你玩《2048》能拿多少分?AI的最高分纪录:401912

来源:量子位
如果让AI来玩《2048》这样的游戏,那会是怎样一种画面?
现在,有人用强化学习方法实践了起来。
于是,插上DQN的翅膀,AI从零起步,自己琢磨出了《2048》的玩法:

一起手,是不是就有内味了?
这操作,条理清晰到令人感到舒适。“1000,no;1024,yes”的强迫症们不禁纷纷点赞,给这只AI贡献了800+ reddit热度。

用DQN玩《2048》
调教出这只会玩《2048》的AI的,是一位巴西老哥Felipe Marcelino。目前正在米纳斯吉拉斯联邦大学攻读CS硕士。
首先,他采用OpenAI Gym构建了自定义强化学习环境。
其中包括两种2048棋盘表示方式:
二进制——使用二次幂矩阵表示棋盘中的每一块区域
非二进制——原始数字矩阵
模型包含两种类型的神经网络:CNN和MLP(多层感知机)。

据Felipe介绍,与MLP相比,以CNN作为特征提取器的智能体表现得更好。
训完之后,老哥测试了一下,在1000把游戏中,AI有100次达到了2048。
玩《2048》的AI们
目前,这只用DQN训练出的AI玩到2048就打住了。
不过,巴西老哥抛砖,又吸引了不少来献玉的盆友。
比如,同样采用强化学习方法,将时序差分学习和最大期望搜索相结合的2048控制器。
在10步/秒的策略下,它最高能凑出32768。

而在追求高分的路上,有一位来自日本的选手表现亮眼。
依靠7个卷积层的深度卷积网络,这只在《2048》这个游戏中最高拿到了401912分。
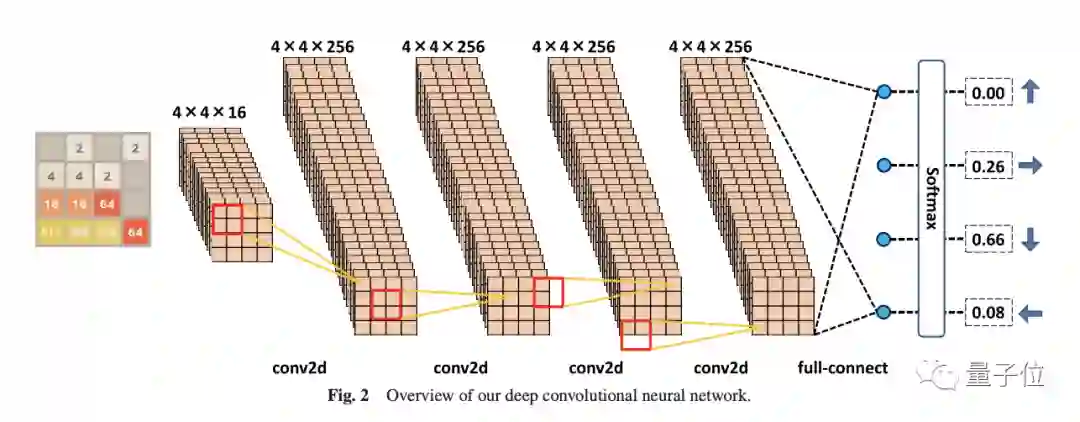
正如一位网友所说:这正是一个足够有趣,又不太复杂的强化学习案例。

如果你是刚刚开始学习强化学习,也不妨拿这个小项目练练手~
参考链接
《2048》相关开源项目:
https://github.com/FelipeMarcelino/2048-gym
https://github.com/aszczepanski/2048
https://github.com/thomasahle/mcts-2048/
相关论文:
https://www.jstage.jst.go.jp/article/ipsjjip/27/0/27_340/_pdf
http://arxiv.org/abs/1604.05085
——END——







