LeCun转推,PyTorch GPU内存分配有了火焰图可视化工具

极市导读
想要了解自己的 PyTorch 项目在哪些地方分配 GPU 内存以及为什么用完吗?不妨试试这个可视化工具。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
 Twitter@Zachary DeVito
Twitter@Zachary DeVito
生成快照




保存快照


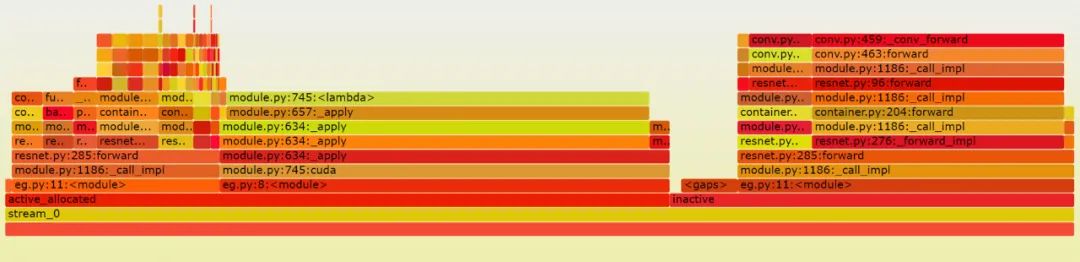
可视化快照


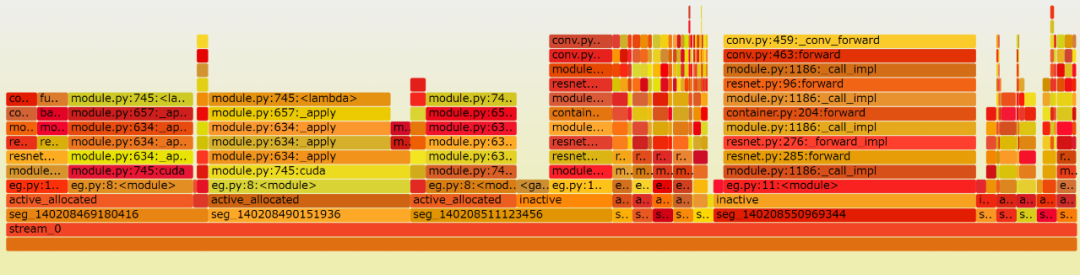
比较快照


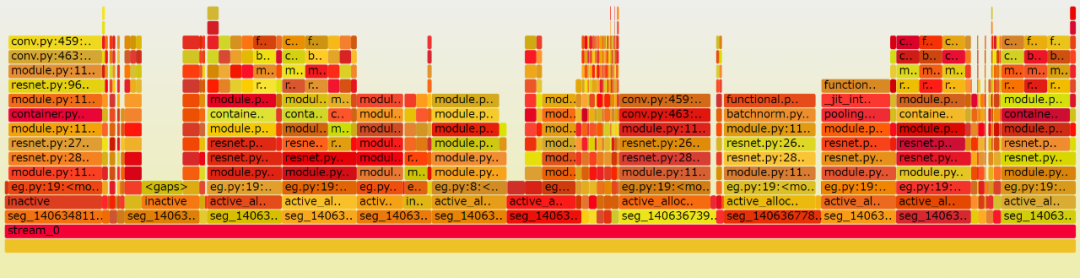
$ python _memory_viz.py compare snapshot.pickle snapshot2.pickle -o compare.svgonly_before = []only_after = [140636932014080, 140636827156480, 140634912456704, 140634839056384, 140634843250688, 140634841153536, 140634866319360, 140634811793408, 140634845347840, $ 140636806184960, 140636778921984, 140634878902272]

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
极市&深大CV技术交流群已创建,欢迎深大校友加入,在群内自由交流学术心得,分享学术讯息,共建良好的技术交流氛围。
“
点击阅读原文进入CV社区
收获更多技术干货
登录查看更多
相关内容
Arxiv
1+阅读 · 2022年12月15日


相关VIP内容
相关资讯