GitHub获星3.3K,为什么Prompt在NLP任务中更有效?
大家好,我是图与推荐的小编。
AI领域的工作突破通常有三类:
屠爆了学术界榜单,成为该领域学术层面的新SOTA
实现了大一统,用一个架构实现对该领域诸多子任务的统一建模,刷新建模认知
将NB的学术界新SOTA变成一件人人可傻瓜式使用的开源工具利器,带领该领域大规模落地开花
要单独实现其中的任何一点,都是一件很有挑战的事情。如果我说,在信息抽取领域,不久前的一个工作同时做到了这三种突破呢?

这次,小编倒着讲。
先讲第三点——
一个刷新认知的信息抽取开源工具

信息抽取是一个行业应用价值很高的技术,却因为任务难度大,落地成本居高不下。
像金融、政务、法律、医疗等行业,有大量的文档信息需要人工处理,比如政务人员处理市民投诉,工作人员需要从中快速提取出被投诉方、事件发生地点、时间、投诉原因等结构化信息,非常费时费力。若信息抽取技术能低成本、高性能的实现落地,可以大大提升诸多行业的生产效率,节约人力成本。
如今这个想法,迎来了史无前例的可能性。
# 实体抽取
from pprint import pprint
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
>>>
[{'时间': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}],
'赛事名称': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,'probability': 0.8981548639781138,'start': 28,'text': '谷爱凌'}]}]# 事件抽取
schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # Define the schema for event extraction
ie.set_schema(schema) # Reset schema
ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')
>>>
[{'地震触发词':
[{'end': 58,'probability': 0.9987181623528585,'start': 56,'text': '地震',
'relations':
{'地震强度': [{'end': 56,'probability': 0.9962985320905915,'start': 52,'text': '3.5级'}],
'时间': [{'end': 22,'probability': 0.9882578028575182,'start': 11,'text': '5月16日06时08分'}],
'震中位置': [{'end': 50,'probability': 0.8551417444021787,'start': 23,'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)'}],
'震源深度': [{'end': 67,'probability': 0.999158304648045,'start': 63,'text': '10千米'}]}
}]
}]需要留意的是,这还是开放域信息抽取的API接口,也就是说,给定任意要抽取的实体、关系、事件等类型(schema),模型均能从文本中抽取出对应的目标。
例如在第一个示例中,我们希望从文本中抽取出时间、选手和赛事名称这么三种实体,将其作为schema参数传给Taskflow后,模型就可以做到从文本中完成这三类实体的精准抽取。
为了避免精挑细选showcase的嫌疑,小编接连yy了若干实体类型去暴力测试,发现这个API竟然均能应对自如!
感兴趣的小伙伴可以通过以下传送门自行安装体验:
Github链接:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
这波操作放在2022年还是让人感觉有点梦幻了。要知道,市面上的信息抽取工具大多只能做特定领域的封闭域(有限预定义的schema)抽取,效果还很难保证,更不必说打造成三行代码即可完成调用的开放域工具了。
这不禁让人好奇,这个开源工具的背后是怎么做到的呢?
小编找PaddleNLP内部人士了解到,关键有二:
一个发表在ACL2022,屠遍信息抽取榜单的大一统信息抽取诸多子任务的技术UIE
首个知识增强语言模型——ERNIE 3.0
关于第一点,本文的下一章会做重点阐述,在此稍留作悬念。
关于第二点,我们知道,知识对于信息抽取任务至关重要,而ERNIE 3.0不仅参数量大,还吸纳了千万级别实体的知识图谱,可以说是中文NLP方面最有“知识量”的SOTA底座。在ERNIE 3.0的基础上,如果再构造一个面向开放域信息抽取的二阶段SOTA预训练上层建筑呢?
强强联合,便是这个工具带来梦幻体验的密码。

需要注意的是,这个包含强大知识储备的NLP基座和梦幻的信息抽取架构均集成到了PaddleNLP中,PaddleNLP却又不止是一个SOTA收纳箱,其还提供了非常易用的模型压缩部署方案、大模型加速技术、产业场景应用范例,做了扎实的易用性优化和性能优化。一句话总结,打造中文NLP应用的神器。
值得关注的是,UIE不仅具备惊艳的zero-shot开放域信息抽取能力,还有强大的小样本定制训练能力。
作者在互联网、医疗、金融三个行业关系、事件抽取任务上测试了小样本定制训练效果:
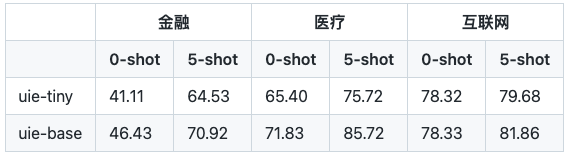
在金融场景,仅仅加了5条训练样本,uie-base模型F1值提升了25个点。
也就是说,即使工具在某些case或某些场景下表现欠佳,人工标几个样本,丢给模型后就会有大幅的表现提升。这个强大的Few-Shot能力则是工具在大量长尾场景落地的最后一公里保障。
对PaddleNLP内置的黑科技细节和玩法感兴趣的小伙伴,可以扫码报名进群,获取PaddleNLP官方近期组织的直播链接,进群还有更多福利哦~
加入PaddleNLP技术交流群

入群福利
获取直播课程链接
获取PaddleNLP团队整理的10G重磅NLP学习大礼包
(设好闹钟噢!不确定是否有回放QvQ)
挖掘该工具更多的潜力和惊喜,请进传送门:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
接下来还有第2点——
一个大一统信息抽取诸多子任务的架构
信息抽取领域的任务繁多,从大的任务类型上,可分为实体抽取、关系抽取、事件抽取、评价维度抽取、观点词抽取、情感倾向抽取等,而若要具体到每个任务类型下的抽取domain和schema定义,则更是无穷无尽了。
因此,以往信息抽取的落地是非常困难、成本高昂的,公司不仅要为每个细分的任务类型和domain标数据、开发模型、专人维护,而且部署起来也非常费力且消耗大量机器资源。
此外,各个子任务也不是完全割裂的,传统的子任务专用设计使得任务之间的通用知识难以共享,一座座“信息孤岛”的力量总是有限的,甚至有偏的。
但现在不是了。由中科院软件所和百度共同提出的一个大一统诸多任务的开放域信息抽取技术UIE,发表在ACL 2022的SOTA技术,直接上图:
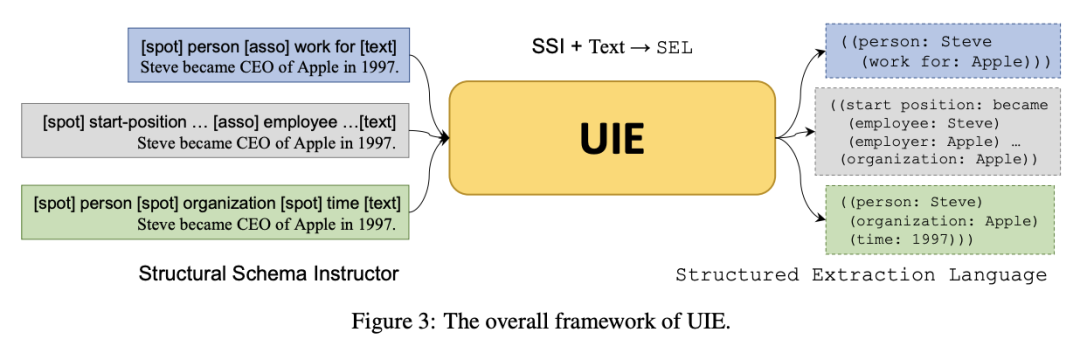
简单来说,UIE借鉴近年来火热的Prompt概念,将希望抽取的Schema信息转换成“线索词”(Schema-based Prompt)作为模型输入的前缀,使得模型理论上能够适应不同领域和任务的Schema信息,并按需抽取出线索词指向的结果,从而实现开放域环境下的通用信息抽取。
例如上图中,假如我们希望从一段文本中抽取出“人名”的实体和“工作于”的关系,便可以构造[spot] person [asso] work for的前缀,连接要抽取的目标文本[text] ,作为整体输入到UIE中。
那么这里关键的UIE模型是如何训练得到的呢?
UIE作者在预训练模型MLM loss的基础上又巧妙的构造了2个任务/loss:
文本-结构预训练$L_{pair}$:给定一个<文本,结构>对,基于抽取出的schema通过随机采样spots和asso的方式来构造schema负例,将schema负例与原始的schema(正例)拼接得到meta-schema,最后再拼接上文本,来预测结构。作者表示这样可以避免模型在预训练阶段暴力记忆三元组,得到通用的文本-结构的映射能力
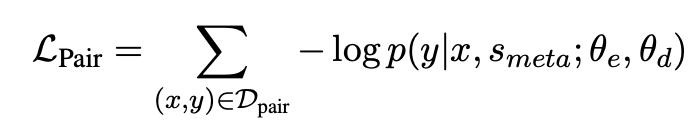
结构生成预训练$L_{record}$:这个任务是为了训练decoder的结构输出能力,将输出结构SEL作为decoder的优化目标,来学到严谨的SEL规则
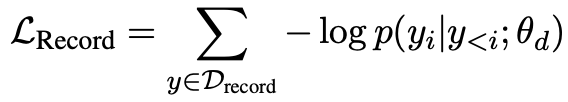
通过2个loss的联合预训练,便得到了强大的UIE模型。
值得注意的是,尽管原论文使用了T5模型作为backbone,基于生成架构。实际上为了发挥模型在中文任务上的最大潜力,且让模型的推理效率变得可接受(毕竟生成任务还是太重了),在本文第一章提到的PaddleNLP信息抽取方案中,使用了强大的ERNIE 3.0模型+抽取式(阅读理解)架构。因此在中文任务上效果更佳,推理速度更快。

对更多细节感兴趣的小伙伴,可以看原论文或在文末扫码海报预约UIE讲解直播~
论文链接:
https://arxiv.org/pdf/2203.12277.pdf
最后讲第1点——
不小心,刷了13个SOTA
UIE在各类IE任务的数据集上表现怎么样呢?
首先是常规设定下,4类抽取任务,13个经典测试集与SOTA的对比:
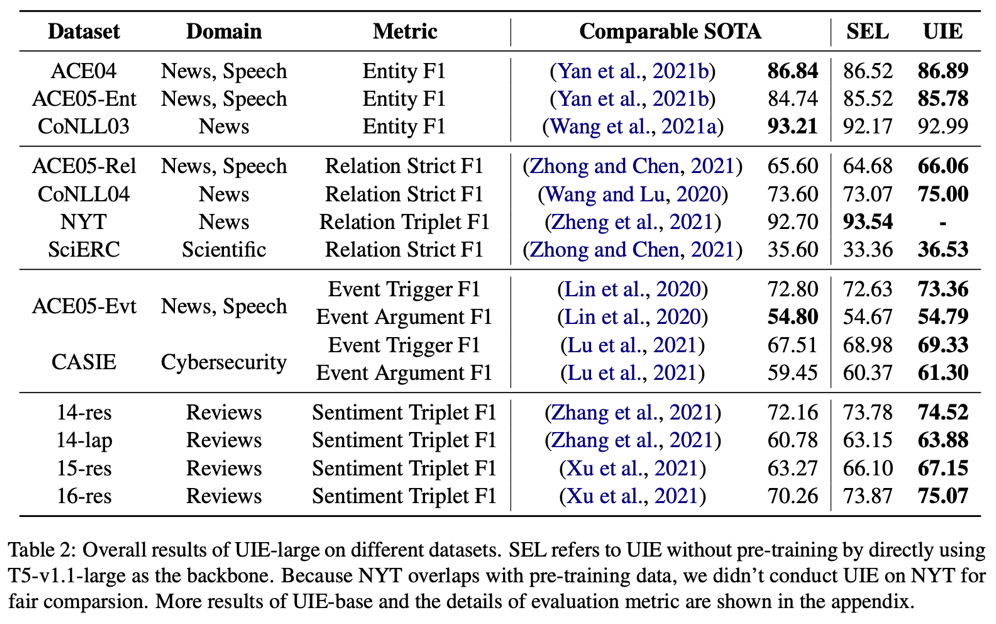
表格右数第二列是未经过UIE预训练的结果(基于T5+SEL直接微调),右数第一列是UIE预训练后微调的结果,可以看出SEL+强大生成模型就可以在信息抽取的统一建模方面取得很强的效果,而经过UIE预训练后则进一步提升了模型表现。
我们知道,模型经过微调,其实会弱化不同预训练策略带来的模型差异。因此UIE预训练的价值在小样本方面得到了更加酣畅淋漓的体现:
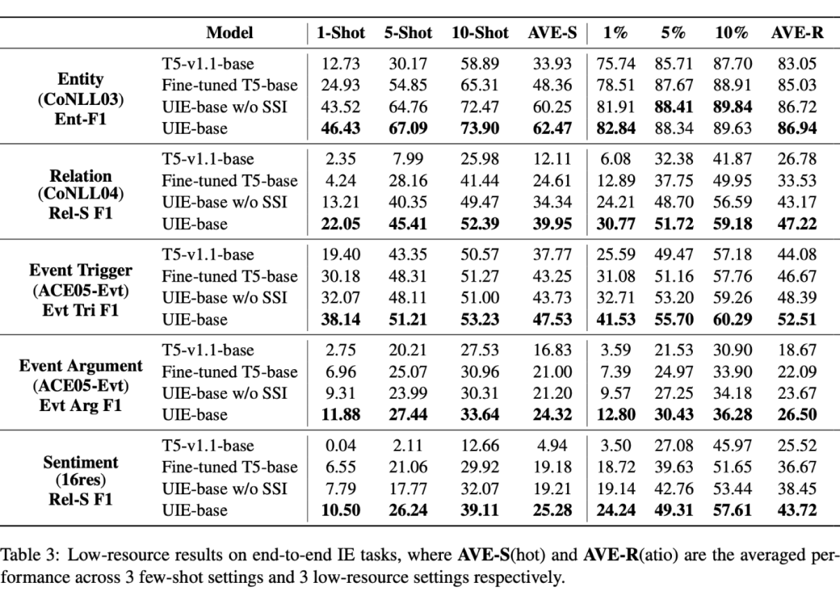
经过UIE预训练后,模型的小样本学习能力得到了极大的提升,这便是UIE工具具备强大定制化能力,进而实现中长尾行业落地的关键。
最后,百度高工会在5.18-5.19日针对信息抽取行业痛点,对UIE和PaddleNLP的玩法和潜力进行深入讲解,通过以下海报扫码预约,进群还有更多福利哦~
入群福利
获取直播课程链接。
获取PaddleNLP团队整理的10G重磅NLP学习大礼包
(设好闹钟噢!不确定是否有回放QvQ)