点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:机器之心
作者:Eric Jang | 编辑:Panda
数据集过于简单、只在一两项指标上达到 SOTA、没有充分说明之前的研究都可能成为你论文被拒的原因。
![]()
会议论文评审已经成为了人工智能和机器学习领域的热门争议话题,既有审稿人在线吐槽论文注水严重,半成品太多,也有投稿人网上喊冤,质疑审稿人的资格和敬业程度。
纷纷扰扰之中,也许一个重要的原因是论文评审缺乏明晰的标准,严重依赖审稿人的主观判断。
近日,谷歌 Robotics 研究科学家 Eric Jang 基于他十多场会议和研讨会的审稿经验,罗列了审稿人在评审论文时可能会考虑的标准,然后他说明了自己个人的审稿标准。
这虽然只是一位审稿人的个人看法,但如果审稿人都能公开说明自己的审稿标准,当前会议论文评审方面的争议之声大概也会小一些。
机器学习研究者大概都知道,NeurIPS 和其它一些会议的接收决定就像是一种经过加权的掷骰子游戏。在这个被称为「学术出版」的剧场中,评议五花八门,因为每个审稿人在机器学习论文方面都有各自的偏好(随便一提,现在的学术出版也与实际的研究有些脱节)。
正确性
:这是科学论文的最低要求。论文中给出的主张在科学上是否正确?作者是否注意了不在测试集上进行训练?如果一篇论文提出了一种新算法,作者是否给出了让人信服的证据说明该算法有效的原因就是其给出的原因?
新信息
:你的论文必须要能为这一领域贡献新知识。这个新知识可能是新算法、新的实验数据或某种解释现有概念的不同方法。甚至综述论文也应该包含一些新信息,比如某个可以统一多个独立研究成果的全面视角。
适当的引用
:论文中应该包含一个相关研究部分,其中说明了该研究与之前的研究的联系以及当前研究的新颖之处。某些审稿人会直接拒收没有充分说明之前的研究或与之前的研究没有足够区别的论文。
当前最佳结果(SOTA)
:审稿人通常对论文有这样两个要求:(1)提出了一种新算法,(2)在某个基准上实现了 SOTA。
不能「只是」 SOTA
:没有人会因为你取得了 SOTA 而惩罚你,但某些专家不仅希望看到在某项基准上取得突破,比如在列表中一两项指标上的突破。一些审稿人甚至还会打击该领域这种「追逐 SOTA」的文化,他们会认为这样的研究「创新不足」或「只是增量式研究」。
简洁性
:很多研究者都表示支持「简单的思想」。但是,「你的简单思想」和「你对其他人的简单思想的简单扩展」是两码事,虽然两者之间的区别并不总是明显。
复杂性
:某些审稿人认为没有给出任何新方法或漂亮的数学证明的论文是「简单琐碎的」或「不严谨的」。
清晰度和可理解性
:某些审稿人关心所提出的算法的机制细节以及对机器学习的进一步理解,而不只是得到更好的结果。这与「正确性」紧密相关。
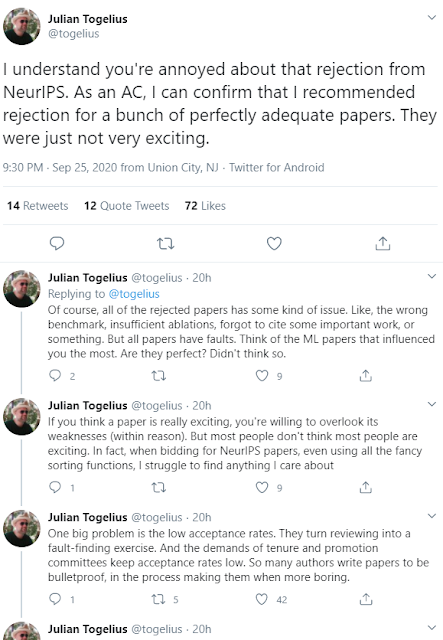
是否「激动人心」
:NeurIPS 2020 的领域主席之一 Julian Togelius 提到,他拒绝许多论文的原因就只是它们不够激动人心。只有 Julian 自己知道什么样的论文能打动他的心,不过我认为他的意思是在选择研究课题和解决方案上「有良好的品味」。
![]()
足够困难的问题
:某些审稿人会因为评估方法的数据集(比如 MNIST)过于简单而拒绝论文。「足够困难」是一个不断变动的目标,其中隐含着一个预期:该领域会不断开发出更好的方法,因此评估标准也应该变得更困难,这样才能推动领域的发展,解决之前无法解决的问题。同样,在简单基准上的 SOTA 方法并不一定就是更困难基准上的 SOTA,而更困难的基准往往更接近真实应用。幸好我被引用最多的论文写于 MNIST 数据集尚可接受的时代。
是否「出人意料」
:即便某篇论文确实给出了成功的结果,审稿人可能还是会说这个结果「并不意外」或「显而易见」。举个例子,将标准的目标识别技术应用于某个新数据集的论文可能会被认为「过于简单和直接」,尤其考虑到现在该领域的专家普遍认为目标识别问题基本已得到解决(这并非事实,但评估基准还未反映出这一点)。
我真的很喜欢违背直觉的论文,而且我个人也在努力写能给人惊喜的论文。
在这方面,我个人最喜欢的一些论文根本没有实现 SOTA 或提出新算法:
Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet,有关该论文的介绍可参阅《过往 Net,皆为调参?一篇 BagNet 论文引发学界震动》(这是本文的作者 Eric Jang 写的一篇分析解读)。
Understanding Deep Learning Requires Rethinking Generalization. 可参阅《要理解深度学习,必须突破常规视角去理解优化》
A Metric Learning Reality Check
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Adversarial Spheres,可参阅《谷歌大脑提出 Adversarial Spheres:从简单流形探讨对抗性样本的来源》
是否真实
:这与「足够困难的问题」紧密相关。某些审稿人认为游戏是研究强化学习的优良试验场,但其它一些审稿人(通常来自典型的机器人研究社区)则认为 Mujoco Ant 和真正的四足机器人是完全不同的问题,在前一领域的算法比较并不能为后者的同类型实验提供任何见解。
你的研究是否符合良好的 AI 道德伦理
?某些审稿人认为开发机器学习技术的目的是构建一个更好的社会,所以他们不会支持那些与他们的 AI 道德伦理观相悖的论文。今年,向 NeurIPS 提交论文时需要填写「Broader Impact(更广泛的影响)」称述,这说明该领域正在更为严肃地对待这一问题。举个例子,如果你提交一篇仅靠人脸识别来推断犯罪可能性的论文或一篇执行自动武器瞄准的论文,我相信不管你开发了怎样的方法,这篇论文都很可能被拒。
不同的审稿人在以上问题的优先级方面都有各自的看法,而且其中很多标准都非常主观(比如对问题的品味、道德伦理、简洁性)。对于以上的每一条标准,都有可能找出反例(但可能满足其它标准),而且其中一些反例还有很高的引用量或对机器学习领域有很大的影响。
我还想分享一下我在审议论文时的标准。在涉及到建议接收或拒绝时,我最关心的标准是正确性和新信息。即便我认为你的论文很无趣,在 10 年内都不可能成为一个活跃的研究领域,但只要你的论文能帮我了解我认为之前还没有过的新东西,我就会投支持票。
如果你在引言中提到了强化学习研究中类似人类的探索能力然后提出了一种能实现能力的算法,那我希望能看到实质性的实验证据,说明这个算法确实与人类的能力类似。
如果你的算法没有实现 SOTA,我能够接受这一点。但我希望能看到你详细地分析了你的算法不能实现 SOTA 的原因。
如果有论文提出了新算法,我希望这个算法至少比之前的工作好。但是,只要论文给出了该算法为什么不比之前工作更好的事实性分析,我仍会投接收票。
如果你宣称你的算法表现更优的原因是 X,我希望看到你用实验证明了原因不是其它的 X1、X2……
我当然不会得意洋洋地批判这一点,毕竟我也是其中的一员。我已经审阅过 10 多场会议和研讨会的论文,但老实说,单靠阅读,我只能理解其中 25%。为了写出一篇研究论文,作者可能会投入几十乃至数百小时来设计和执行实验,但我仅用几个小时来决定它是不是「正确的科学」。我很少遇到那些我真正有足够的专业能力执行严格的正确性评估的论文。
我常常问自己一个问题:「怎样的实验能说服我相信作者的解释是正确的,而不是因为其它假设?这些作者检查过这些假设吗?」
我相信我们应该接收所有「合格的」论文,像是「品味」和「简洁性」这种更主观的看法不应被用作是否接收论文的标准,而应该保留为评估是否得奖、Spotlight 展示论文和 Oral 展示论文的标准。我不知道是否所有人都应该采用这样的标准,但作为一位审稿人,我觉得在接收 / 拒绝决策上保持公开透明至少会有一些帮助。
原文链接:https://blog.evjang.com/2020/09/reviewing.html
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。
![]()
下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2300+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!![]()