将因果关系估计引入推荐系统、提升推荐模型效果,快手新研究被WWW22接收
机器之心编辑部
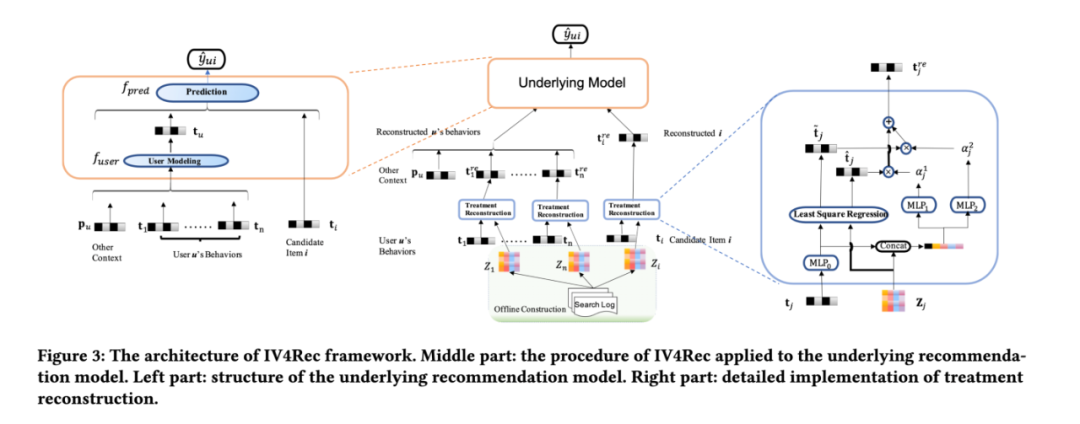
本文中,研究者提出了一个基于工具变量的模型无关的因果学习框架 IV4Rec,从而利用搜索数据辅助推荐模型。该框架将搜索的 query 作为 IVs 来将推荐系统中的 embedding 分解为因果和非因果的部分,再将它们联合起来探索不同机制对于推荐结果的影响。此外,IV4Rec 将传统的 IVs 的方法和深度学习结合,提供了一个端到端的框架来学习模型的参数。研究者在快手短视频数据集和公开数据集 MIND 上的实验验证了该框架的有效性。

论文链接:https://arxiv.org/abs/2202.04514
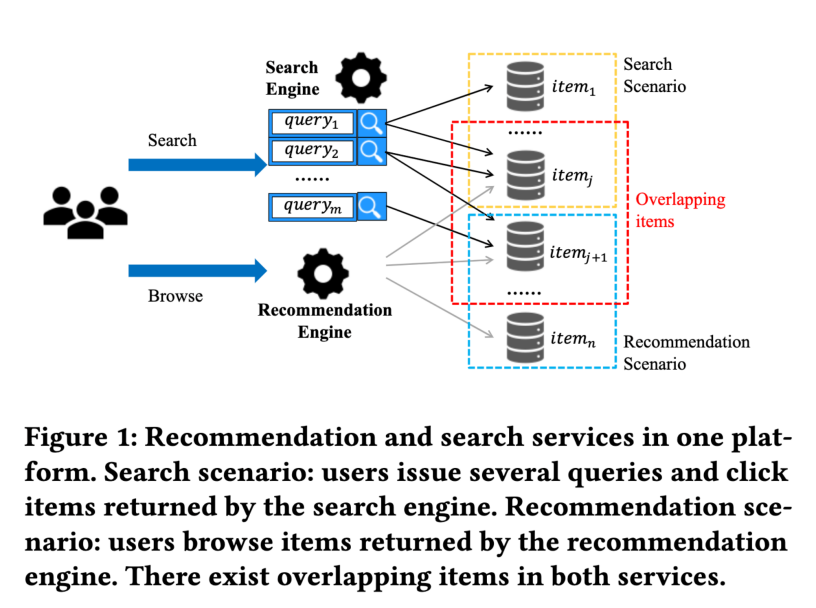
现有搜索推荐联合的模型与方法并没有从深层次发掘和利用搜索行为与推荐模型之间的因果关系;
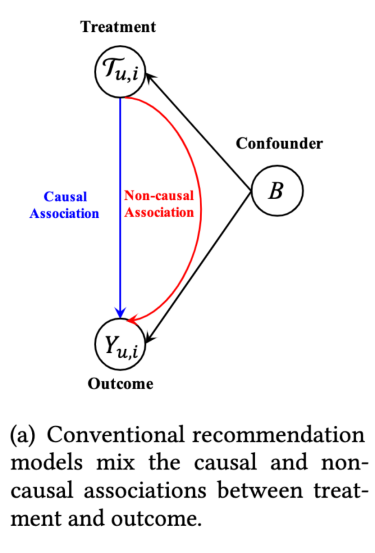
现有推荐模型普遍没有考虑到训练过程中产生的各种 bias,多种 bias 组成的 confounder 会影响模型的训练。
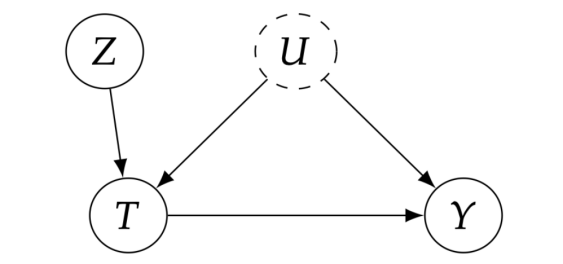
 ,再用
,再用
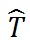 回归 Y,
回归 Y,
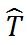 回归 Y 得到的关系就可以认为是 T 和 Y 之间的因果关系。
回归 Y 得到的关系就可以认为是 T 和 Y 之间的因果关系。
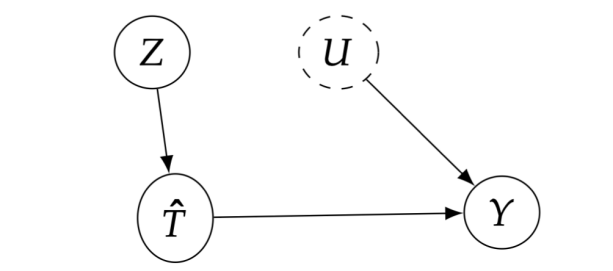
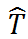 ,根据 IVs 的理论,
,根据 IVs 的理论,
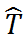 和 Y 之间的关系代表了 T 和 Y 之间的因果关系。
并且,他们用 T -
和 Y 之间的关系代表了 T 和 Y 之间的因果关系。
并且,他们用 T -
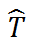 得到残差
得到残差
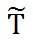 ,并认为
,并认为
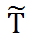 和 Y 之间代表了 T 和 Y 之间的非因果关系。
传统的因果推荐应用中,主要目的是探究因果关系而不是预测准最终的 Y,所以通常会直接移除残差
和 Y 之间代表了 T 和 Y 之间的非因果关系。
传统的因果推荐应用中,主要目的是探究因果关系而不是预测准最终的 Y,所以通常会直接移除残差
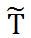 。
。
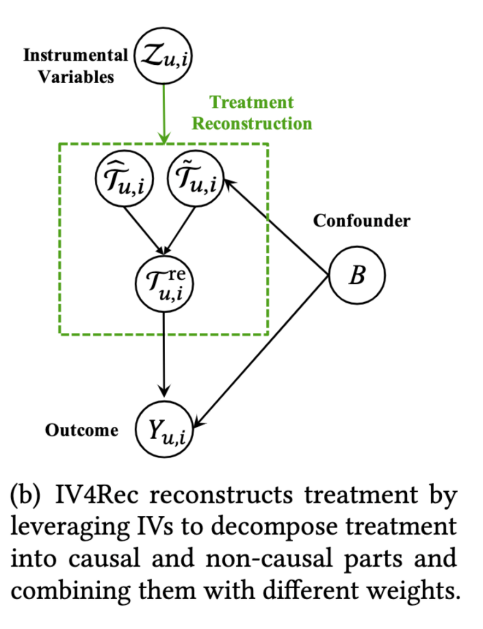
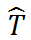 和
和
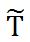 的权重,两个网络结构相同,输入均为
的权重,两个网络结构相同,输入均为
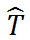 和
和
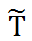 的 concatenation。
的 concatenation。
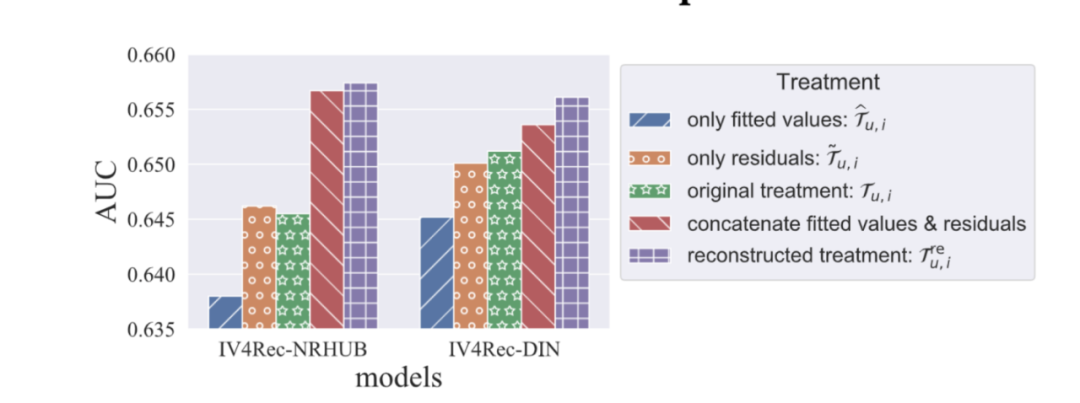
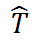 ;
只使用残差
;
只使用残差
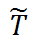 ;
不用 reconstruction module,直接使用原本的 treatment;
使用重构的 treatment 通过 concatenate
;
不用 reconstruction module,直接使用原本的 treatment;
使用重构的 treatment 通过 concatenate
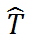 和残差
和残差
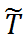 ;
使用 IV4Rec 中方式重构的 treatment。
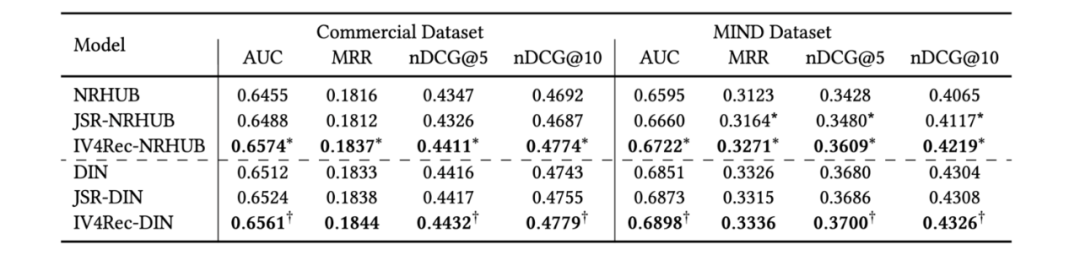
可以发现当两个部分被联合到一起的时候,AUC 提升了很多。
这种现象同时发生在 NRHUB 和 DIN 上,这说明了残差也可以提升用户偏好的预测,因为残差仍然和最终的 Y 有很强的相关关系。
当目标是做出准确的预测而不是分析因果关系时,
;
使用 IV4Rec 中方式重构的 treatment。
可以发现当两个部分被联合到一起的时候,AUC 提升了很多。
这种现象同时发生在 NRHUB 和 DIN 上,这说明了残差也可以提升用户偏好的预测,因为残差仍然和最终的 Y 有很强的相关关系。
当目标是做出准确的预测而不是分析因果关系时,
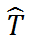 和
和
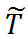 是互补的两个部分。
是互补的两个部分。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
专知会员服务
101+阅读 · 2020年6月28日
Arxiv
20+阅读 · 2021年5月27日



相关VIP内容
专知会员服务
101+阅读 · 2020年6月28日
相关资讯
相关论文
Arxiv
20+阅读 · 2021年5月27日