深度文本的表征与聚类在小样本场景中的探索


文章作者:吕媛媛
内容来源:58技术公众号
出品平台:DataFunTalk
注:转载请联系原作者。
导语
背景
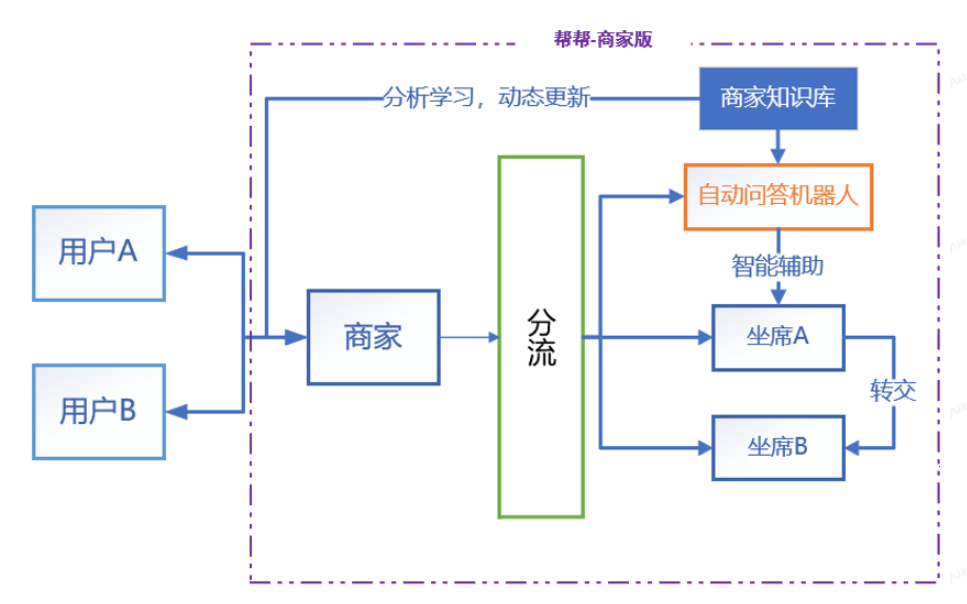
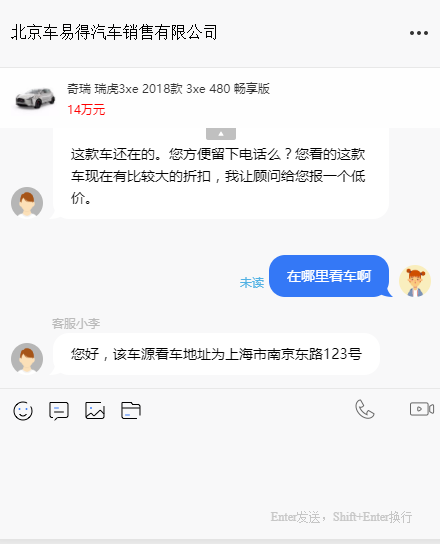
图2 自动问答机器人单轮问答示例
自动问答机器人单轮问答的开发流程如图3所示。大致分为两个阶段:问题挖掘阶段和模型迭代阶段。
第一阶段:在问题挖掘阶段,主要有三个步骤:第一步问题获取,从微聊之前积累的离线聊天数据提取出用户侧常问问题;第二步问题聚类,使用K-means进行聚类;第三步标准问题,扩展问题总结,这步结合聚类结果以及编辑人员的集体智慧拟定标准问题和扩展问题。
第二阶段:在模型迭代阶段,主要有两个步骤:第四步匹配模型的训练以及第五步线上效果测评,匹配模型使用第三步总结出的标准问题和扩展问题训练问题多分类模型,当模型离线训练性能达标后,会上线模型,模型上线之后进行线上效果测评,主要观测准确率和召回率,第六步新问题挖掘会对线上漏报以及误报的case进行挖掘,返回到图中第三步标准问题以及扩展问题总结进行迭代。
新问题的发现挖掘,对线上效果迭代至关重要,本文工作主要围绕图中第六步新问题挖掘展开。
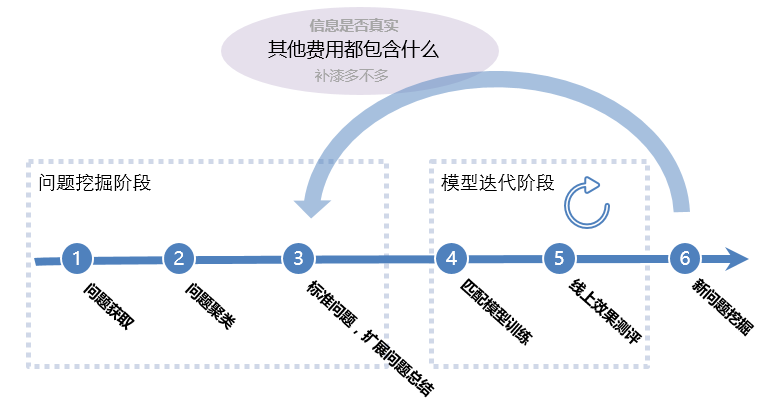
图3 自动问答机器人单轮问答开发流程图
文本表征和聚类
基于对以上两个问题和场景特点的思考,在算法上要解决两个问题,一个是如何在小样本场景表征问题,能够捕获不同问法的同一语义,提高泛化能力;一个是如何发现和挖掘新的问题,提高机器人对线上问题的覆盖度。具体到应用场景,就是标准问题的挖掘和扩展问法的发现,标准问题挖掘解决覆盖度的问题,扩展问题问法发现解决匹配准确性的问题。针对这些问题,我们尝试了基于Bi-LSTM的预训练语言模型和深度聚类算法DEC(Deep Embedded Clustering)[1],并结合二者对原始DEC算法做了改进。
本章节主要介绍为了提升小样本场景下分类模型的线上效果所做的新问题挖掘工作(包括标准问题挖掘和扩展问题问法发现两个落地场景),首先阐述应用的两个算法:一是基于Bi-LSTM的预训练语言模型,二是深度聚类算法DEC,最后介绍上述算法在58二手车场景的探索。
1、基于Bi-LSTM的预训练语言模型
在模型构建初期,我们使用K-means来挖掘知识,结合编辑人员的集体智慧拟定标准问题,在初版模型上线后,我们发现定义的标准问题覆盖度不够高,主要是因为K-means方法表征能力弱,对腰部问题挖掘能力不够强。针对小样本数据表征能力弱的问题,我们使用预训练语言模型来解决。
考虑到二手车场景有大量无标签数据,我们借鉴BERT[5] Masked LM 预训练任务的思想,训练了基于Bi-LSTM的预训练语言模型,结合场景特点,我们对原始BERT预训练任务做了如下修改:
A、简化预训练任务。BERT paper 使用的预训练任务有两个:Masked LM 和Next Sentence Prediction,考虑到后续使用场景主要针对句子表征,而不涉及句子间关系,所以我们只保留了Masked LM 任务。
B、使用Bi-LSTM替代transformer[6]做特征提取。BERT的成功等于良好的算法加上超强算力,BERT原始预训练任务使用64个TPU训练了4天完成,这样的算力要求较高,于是我们思考,在预训练模型性能和训练成本上做trade-off。我们尝试使用Bi-LSTM 替代transformer 做特征提取,使用了4千万基于二手车场景的无监督数据,最终该模型在一块NVIDIA TESLA P40 GPU上,完成30万次迭代用时28小时。为了测试预训练模型的效果,我们在二手车场景分类问题上对比实验了Bi-LSTM预训练模型以及BERT中文预训练模型的效果,分类模型样本量2.6万条,实验结果如表1所示, 结果显示,加载Bi-LSTM预训练模型后,分类模型acc从0.81提升至0.86;而在同样加载预训练模型的情况下,基于垂直场景数据的预训练模型比BERT通用预训练模型acc绝对高出0.013。
| Bi-LSTM |
BERT | |
| +Pretrain model Acc | 0.8662 | 0.8487 (5 epoch ) 0.8530 (10 epoch ) |
| No Pretrain Model Acc | 0.8107 |
0.7884 (5 epoch ) 0.8342 (10 epoch ) |
表1 二手车分类问题预训练模型accuracy对比
训练好的Bi-LSTM 预训练模型将用作后文DEC算法中的特征表征。
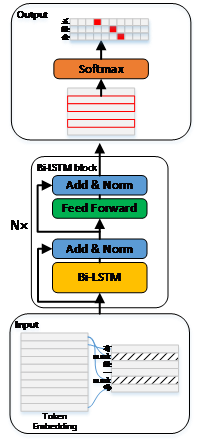
传统聚类的方法例如K-means、GMM、谱聚类已经在工业界有广泛的使用,但是这些算法里少有考虑到学习适合聚类的特征表征,DEC算法正是将特征的表征与聚类中心分配一同学习。
DEC是两阶段训练模型。第一个阶段训练autoencoder作为初始特征表征,第二阶段利用训练好的encoder 部分与聚类中心的分配(cluster assignment)一起做fine-tune,这样同时优化encoder以及聚类中心的分配,使得两个任务可以互相促进互相学习。算法流程如图5所示。
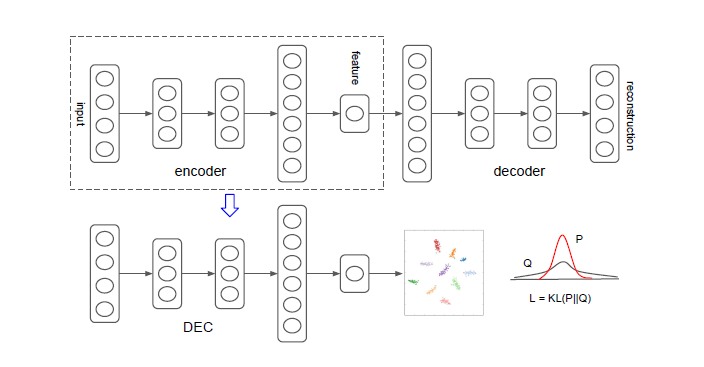
图5 DEC算法流程图
2.1、Soft Assignment
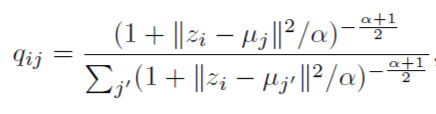
2.2、KLD Divergence Minimization
在得到特征表征之后,使用K-means方法初始化聚类中心,DEC设计了一种理想分布p,p分布的表达如下图:选择p分布主要为了强化高置信的部分以及规范化每个聚类中心的loss损失贡献,所以训练过程就是通过优化KL散度(Kullback-Leibler Divergence, KLD)不断优化p, q两个分布之间的差异的过程。
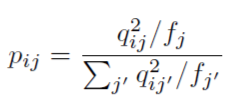
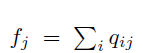
3、深度表征与聚类在58二手车场景应用
在二手车业务线,我们在两个场景考虑Bi-LSTM预训练模型作为特征表征的DEC算法并且在扩展问题问法发现场景改进了DEC原始算法。
3.1、标准问题挖掘
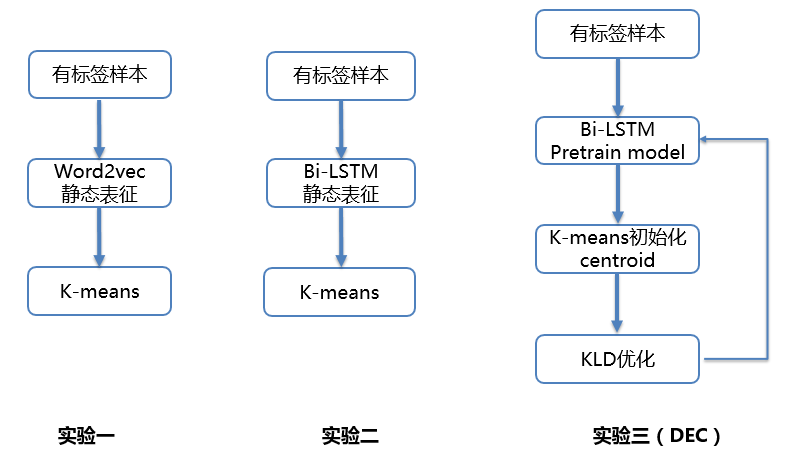
图6 对比实验说明
accuracy |
silhouette |
runtime |
|
K-means + Word2vecRepresentation |
0.354 |
0.047 |
<5min |
K-means + Bi-LSTMRepresentation |
0.377 |
0.025 |
<5min |
DEC + Bi-LSTMpretrain model |
0.8437 |
0.142 |
30min |
表2 K-means DEC 对比测评效果
| 可回答率 |
|
| 迭代前 |
79.71% |
| 迭代后 |
83.62% |
表3 可回答率周平均变化
3.2、扩展问题发现
在模型上线后,我们对线上badcase进行了分析,发现对于一些已定义标准问题,由于线上query表达方式(utterance)变体较多,而没能准确匹配到相应标准问题的case占比很大,比如表示询问价格,离线训练数据里多为标准表达方式“价格是多少?”,“**多少钱?”,但是因为用户语言习惯甚至方言的问题,有很多口语化表达,比如“几个钱?”,“多钱?”等,我们就在思考,如何能针对目前已定义好的标准问题来从线上数据中挖掘相似的问题作为离线训练数据的补充?在二手车场景下相比有监督数据,无监督数据的体量更大,如何利用已有的少量有监督数据来泛化更多的无监督数据?带着这两个问题的思考,我们尝试对DEC 算法进行了改进,在原始的DEC算法中,唯一的有监督信号是由K-means做聚类中心初始化时给到的,后续的训练过程实际上是对这个分布的高置信部分做强化,可以说,聚类中心初始化的效果决定着整个DEC算法的效果,但是K-means的聚类结果有很强的随机性,所以我们使用自定义聚类中心替代了原始DEC算法中K-means聚类出的聚类中心,使用已有的标准问的所有扩展问法向量的平均作为该标准问的向量,也就是自定义的聚类中心,这样DEC后续学习到的数据分布是按照目前已拟定的标准问题作为聚类中心得到的。在使用改进DEC 扩充了已有标注数据的扩展问法后,线上问答模型分类效果如表4所示,周测评准确率从98.11%提升至98.24%;召回率从89.66%提升至92.27%。在准确率基本持平的情况下,召回有了明显提升,说明迭代后有效召回了一批原来无法识别的语义上相似的问法。
| 迭代前 |
迭代后 |
|
| precision |
98.11% |
98.24% |
| recall |
89.66% |
92.27% |
表4 改进DEC 迭代效果对比
总结展望
在智能客服商家版自动问答机器人新问题挖掘模块,为了解决小样本场景下数据表征能力弱,聚类纯度不高的问题,我们尝试了如下改进:1 改进了BERT 预训练任务,充分利用垂直场景数据训练了基于Bi-LSTM的预训练语言模型,以提升场景的文本表征能力;2 将原始DEC算法做了自定义聚类中心的改进,使得后续的训练朝着人工标注数据分布的趋势来进行训练,强化分布。在二手车场景几个观测指标上均有明显提升。
未来可以从以下几个方面进一步提升Bi-LSTM预训练语言模型和无监督深度聚类算法DEC的性能:可以针对线上线下数据分布差异引入迁移学习;设计更好的表征网络,比如可以针对场景设计更加合适的无监督目标函数;引入self-supervision task;我们坚信,未来对于无监督方向的算法会有更多突破与落地。
今天的分享就到这里,谢谢大家。
如果您喜欢本文,点击右上角,把文章分享到朋友圈~~
欢迎加入 DataFunTalk NLP 技术交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker),回复:NLP,逃课儿会自动拉你进群。
参考文献
1. Xie, Junyuan, Ross Girshick, and Ali Farhadi. "Unsupervised deep embedding for clustering analysis." International conference on machine learning. 2016.
2. Aggarwal, Charu C., and ChengXiang Zhai. "A survey of text clustering algorithms." Mining text data. Springer, Boston, MA, 2012. 77-128.
3. Aljalbout, Elie, et al. "Clustering with deep learning: Taxonomy and new methods." arXiv preprint arXiv:1801.07648 (2018).
4. http://ai.stanford.edu/blog/weak-supervision/
5. Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
作者简介
吕媛媛,58同城AI Lab算法高级工程师,2018年5月加入58同城,目前主要负责智能客服商家版算法研发工作,曾先后从事过推荐算法研发、智能客服自动问答算法研发,2016年硕士毕业于北京邮电大学,曾就职于美团。
——END——
文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章400+,百万+阅读,5万+精准粉丝。

一个在看,一段时光!👇





