点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:机器之心 |
作者
:He Zhang等
图像合成是指组合不同图像中的部分区域以合成一张新的图像,一个常见的用例是肖像图片的背景替换。为了获得高质量的合成图像,经常需要专业人员手动执行多个编辑步骤,例如图像分割、抠图、前景色彩去污,即使使用复杂的图像编辑工具,这些步骤也是非常耗时的。
近日,Adobe 联合约翰霍普金斯大学的研究者提出了一种
无需用户输入即可生成高质量合成图像的新方法
。该方法能够进行端到端的训练,以优化对前景和背景图像上下文和颜色信息的利用,其中在优化过程中考虑了合成质量。
具体而言,受拉普拉斯金字塔融合(Laplacian pyramid blending)的启发,该研究提出一种密集连接的多流融合网络,以有效融合来自不同前景和背景图像的信息。
此外,该研究还引入了一种自学式(self-taught)的策略,以逐步训练从简单到复杂的用例,进而弥补训练数据不足的问题。实验表明,该方法能够自动生成高质量的合成图像,并在定性和定量评估中均优于现有方法。
![]()
论文链接:
https://arxiv.org/pdf/2011.02146.pdf
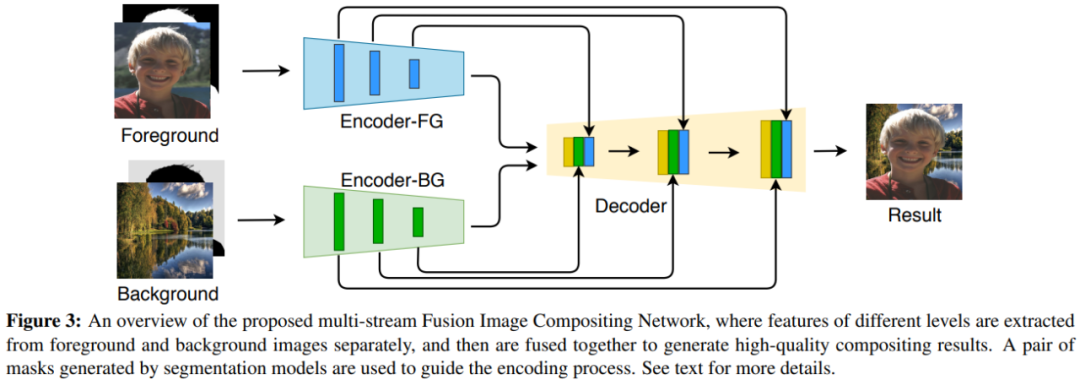
该研究提出了一种基于深度学习的图像合成框架,可以在给定一对前景和背景图像的情况下直接生成合成的肖像图像。前景分割网络与细化网络一起用于提取肖像蒙版。基于肖像蒙版,研究者又提出了一种端到端多流融合(MLF)网络,从而以不同比例合成前景和背景图像。
MLF 网络的设计思想来自拉普拉斯金字塔混合方法。
它使用两个编码器分别提取前景和背景图像的不同级别的特征图,然后通过解码器逐级融合,以重建最终的合成结果。该方法是全自动的,着重于缓解由于前景遮挡和颜色净化不完善导致的边界伪影。大体而言,该论文解决了图像合成中颜色、外观协调的正交问题。
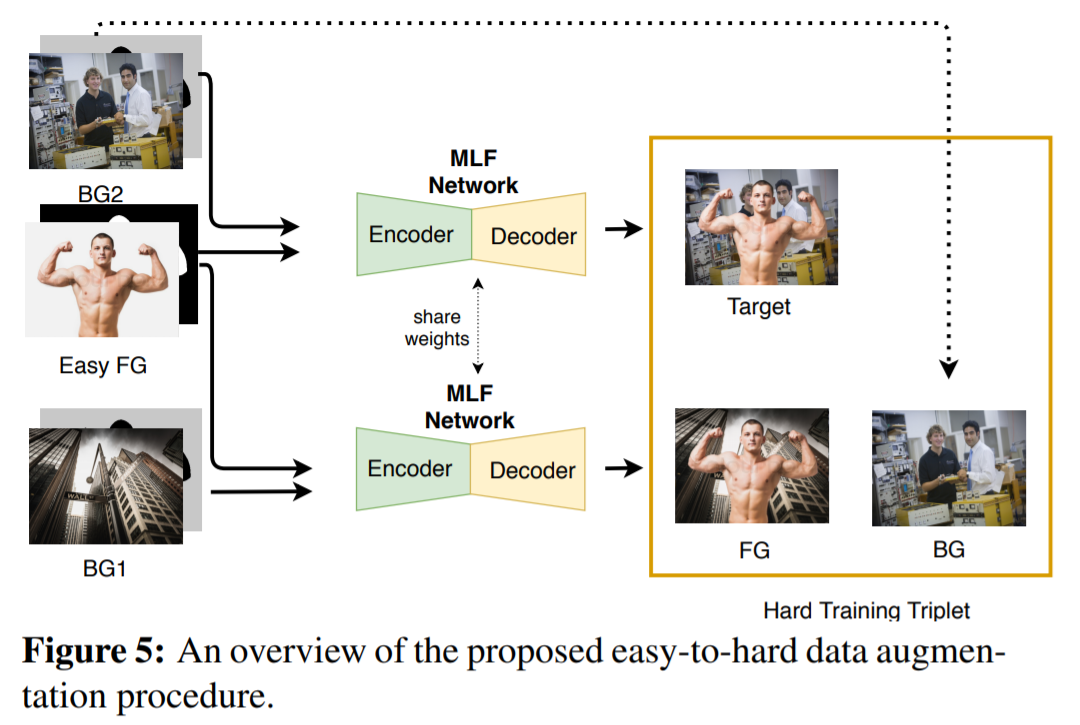
此外,该研究提出了一种从易到难的自学式数据增强方案,以生成用于训练 MLF 网络的高质量合成数据。基本思想是使用在更简单数据上进行训练的 MLF 网络,以组合更具挑战性的训练数据来实现性能提升。
![]()
在合成图像和真实图像上评估的实验结果表明,该方法较以往方法更加有效。用户研究的结果也验证了该方法卓越的感知质量。
虽然在该论文中仅将其实现用于肖像合成,但该框架是通用的。研究者也希望将其用于其他图像合成的应用。
该框架将一对前景和背景图像作为输入,并生成合成图像。它由三个部分组成:前景分割网络、蒙版细化网络和多流融合网络。、
首先,分割网络自动从前景图像中提取对象蒙版,然后蒙版细化网络将图像和蒙版作为输入以细化蒙版边界,最后将重新定义的蒙版和前景背景图像一起传输到多流融合网络以生成合成结果。
![]()
为了训练多流融合(MLF)网络,每个训练样本都是三元组 [FG、BG、C]。其中 FG 是前景图像,BG 是背景图像,C 是 FG 和 BG 的目标合成图像。研究者希望 MLF 网络学习在 FG 和 BG 之间产生视觉上的最佳合成效果,因此目标图像 C 的质量是该方法的关键。但是手动创建高质量的合成数据集需要专家级的人工操作,这就限制了训练数据收集的可扩展性。
为了解决该问题并生成无需人工干预就能进行大规模图像合成的数据集,该研究提出了一种使用自学式方案且易于处理的数据扩展方法。基本思想是使用 MLF 网络生成更具挑战性的数据以提升自身性能。
该研究首先在一些简单的三元组上训练 MLF 网络,其中前景图像 FG 是具有简单彩色背景的肖像图像。然后收集了很多这样的简单肖像图像,并使用 MLF 网络为下一个训练阶段生成更具挑战性的训练三元组。
![]()
下图为自学式数据增强算法生成的三元组(前景、背景和目标)图像,可以看出,该算法可以生成近乎完美的高质量目标图像。
![]()
研究者通过定量和定性评估来评估该深层图像合成方法,并进行了用户研究,以评估用户对合成结果的感知质量偏好。最后,该研究还进行了一些控制变量实验。实验所用数据集:DUTS、MSRA-10K 和 Portrait 分割数据集。该研究在这些数据集上训练了分割和细化网络。在实现细节上,细分和优化模块通过 ADAM 算法进行了优化,学习速率为 2×10^−3,批处理大小是 8。所有用于细分和优化模块的训练样本均调整为 256×256。
该论文提出的方法与传统基于混合的合成方法(如拉普拉斯金字塔混合法)进行了比较。该研究还使用了 SOTA 抠图方法评估基于抠图的图像合成方法。此外,该研究还比较了一种称为复制粘贴(copypaste)的基线方法,该方法将从细化分割模块估计的细化分割蒙版用于该合成的软 alpha 蒙版。
为了公平比较,所有被比较的方法都使用与该方法相同的细化蒙版。对于羽化(feathering)方法,研究者采用σ=2 的高斯模糊来软化蒙版。对于拉普拉斯金字塔混合方法,该研究使用 OpenCV 实现。由于基于抠图的方法需要三元图(trimap),因此研究者对细化模板进行了二值化处理,然后通过将宽度为 16 的窄边界带标记为未知边界来生成伪三元图。
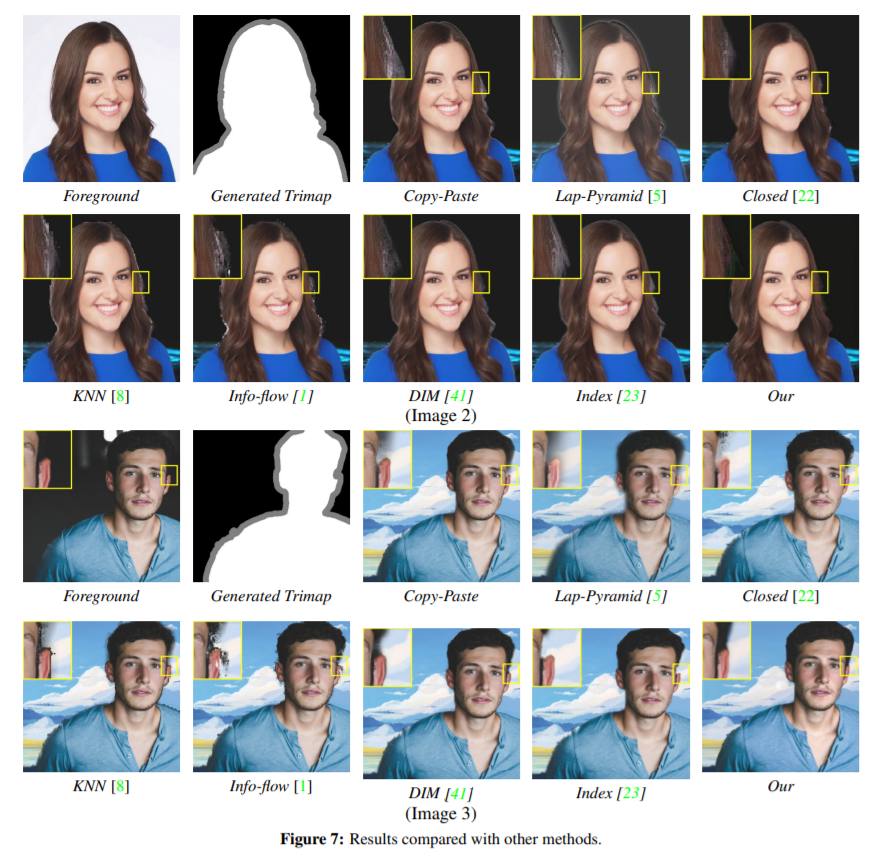
样本三元图以及各种方法的生成效果如下图 7 所示。需要注意的是,在基于抠图的合成方法中采用了自动消色算法,以提高其合成质量。
![]()
如下表 1 所示,该研究根据合成数据评估的定量结果证明了该方法的有效性。注意:定量结果仅在未知区域上计算得到。
![]()
此外,与其他方法对比的用户研究结果如下表 2 所示:
![]()
研究者进行了 3 次控制变量实验,在 SynTest 上的定量结果如下表 3 所示。其中 w/o-DataAug 代表没有使用该方法的数据扩展而训练的的网络,Single-Enc 代表一个具有单流编码器的网络,w/o-RefNet 代表没有分割细化的网络的基线。该评估结果是仅在未知区域上得到的。
![]()
![]()
下载:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!![]()