深度学习之Attention模型详解

转载自:Datawhale(ID:Datawhale)
作者:yif
Attention的产生
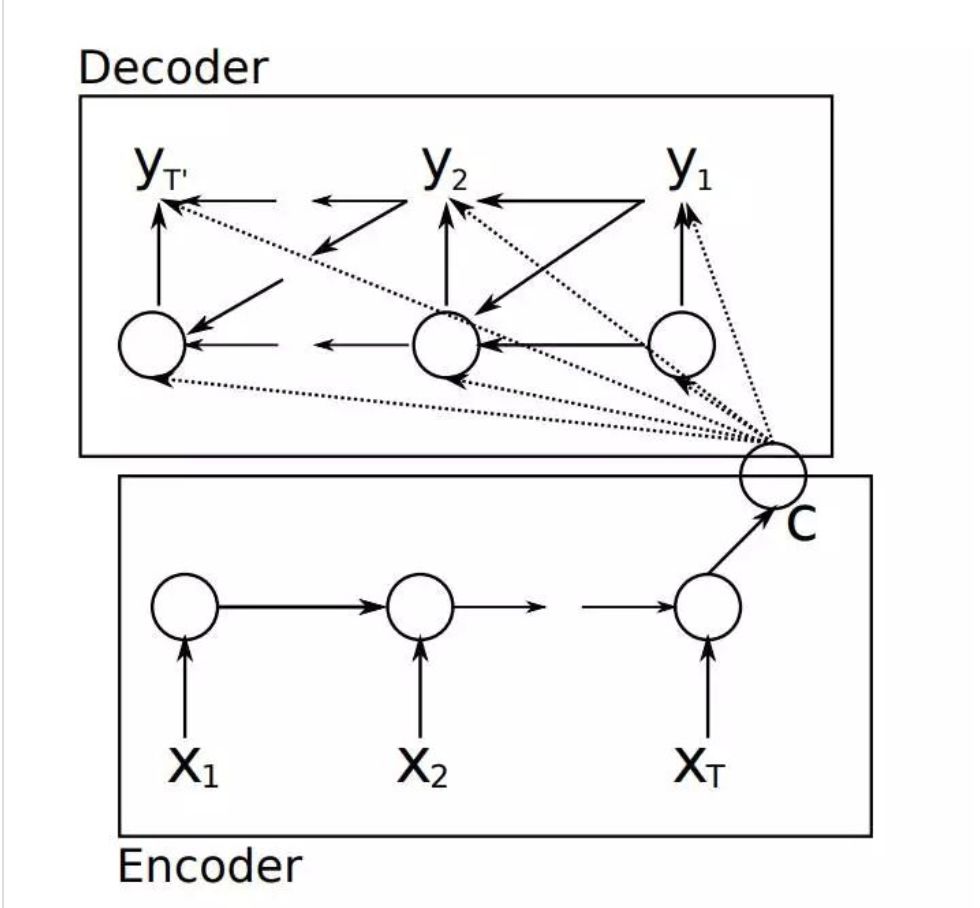
起因:《Sequence to Sequence Learning with Neural Networks》
Attention模型的引入原因:
-
seq2seq将输入序列都压缩成一个固定大小的隐变量,就像我们的压缩文件一样,这个过程是有损压缩的,会迫使丢失许多输入序列中的信息; -
存在着难以对齐的问题。 比如中译音“我爱你” “I love you”,输入序列中的“我”应该与“I”对齐(贡献最大),然而在seq2seq模型中,“我”对"I","love","you"的贡献都是一致的。
Attention的发展
Show, attend and tell: Neural image caption generation with visual attention
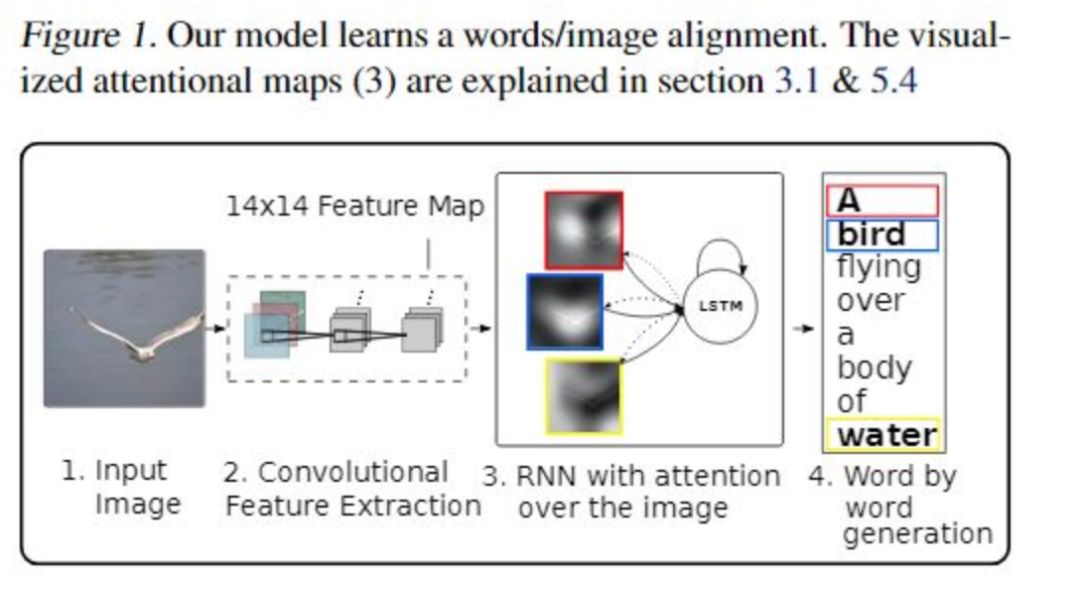
该任务是实现图文转换。与前面讲述的seq2seq的问题一样,在之前的图文转换任务中也是存在着难以对齐的问题。所谓难以对齐就是毫无重点。
本文提出了两种attention:
-
sort Attention -
hard Attention
本文的模型结构:

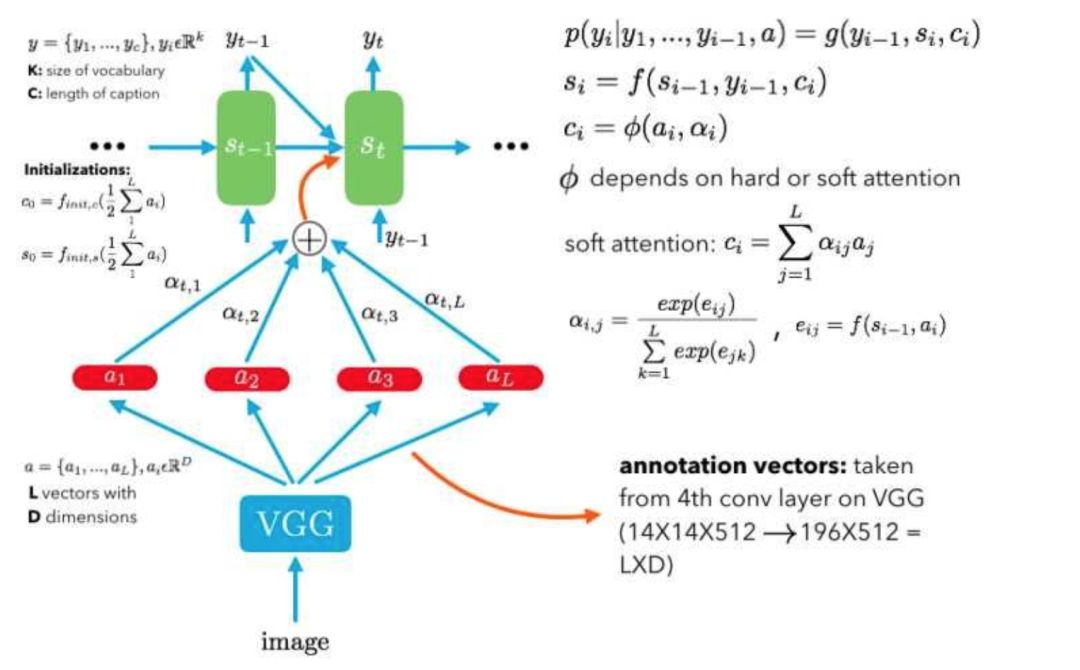
这里编码器是VGG,解码器是LSTM。LTSM输入是不同时刻的图片的关注点信息,然后生成当前时刻的单词。
Attention的计算
如上所属,attention的值不仅与annotation vector 有关,还与上一时刻解码器的隐状态有关。因此有:
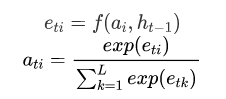
其中t表示时刻t,i表示第i个区域,a是我们得到的attention weight分布。
1,Soft attention:直接使用attention的权重对L个向量加权相加,这么做的好处是整个问题是可微的,可以利用BP end to end。
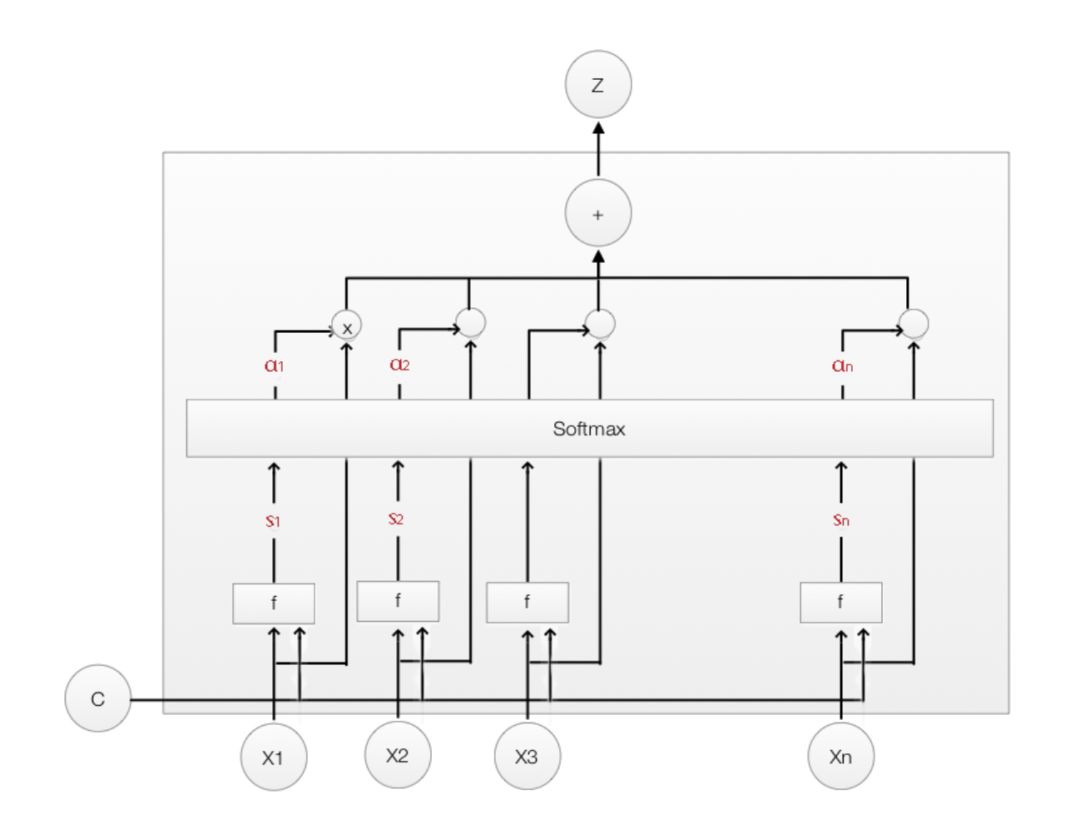
2,Hard attention:Hard attention很粗暴,挑出最大权重的向量,剔除其余向量(置0)。显然这种形式的模型是不可微的,为了实现BP,这里采用蒙特卡洛采样的方法来估计模块的梯度。
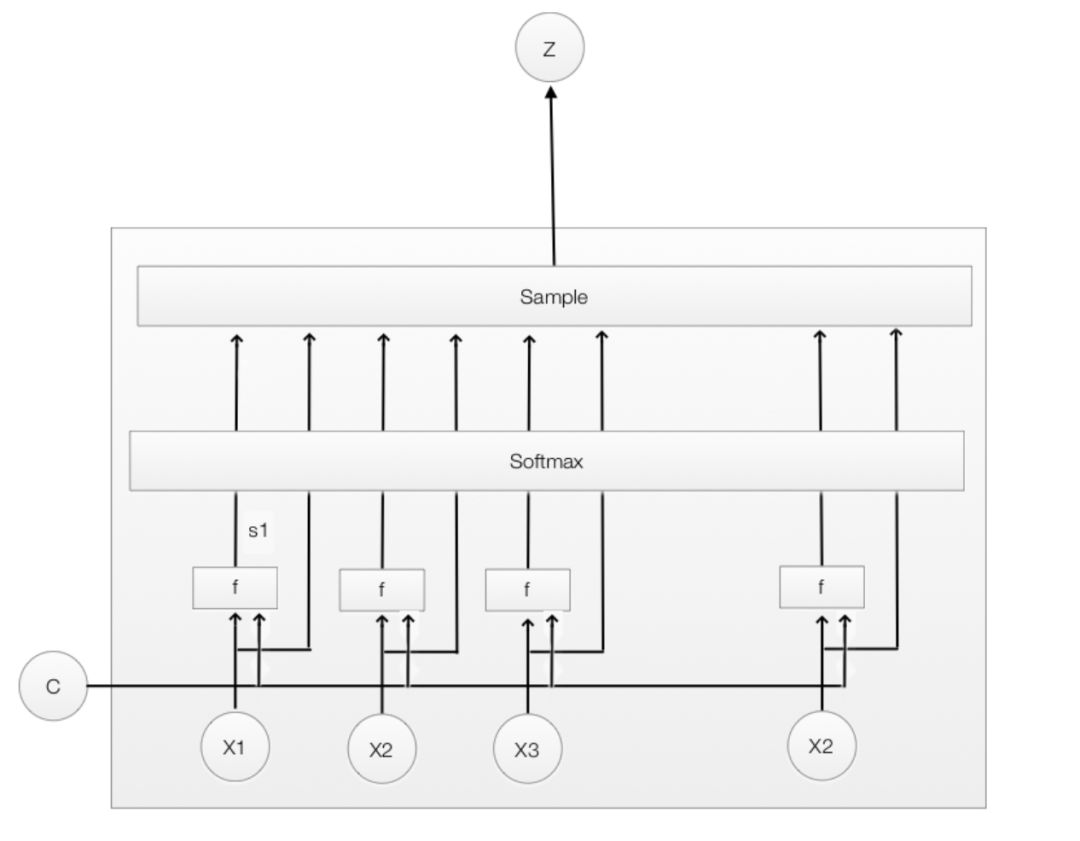
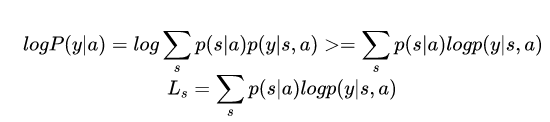
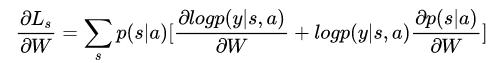
用N次蒙特卡洛采用(抛银币)来近似:
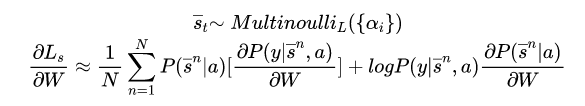
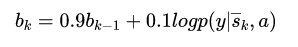
总结
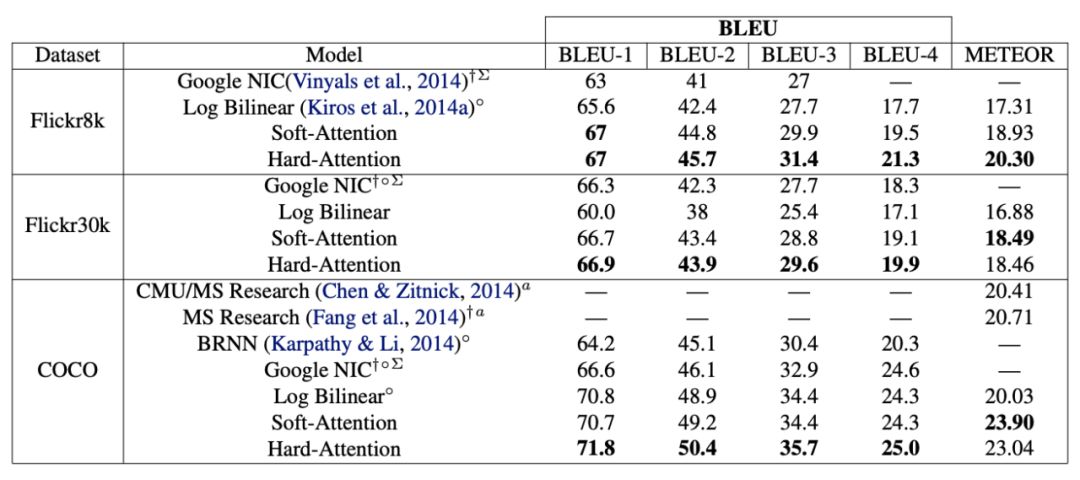
总的来说,这里率先引入了soft attention与hard attention,通过在每一时刻给图片各个区域分配attention权重,来提升语句与特定图块的相关性。
结果:
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
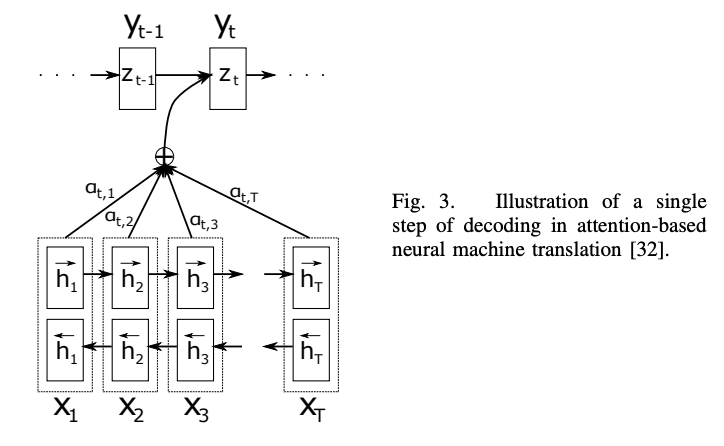
本文同样涉及了soft attention,hard attention。求解形式与上一篇并无差异。
并且文中考虑了四种应用场景:1. Neural Machine Translation ;2. Image Caption Generation ;3. Video Description Generation ;4. End-to-End Neural Speech Recognition。
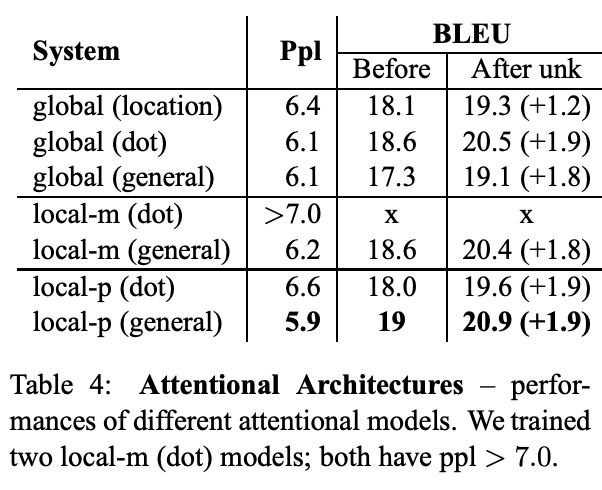
Effective Approaches to Attention-based Neural Machine Translation
本文比上一篇晚发表了2个月。。。
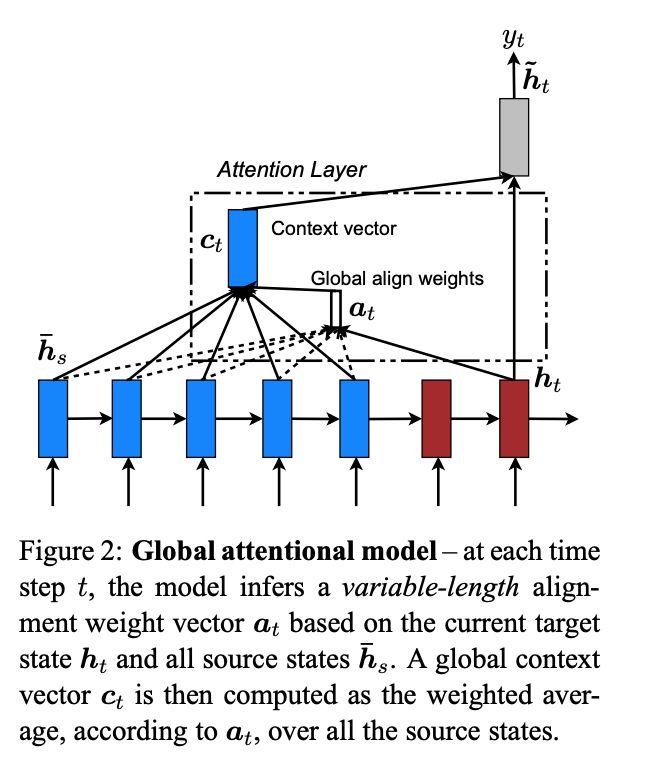
文章提出了两种attention的改进版本,即global attention和local attention。
-
global attention
2.local attention
本文认为local attention为hard attention和soft attention的混合体(优势上的混合),因为他的计算复杂度要低于global attention,soft attention,而且与hard attention 不同的是,local attention 几乎处处可微,易于训练。
local attention克服了每个source hidden state都要扫描的缺点,计算开销大,而且对于长句不利,为了提升效率,提出了 local attention。每次只focus 一部分的source position。
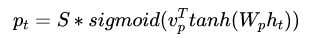
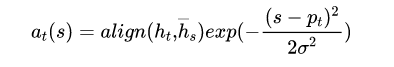
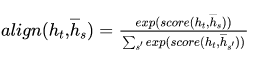
Attention-Based Multi-Perspective Convolutional Neural Networks for Textual Similarity Measurement
本文的任务是STS(semantic textual similarity)指给定一个检索句子和比较的句子,计算他们的相似度得分。

过去的模型,把输入的句子独立对待,忽略了句子的上下文交互。attention也就是因此而引入的。
本文的基础模型结构是:MPCNN(multi-perspective con- volutional neural network model),主要包括两个部分:1,multi-perspective sentence model;2, structured similarity measurement layer。
-
multi-perspective sentence model
multi-perspective sentence model 使用的是卷积神经网络,通过使用不同类型的卷积核,不同类型的池化方式,不同大小的卷积窗口,来得到每个句子的不同粒度的表达。
a. 卷积层有两种卷积的方式:(1)粒度为word的卷积;(2)粒度为embedding 维度上的卷积。前者相当于n-gram特征抽取,后者抽取的是向量每一维度上的信息。作者认为后面这种方式由于粒度更小有助于充分地提取出输入的特征信息。作者使用了这两种方式以获得更丰富的表达。
b. 卷积窗口大小:不同卷积窗口的大小捕捉不同n-gram的长度下的信息,这里窗口大小是{1, 2, 3,∞}, 表示输入句子中unigrams, bigrams, trigrams和不使用卷积层。
c. 池化方式:池化层可以保留一个卷积模型中最显著和最通用的特性,这里使用max,min,mean三种方式。
-
Structured Similarity Measurement layer
Structured Similarity Measurement Layer的目标是计算句子表达的相似度。
Structured Similarity Measurement Layer的目标是计算句子表达的相似度。作者认为最后生成的句子向量中的每一个部分的意义各不相同,直接应用传统的相似度计算方法如余弦相似度在两个句子向量上并不是最优的,应该对句子向量中的各个部分进行相应的比较和计算(Structured Comparision)。为了使得句子向量中的局部间的比较和计算更加有效,我们需要考虑如下方面:
(1) 是否来自相同的building block;(2) 是否来自相同卷积窗口大小下的卷积结果;(3) 是否来自相同的pooling层;(4) 是否来自相同的Feature Map;
至少满足以上两个条件时,才比较句子中的相应部分时,作者采用了两种算法比较相似性。一种只针对粒度为词的卷积,另一种则同时针对粒度为词的卷积和粒度为embedding 维度上的卷积。
在句子局部的相似度计算之后,作者叠加了两层的线性层,并在中间使用了tanh激活函数,最后使用log-softmax输出。更多的细节参考He et al. 2015。
Attention-Based Input Interaction Layer
本文作者在上述模型的基础上,增加了一层基于attention的交互层。其目的就是在刚做完embedding以后,给两个句子更相关的部分赋予更多的权值。
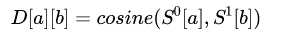

ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs

这里提出了三种ABCNN
-
ABCNN-1

ttention 矩阵的计算:
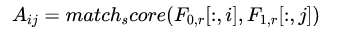
可以从上图看出矩阵中的一列代表一个词,行代表特征。
-
ABCNN-2
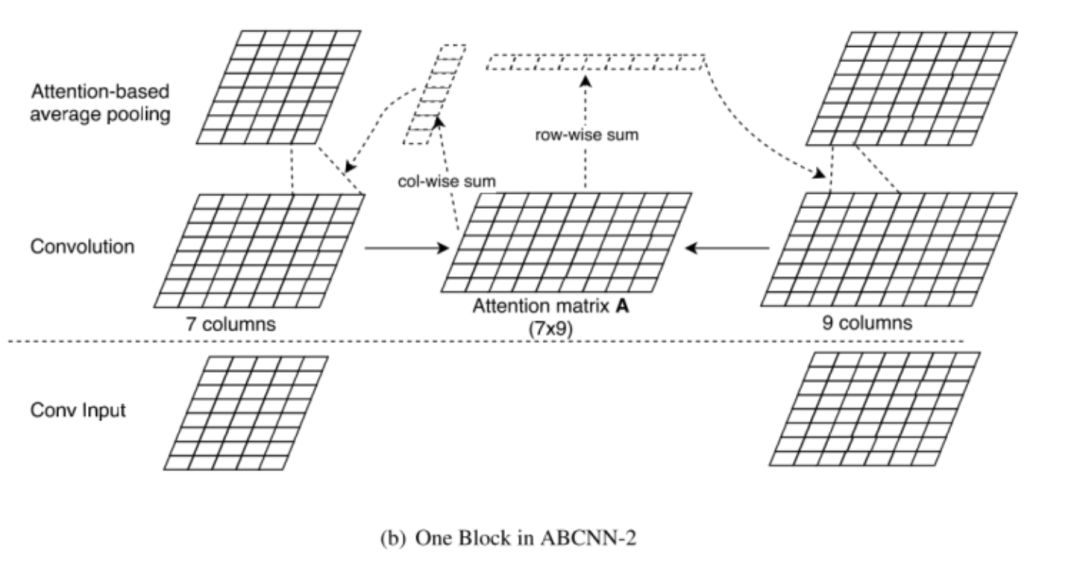
这里Attention矩阵的计算方式与ABCNN-1类似,不同的是在ABCNN-1的基础上对两个句子的unit进行求和作为unit的attention 值,即

-
ABCNN-3
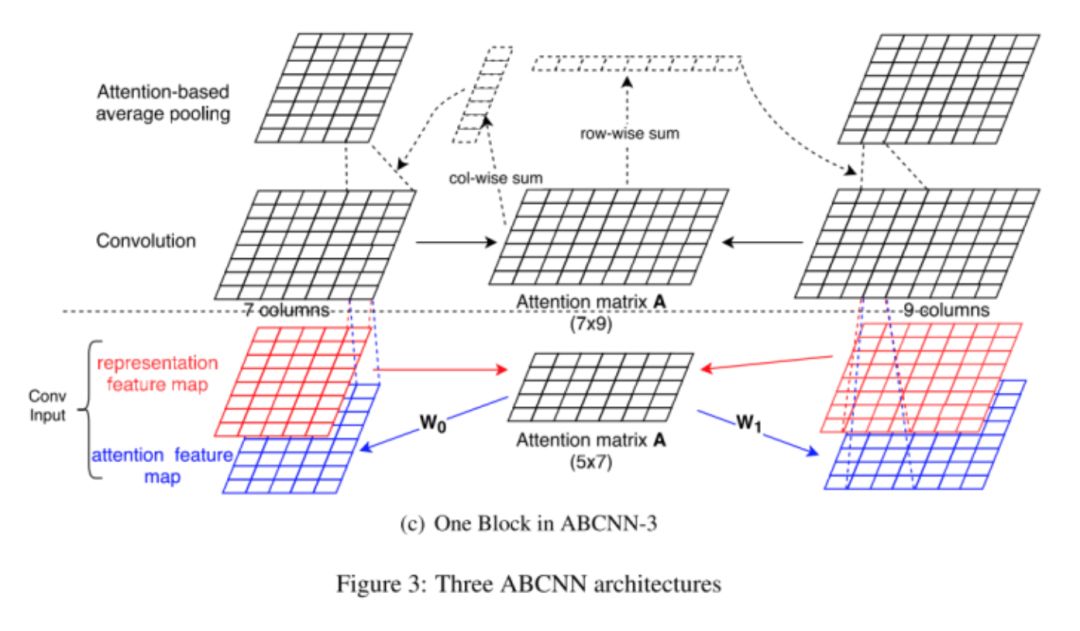
本文实际上提出了两种引入attention 的位置,一种是在Conv前(ABCNN-1),一种是Conv后(ABCNN-2)。从结果来看,Attention放在Conv后的效果比前面的效果更好。可能的原因是Word embedding经过Conv相当于提取了n-gram,能表示上下文。conv 之后再结合 Attention 能比单纯 input 之后的 Attention 包含更多的信息。
Graph Attention Network(GAT)
小结1
之后的一系列论文如《Multi-Attention CNN for FGVC:MA-CNN》,《Coupled Multi-Layer Attentions for Co-Extraction of Aspect and Opinion Terms》等尽管实现的任务都花里胡哨的,并引入了Attention,但是attention的使用方式还是千篇一律。
Attention is all you need
提出的动机:
-
跳出原来千篇一律的attention形式,不使用CNN,不使用RNN,光靠attention,实现高并行化; -
抓取更强的长距离依赖关系。
创新点:
-
总结了attention的通用形式; -
提出了self attention,multi-head attention; -
Transform结构。
总结Attention的通用格式
作者将Attention理解为q,k,v的形式,
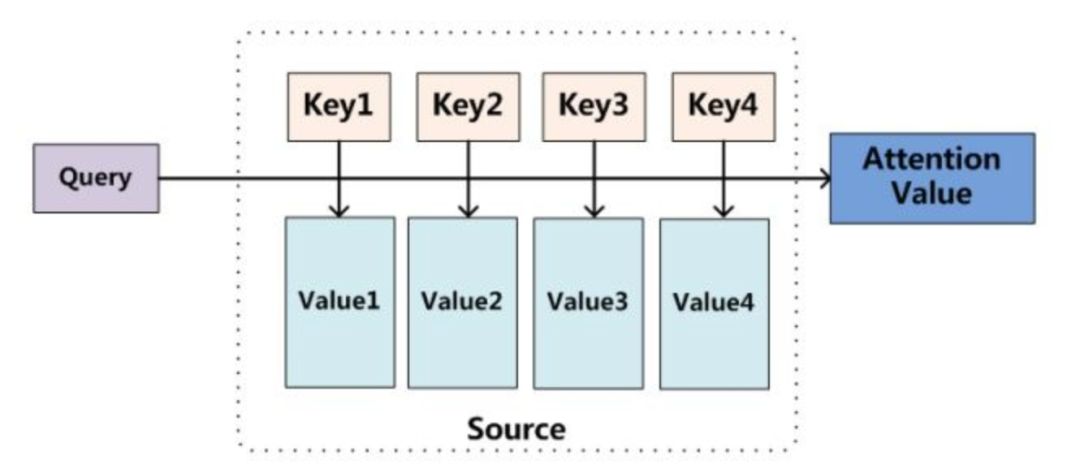
其实前面介绍的attention都可以套用该框架。
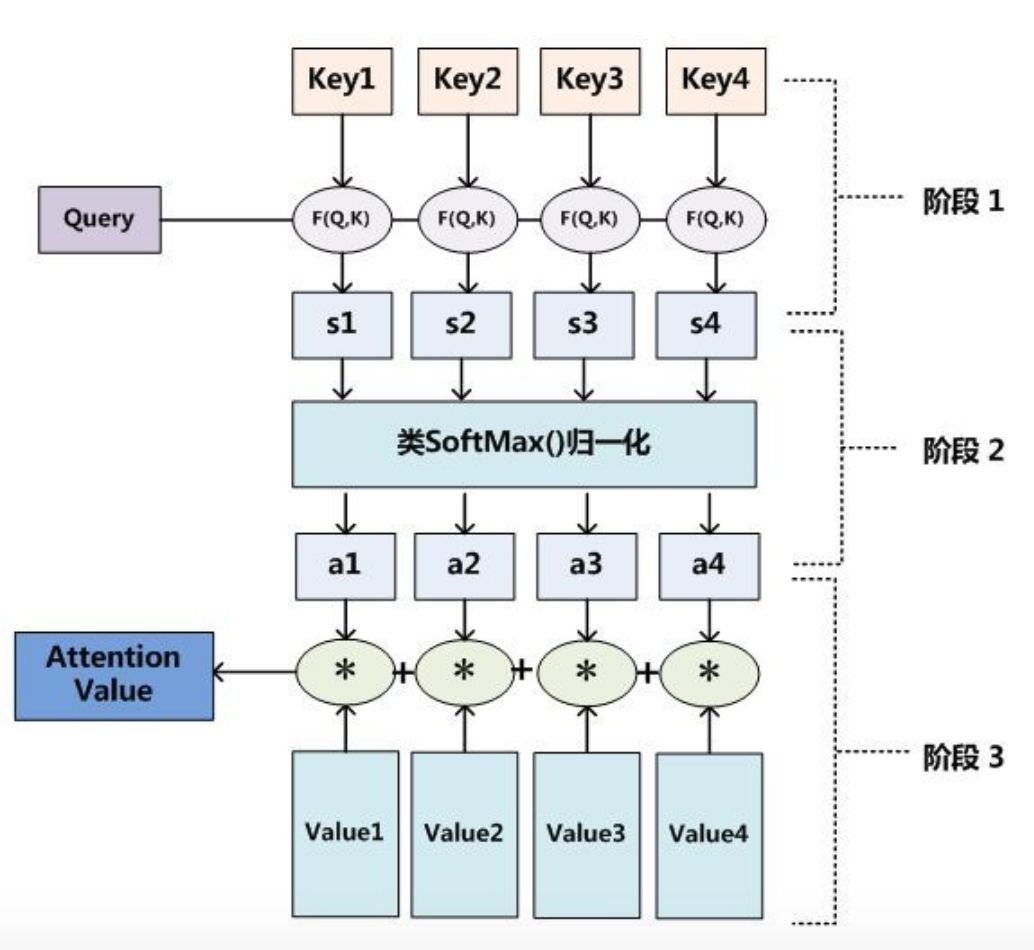
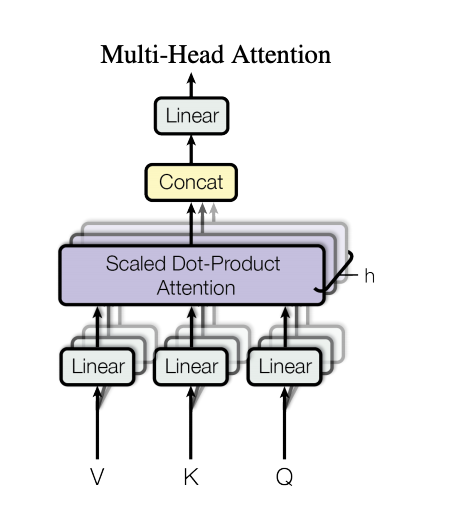
提出self attention, multi-head attention
这里的self attention 指的是用到自身的信息来计算attention。传统的attention都是考虑用外部信息来计算attention。
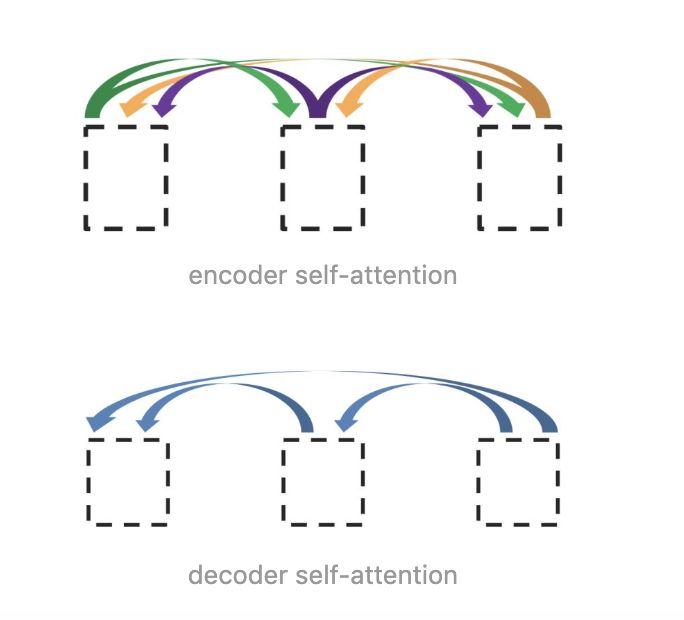
这里采用的attention计算方式也与之前的不同,采用 Scaled Dot-Product 的形式。
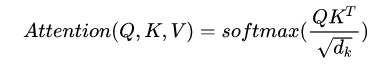
注意:分母是为了归一化,避免造成进入softmax函数的饱和区,其梯度较小。
采用multi-head attention为的就是让不同head学习到不同的子空间语义。显然实验也证实这种形式的结果较好。
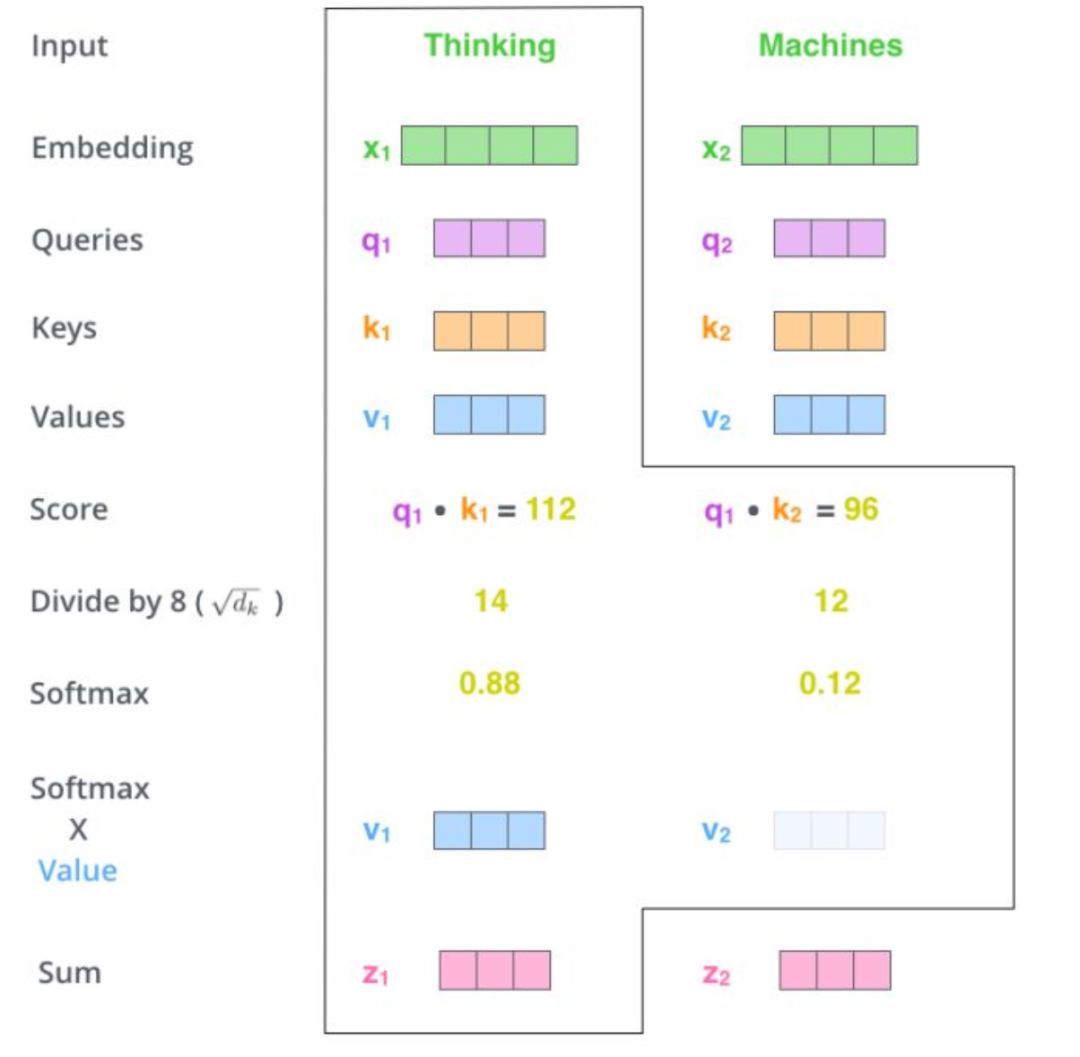
在self attention中其实在做的当前文本句中单词依赖关系分数的计算。
比如“Think Machines”两个单词:
优点:
-
由于self attention 是对整个文本句求attention的,所以他能抓取到当前单词和该文本句中所有单词的依赖关系强度。 这方面的能力显然比RNN的获取长依赖的能力强大的多; -
此时不在用RNN的这种串行模式,即每一步计算依赖于上一步的计算结果。 因此可以像CNN一样并行处理,而CNN只能捕获局部信息,通过层叠获取全局联系增强视野。
缺点:很显然,既是并行又能全局,但他不能捕捉语序顺序。这是很糟糕的,有点像词袋模型。因为相同单词不同词序的含义会有很大差别。为了克服这个问题,作者引入了Position embedding。这是后话了。
Transform
Transform是一大法宝,影响深远。
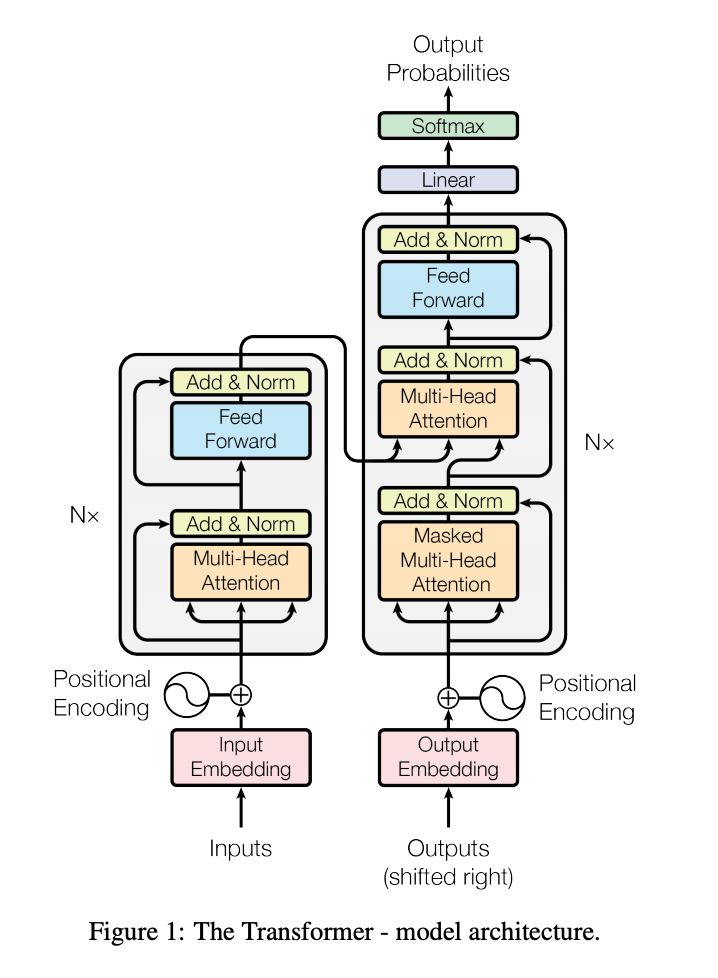
从上图粗看,Transform仍延续着一个Encoder一个Decoder的形式。
重要部件:
-
Positional embedding。正如上面所说,self attention缺乏位置信息,这是不合理的。 为了引入位置信息,这里用了一个部件position embedding。
这里考虑每个token的position embedding的向量维度也是d维的,与input embedding的输出一样,然后将input embedding和position embedding 加起来组成最终的embedding输入到上面的encoder/decoder中去。这里的position embedding计算公式如下:
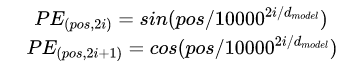
其中pos表示位置的index,i表示dimension index。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有
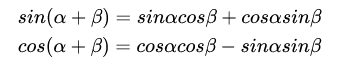
这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
-
residual connection 。无论是encoder还是decoder,我们都能看到存在residual connection这种跳跃连接。
随着深度的增加会导致梯度出现弥散或者爆炸,更为严重的是会导致模型退化 (也就是在训练集上性能饱和甚至下降,与过拟合不同)。深度残差网络就是为了解决退化的问题。其实引入残差连接,也是为了尽可能保留原始输入x的信息。
-
Layer Normalization
与 BN 不同,LN 是一种横向的规范化。
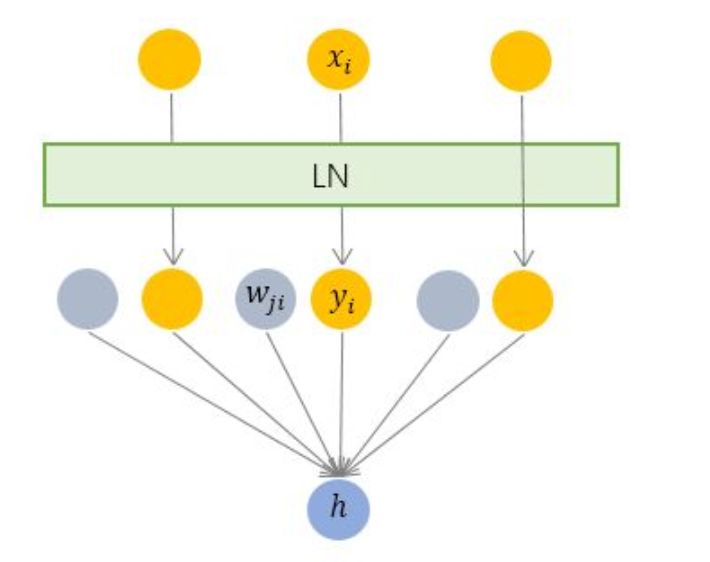
LN针对单个训练样本进行,不依赖于其他数据。避免了受mini batch中其他数据的影响。
BN适用于不同mini batch数据分布差异不大的情况,而且BN需要开辟变量存每个节点的均值和方差,空间消耗略大;而且 BN适用于有mini_batch的场景。
-
Masked Multi-Head Attention
这里用mask来遮蔽当前位置后面的单词。实现也很简单,采用一个上三角都为1,下三角为0的矩阵。

小结一下:本文对attention的概念进行了本质上的转变。传统的attention是在端尾计算源文本各个token对该时刻单词的贡献。而self attention将这个过程提到了端口,计算当前句子中token的相关性来充分各个token的表达其语义。简单的讲就是传统的attention是为了使输出端表达充分,而self attention 是为了使输入端表达充分。尽管他们的形式都可以用Q,K,V框架来解释。
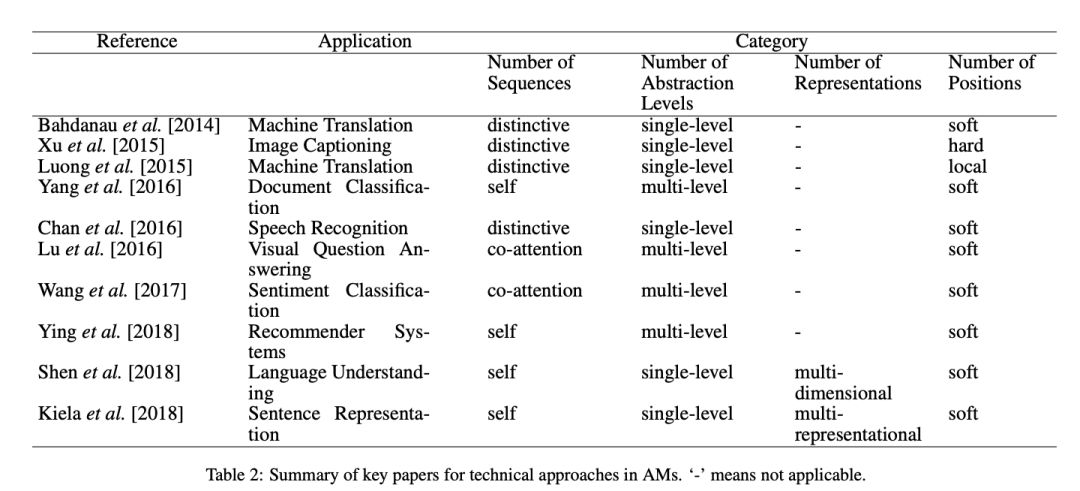
An Attentive Survey of Attention Models
《An Attentive Survey of Attention Models》 是香农科技提出的一篇关于attention的综述论文。
未完待续
其实还有很多要补充的,比如Memory Network中的attention(外部记忆作为V)以及Graph neural network里的attention,尽管理论上都是一个道理,但是还要对的起标题的all。待补充。
——END——




