器上与 Horovod 相当,但是当扩展训练运行到多个服务器时(例如,4 个服务器,每个有 8 个 GPU),Horovod 的性能更好。
大多数模型默认是使用 FP32(浮点值 32,也称为单精度)进行训练。使用半精度(FP16)或混合精度进行训练,也可以加快训练时间。
FP16 张量是 16 位,或 2 个字节,其中每个位是 0 或 1,如 010101 10101010。FP32 张量是 32 位,或 4 字节,如 11110000 00001111 11001100 00110011。
训练期间更低的精度意味着更少的字节,这意味着在训练期间中需要的 GPU 内存更少,需要的带宽也更少,而且实际硬件级操作在较新 GPU 上运行得更快,所有这些都加快了训练速度。
使用 PyTorch,下降到 FP16 是比较容易做到的,例如 x = x.half 将一个 FP32 张量下降到 FP16。不过,要记住的是,在实践中训练的精确度较低,而且并不总是像在公园里散步那么简单。某些操作或自定义损失函数可能不支持较低的精度,可能需要大量的超参数调整,以使你的模型在 FP16 下收敛,而且较低的精度也可能会影响模型的总体精度。
这很简单:不要使用像 AWS 或谷歌云那样的公有云。这样做似乎是最简单的开始方法,但是成本会迅速增加,尤其是与下面的选择相比。
如果你对管理自己的硬件感到满意(我们不推荐这么做),那么购买诸如 NVIDIA TITAN X 之类的消费级 GPU 是一个比较便宜的选择。举例来说,每张 TITAN X 的价格大约为 3000 美元,作为消费级 GPU,其性能出乎意料的好。如果你有能力建造自己的设备,走这条路只需支付一次硬件费用,但同时也要承担托管和维护训练设备的麻烦。
一些公司如 Lambda 等,可以为你提供相对廉价的定制训练设备。例如,一台配有 4 个 NVIDIA RTX A5000 和 NVLink 的机器大约需要 16500 美元。这包括内存、处理器、外壳等。你所要做的就是找个地方插上电源,然后支付你的电费。
在 AssemblyAI,我们从 Cirrascale 租用专用服务器。像 Cirrascale 这样的提供商有很多,但支付专用服务器的费用要比像 AWS 或谷歌云这样的大型公有云好得多。这个选择还使你能够自定义你所需的内存和处理器规格来定制你的机器,并为你选择 GPU 提供更大的灵活性。
比如,AWS 仅提供以下 GPU:
NVIDIA Tesla M60 GPUs
NVIDIA A100
NVIDIA Tesla V100
NVIDIA K80 (these are horrible) 而 Cirrascale 公司提供的 GPU 种类繁多,比如 P100s、V100s、A100s、RTX 8000s 等。
很多时候,你并不需要最昂贵的 GPU 卡(现在的 A100)来在合理的时间内训练你的模型。而且,最新、最好的 GPU 通常不会立刻被 PyTorch 和 TensorFlow 等流行框架所支持。举例来说,NVIDIA A100s 在得到 PyTorch 的支持前就等了一段时间。
相对于大型公有云,如 AWS 或谷歌云,能够根据你的训练需求和预算定制一台机器,对于与小型托管服务提供商合作是一个巨大的优势。另外,由于你租用的是一台完整的物理机器,而非 AWS/ 谷歌云平台那样的虚拟化机器,因此实际的机器整体性能要好得多。
总之,训练大型深度学习模型是许多初创公司都必需要面对的挑战。成本可能很高,迭代时间也可能很慢,而且如果你不小心,它们会严重影响你的创业进程。
原文链接:
https://www.assemblyai.com/blog/how-to-train-large-deep-learning-models-as-a-startup/
今日好文推荐
离职 Oracle 首席工程师怒喷:MySQL 是“超烂的数据库”,建议考虑 PostgreSQL
计算机架构史上的一次伟大失败,多数人都不知道
滴滴启动美股退市;阿里股价跌回2017年;Linus吐槽桌面版Linux:乱改核心,程序兼容性太糟糕 | Q资讯
这个重要开源项目全靠一位低调的“怪老头”维护!他和比尔盖茨一样撑起了计算机世界
InfoQ 100 位优质创作者签约计划第二季火热进行中!欢迎各位同学踊跃报名~ 签约豪华大礼包、专属身份标志、百万流量扶持等好礼,等您来拿!
活动链接:http://gk.link/a/10KyO

点个在看少个 bug 👇



