加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
阵列相机可以从不同的视角记录当前场景,并对场景的结构进行解析,因而在战场侦察、公安监视等领域具有巨大的应用潜力。
近日,国防科技大学研究团队提出阵列相机去除前景遮挡成像新方法,相关论文DeOccNet: Learning to SeeThrough Foreground Occlusions in Light Fields已被WACV2020录用。
作为领域内首个基于深度学习的去遮挡成像工作,作者提出遮挡物掩膜嵌入法(Mask Embedding)解决了训练数据缺乏的问题,并建立了仿真与实测数据集,供领域内算法进行测评。论文信息如下:
https://arxiv.org/abs/1912.04459
https://github.com/YingqianWang/DeOccNet
引言
在战场侦察、公安监视等领域,复杂的前景遮挡会给目标检测与跟踪等算法带来巨大的挑战。因此,可靠地去除前景遮挡物对于场景的智能感知与智能处理具有重要的意义。阵列相机可以获取当前场景不同视角处的图像,在某个视角中被遮挡的光线可以被其他位置的相机捕捉到。利用阵列图像之间的互补信息可以重建出被遮挡的背景物体,即实现前景遮挡的去除。
论文提出了领域内首个针对光场去遮挡(LF-DeOcc)任务的深度学习网络DeOccNet,Fig. 1展示了论文算法的效果。
Fig. 1(a)展示了渲染数据集中场景Syn01的结构,图中5*5的黄色方块表示阵列相机;
Fig. 1(b)展示了中心子相机获取的含有前景遮挡物的图像;
Fig. 1(d)是Syn01场景对应的无遮挡groundtruth图像。
虽然近年来基于深度学习的图像处理方法在计算机视觉领域得到了十分广泛的应用,但是领域内并没有针对LF-DeOcc任务的深度学习方法。作者在论文中分析了这一现状产生的原因,将深度学习方法应用于LF-DeOcc任务时面临的
挑战总结为以下三个方面:
(1)LF-DeOcc任务要求网络在处理高维光场数据的同时,要保持足够大的感受野并提取高层语义信息,从而实现不同尺度前景遮挡物特征的提取。
(2)相比于图像修复(Inpainting)任务而言,LF-DeOcc任务要求网络通过解析场景结构(如利用前景与背景的深度差异)实现前景遮挡物的自动分离与去除。
(3)该领域没有大规模数据集供算法训练,用于评测的公开数据集场景也十分有限。
针对以上挑战,作者在论文中提出了相应的解决方案。DeOccNet基于encoder-decoder网络框架,实现较大的感受野并提取输入图像的高层语义特征;作者将阵列图像在通道层级联作为网络的输入,充分利用各个视角的互补信息;对于领域数据集缺乏的问题,作者提出了
Mask Embedding方法自动生成训练数据。
作者将80个遮挡物的图像按照光场结构随机嵌入至60个公开的光场场景中,生成大量的含有遮挡物的训练图像(共1500个场景)供算法训练。同时,作者建立了用于对算法进行测评的数据集,包含若干仿真场景(使用3dsMax软件渲染得到)与实际场景(利用相机与扫描台拍摄得到)。
实验结果表明,算法通过在Mask Embedding方法生成的数据集上进行训练,能够学会对场景结构的解析与前景遮挡物的去除,并能够较好地泛化到实际场景中。
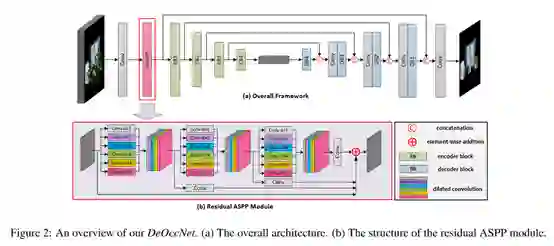
DeOccNet网络结构
DeOccNet网络将光场子图像沿通道维级联作为输入,采用encoder-decoder框架进行高层语义信息的提取与处理,skip connection用于在解码过程中保持低层特征的一致性。
作者采用了残差空洞金字塔(residual ASPP)模块在编码之前获取更大的感受野,引导网络对语义信息(如遮挡物)的提取。论文的实验部分对residual ASPP和skip connection的设计进行了消融实验,实验结果验证了其有效性。
论文中采用有监督方式对DeOccNet进行端对端训练。将含有遮挡物的阵列图像输入到网络中,损失函数定义为网络的输出图像与训练集中该场景对应的无遮挡中心视角图像的均方误差(MSE)。
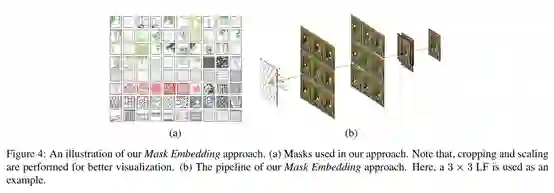
Mask Embedding训练集生成方法
DeOccNet的训练需要大量的遮挡可去除的场景,而当前领域内缺乏足够的训练数据。考虑到训练所需场景数量庞大(10^3数量级),无论是利用设备拍摄实际场景还是利用软件渲染仿真场景,都十分耗时耗力。
作者针对这一问题提出了新的解决方案Mask Embedding,即采用生活中常见的80幅前景遮挡物图像作为掩膜(Mask),将Mask按照光场的结构嵌入(Embed)至公开数据集的光场中深度较浅的区域,从而构造出含有前景遮挡物的光场图像供网络训练。
作者仅使用Mask Embedding生成的数据进行训练,可以使网络学会对场景结构的解析,并通过disparity的差异去除前景遮挡物。在真实场景上,DeOccNet可以取得较传统方法与单帧图像修复方法更为优异的去遮挡效果。
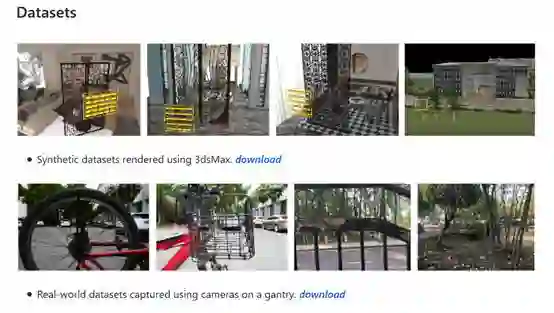
仿真渲染与实际拍摄数据集
针对领域内测试场景缺乏的问题,作者建立了仿真与实测场景用于对算法进行测评。目前数据集已开源,研究者可以公开下载。
仿真场景利用3dsMax软件渲染生成,场景的角度分辨率为5*5,每个场景提供各个视角的遮挡图像、中心视角遮挡物的二值掩膜(Mask)图像、以及中心视角的无遮挡groundtruth图像。由于含有遮挡与无遮挡的中心视角图像是精确对齐的,以上仿真场景可以用来对算法进行数值评估(quantitative evaluation)。
真实场景通过使用相机对户外场景拍摄得到。采集真实场景时,作者将Leica相机固定于机械扫描台上,通过控制扫描台将相机依次移动至5*5的采样点处(基线长度3 cm)进行拍摄。通过对图像的后期校正处理,最终得到5*5视角的遮挡图像。真实场景不提供无遮挡groundtruth图像,因此主要用于对算法进行视觉评估(qualitativeevaluation)。
实验结果
作者在论文建立的仿真与实际场景以及公开数据集场景(Stanford CD)上对算法进行了评测,结果如下:
注意到Fig. 6对应的CD场景角分辨率为5*15,作者将中心视角遮挡图像复制75次输入至网络中,得到结果图Fig. 6(f)。可以发现算法仅处理中心视角图像并不能实现去遮挡效果。
由此可见,DeOccNet确实是利用disparity的差异来解析场景结构,并利用视角间的互补信息实现遮挡物的去除,这与单帧图像修复的机制有所区别。
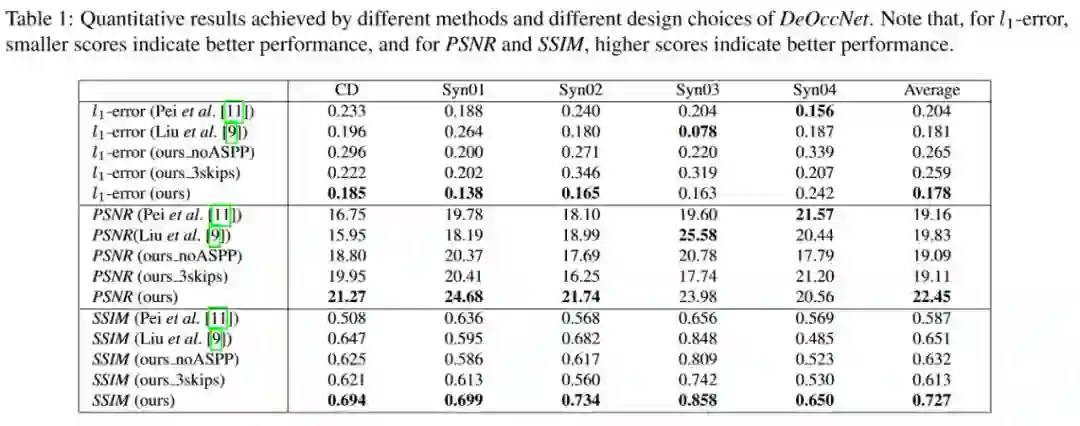
论文中采用L1误差、峰值信噪比PSNR以及结构相似度SSIM进行数值评价,结果如下表所示。
相比于领域内其他去遮挡算法[11]与单帧图像修复算法[9](遮挡区域人工标注),该算法能够取得较为显著的性能提升。同时,作者对网络结构中的ASPP模块以及skip connection做了消融实验,结果验证了网络设计的有效性。
总结与未来工作
论文提出了阵列相机去遮挡成像领域首个深度学习网络DeOccNet,并通过Mask Embedding方法解决了训练数据不足的问题。同时,论文建立了若干仿真与实测场景用于算法评测,实验验证了算法的有效性。DeOccNet主要利用了阵列相机视角间的互补信息进行前景遮挡的去除,并未充分使用单个视角图像中的上下文信息。
未来工作可以结合单帧图像修复算法,综合利用单幅图像的上下文信息与视角间的互补信息,进一步提升去遮挡成像的重建精度与视觉效果。同时,可以探索更加逼近实际遮挡情形的训练集生成方法,进一步提升算法的泛化性能。
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()