穿越到《权游》中的赫敏,竟然是龙妈???
![]()
新智元报道

新智元报道
【新智元导读】最近,Stable Diffusion已经掀起一股热潮。让我们看看《哈利·波特》中的人物进入《权力的游戏》中,会变成什么样子?

哈利·波特变权游
Prompt: !dream “emma watson as hermione granger in game of thrones “ -n 4 -i -S 3220803958

Prompt: !dream “Daniel Radcliffe as Harry Potter in game of thrones “ -n 5 -i -S 1325472740

Prompt: !dream “rupert grint as ron weasley in game of thrones “ -n 5 -i -S 2721137669

Prompt: !dream “lord voldemort in game of thrones “ -n 5 -i -S 2427598534

Prompt: !dream “ian mckellen as gandalf in game of thrones “ -n 5 -i -S 2948575077

10步带你理解Stable Diffusion
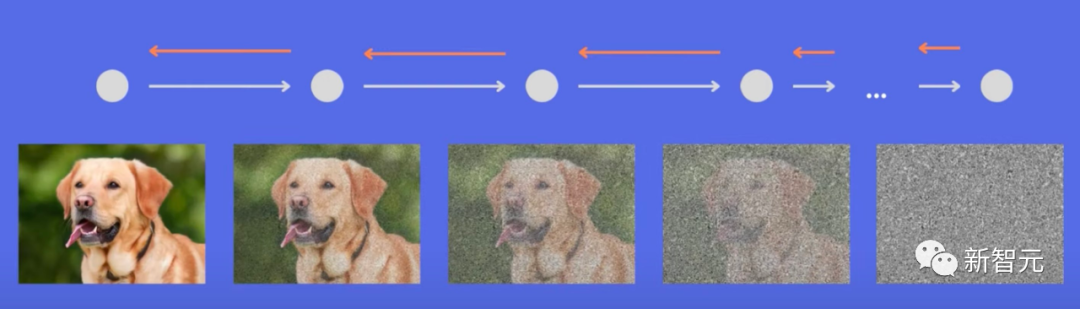

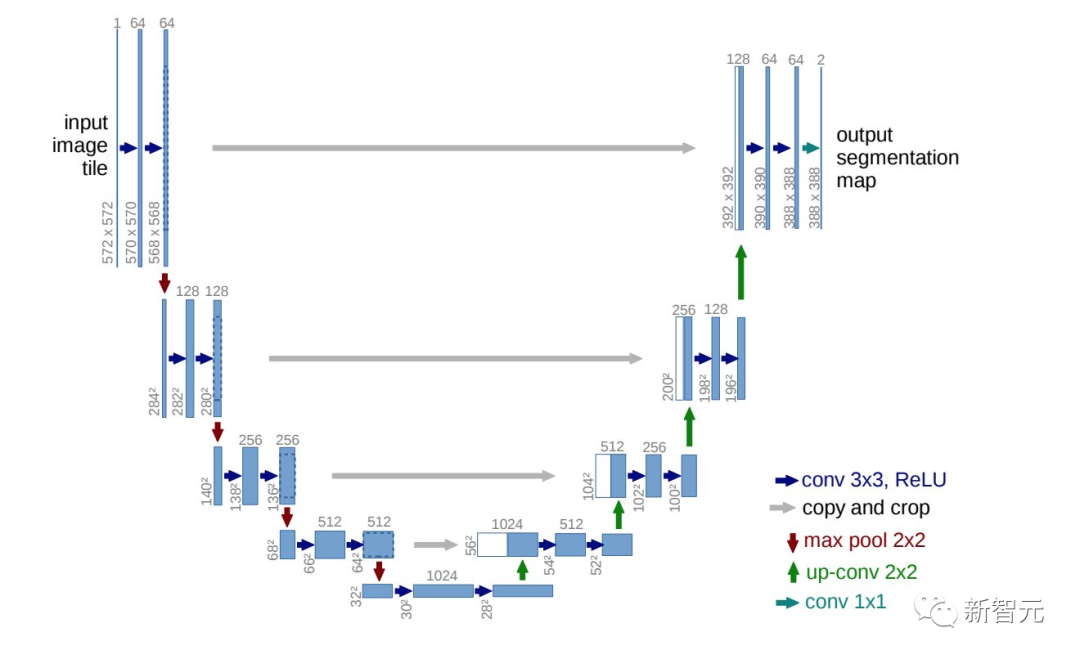




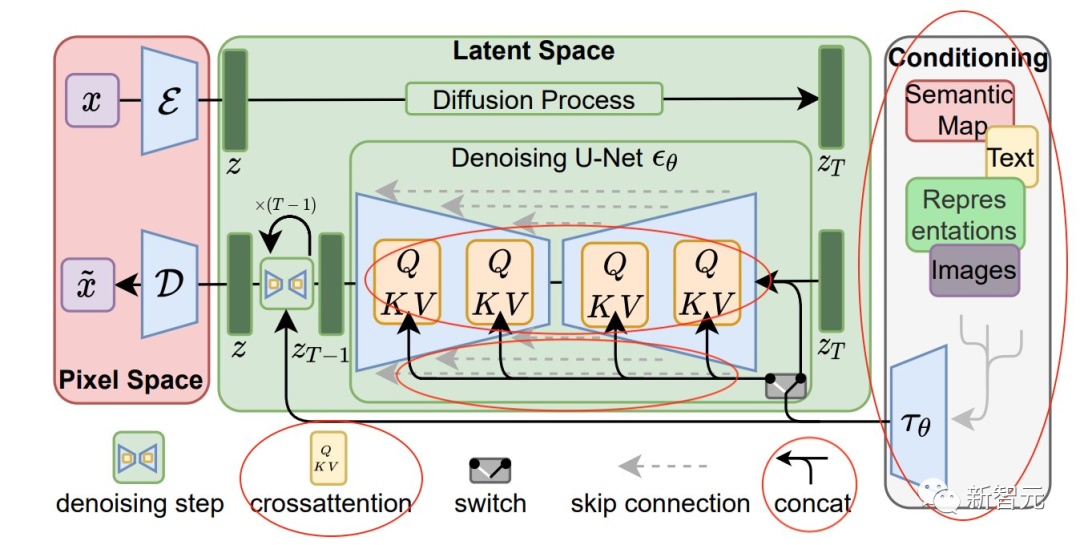



模型完全公开了!

团队表示,v1.4的推荐权重是470k,比提供给研究人员的v1.3的440k,多了几个训练步骤。
目前,模型仅支持英伟达显卡,最终占用的显存为6.9Gb。
在接下来的时间里,团队还将持续发布模型的优化版本,以及更多性能和质量得到改善的变体和架构。
之后,Stable Diffusion模型也将能够在AMD、苹果M1/M2和其他芯片组上运行。



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月22日
Arxiv
12+阅读 · 2021年12月28日
Arxiv
16+阅读 · 2020年3月30日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月22日
Arxiv
12+阅读 · 2021年12月28日
Arxiv
16+阅读 · 2020年3月30日