






关于「AI投研邦」
雷锋网旗下会员组织,聚焦AI+10大领域 :AI+汽车(智能驾驶)、AI+教育、AI+金融、AI+智慧城市、AI+安防、AI+医疗等。仅剩199个早鸟席位,欢迎加入。
▲点击上方 雷锋网 关注
文 | 任然
来自雷锋网(leiphone-sz)的报道
NVIDIA对SoC的设计并不陌生,到目前为止他们已经发布了7代Tegra系列SoC。
在过去几年中,NVIDIA逐渐从消费级的Tegra产品转换到更专业的AI等高性能移动计算平台。经历了Tegra K1和Tegra X1的过渡,Tegra Parker(即NVIDIA Drive PX)终于带着改良版的Denver2架构成功登上了自动驾驶的舞台。虽然产品已经脱离了大多数消费者,但它们仍然是非常给力且有趣的SoC平台,拥有许多我们至今没有在其他设备中看到的奇妙设计。
去年,NVIDIA推出了新一代Jetson AGX平台,瞄准机器人和工业自动化等AI神经网络用例。这是一款功能齐全的小型计算系统,Xavier芯片本身设计为完整的商业现货(COTS)系统,整个平台的尺寸不超过105mm x105mm。
当然光有裸模块什么也干不了,你无法对着一个裸模块进行开发,还需要NVIDIA提供的完整Jetson AGX开发套件。Jetson AGX开发套件提供了模块运行所需的一切,包括电源、散热器,以及一块非常重要的分接板。这块分接板提供各种I/O接头和端口,从标准的双USB Type-C 3.1、HDMI和千兆以太网端口,到用于相机连接的MIPI CSI-2连接器等更专业的接口,以及40pin GPIO连接器等一系列典型的开发板接头。
Jetson AGX最厉害的地方在于,其提供了PCIe Gen4 x16以及M.2 PCIe x1通用扩展插槽,可用于连接WiFi或蜂窝网络模块等附加设备,可为傲视群雄。这两种功能在其他Arm开发板中极为罕见,因为大多数SoC都没有集成PCIe控制器。
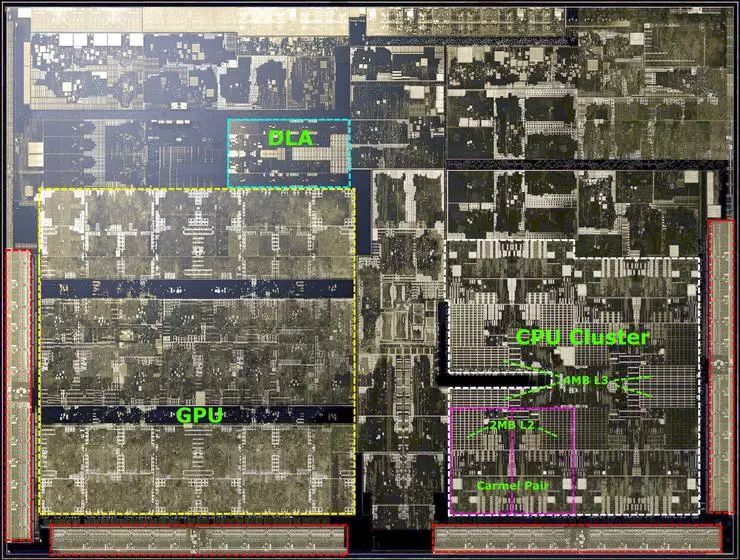
Jetson AGX拥有一块分量十足的铝制散热片,平台的灵魂——Xavier芯片就位于下方。Xavier芯片作为系统的大脑,是NVIDIA迄今为止最大、最复杂的SoC,是Arm生态系统的重量级产品之一,在350mm²的面积上集成了90亿晶体管。Xavier芯片的四周围16GB LPDDR4X内存、32GB eMMC闪存以及供电模块等其他核心组件。
来自传统的PC行业的NVIDIA毫不避讳的自行展示了Xavier芯片的透视电路图,这样大方且自信的态度,在Arm SoC供应商中非常罕见。Xavier芯片主要由NVIDIA自研的Carmel架构8核64位CPU和Volta架构512 CUDA处理器GPU这两大模块组成,这两部分电路占据了芯片的大部分空间。
8个CPU核心被平均分配为4个集群,每个集群都有一个独立的时钟平面,并在2个CPU核心之间共享2MB L2缓存,在其之上,4个集群共享4MB L3缓存。目前关于全新Carmel架构的信息很少,只知道它是之前Denver架构的继任者,其设计特点是强大的动态代码优化能力。NVIDIA只对外表示Carmel是一个10宽度的超标量架构(10个执行端口,非10宽度解码),并且支持ARMv8.2+RAS指令集。
Xavier的GPU源于Volta架构,内部结构被划分为4个TPC(纹理处理集群),每个TPC具有2个SM(流式多处理器),每个SM集成64个CUDA核心(即流处理器),共计512个CUDA核心,其单精度浮点运算性能为2.8Tflops,双精度为1.4Tflops。此外Xavier还从Volta那里继承了Tensor Core,其8bit运算性能为22.6Tops,16bit运算性能为11.3Tops。
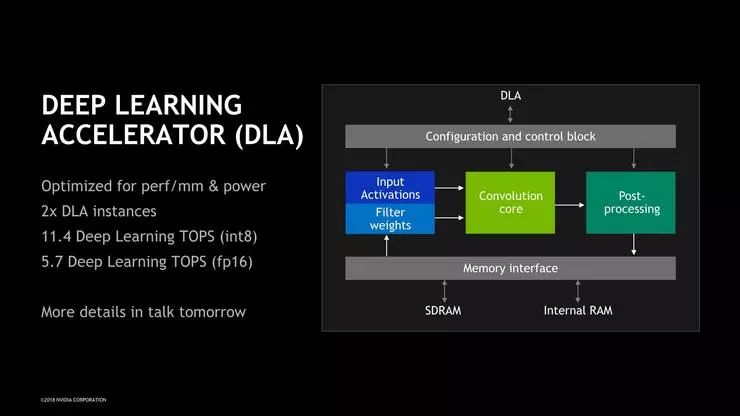
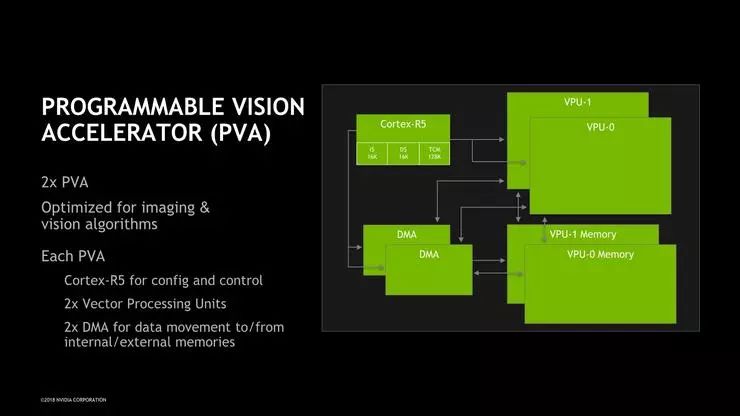
除了CPU和GPU,Xavier内还设计有全新的DLA(Deep Learning Accelerator,深度学习加速器)和PVA(Programmable Vision Accelerator,可编程视觉加速器)单元,其中DLA是一种新型的机器推理加速专用单元,其INT8计算性能高达11.4Tops;PVA则是一种更传统的视觉计算单元,在视觉管道中位于ISP之后,它能以比GPU或DLA更高效的处理对象检测等基本任务,将图像分割成对象后转发到GPU或DLA上进行后续处理。
Xavier的核心竞争力是其机器推理性能,Volta GPU与DLA核心相结合,在低功耗平台上构筑了强大的处理能力。
为了展示该系统的机器学习推理能力,NVIDIA为Jetson AGX平台提供了大量软件开发套件以及手动调整框架,特别是TensorRT框架,预先为开发者做了大量繁重的准备工作,使他们能充分利用GPU中的Tensor Core和DLA单元。
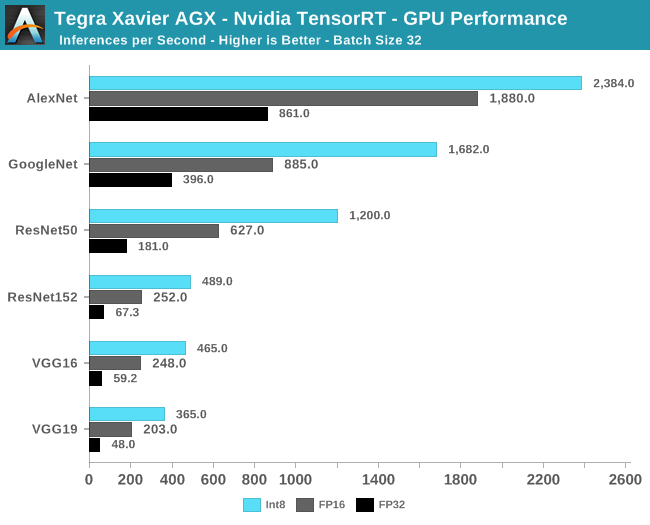
NVIDIA还准备了一套主流的机器学习模型,让开发者能够根据模型在平台上的运行方式来精确调节配置。在CUDA核心和Tensor Core上运行的所有模型都能够以量化的INT8、FP16或FP32格式运行,批处理大小也可自由配置,但本次测试只简单展示批量大小为32张图像的结果。
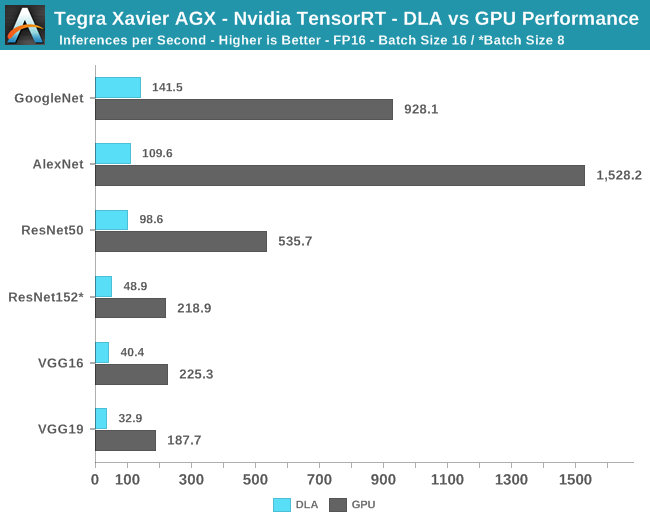
GPU基准测试的结果有点“玄”,从数据是可以清楚地看出,Xavier的推理性能绝对值相当高,在INT8模式下高达每秒465次推理,FP16和FP32模式下也分别达到每秒248次和59次。
之所以说“玄”,是因为目前几乎没有可以与Xavier对比的参考数据,唯一比较相近的是苹果A12处理器评测中的AImark测试,在VGG16测试项中,A12的NPU性能为每秒39次推理。虽然不知道AImark的VGG16测试使用的是哪种精度,但即便是拿Xavier最慢的FP32精度的成绩来比,二者的差距依然相当明显(要知道A12可是7nm最新工艺的产物,Xavier只是12nm)。
NVIDIA还允许开发者对DLA块进行基准测试,但同时也提醒称,当前版本的TensorRT框架还有些不成熟,因此目前不允许在INT8模式下运行模型,只能在FP16模式下进行比较。此外测试也无法使用与GPU上相同的32尺寸大型批处理运行测试,只能使用较小的16和8尺寸,小尺寸批处理在硬件上的实际处理时间稍短,因而在API端花费的时间会显得相对较长。
乍看之下DLA的性能有点令人失望,不过它的性能只是Volta GPU能的一小部分,原始性能不是DLA的主要任务,它可以作为专门的卸载块,比GPU更高的效率点运行。不幸的是,GPU和DLA之间的功率差异无法直接测量,只能测出GPU在推断工作负载中,峰值性能模式下的平台功耗约为45W。
NVIDIA的VisionWorks演示
NVIDIA的VisionWorks SDK提供了大量示例演示和源代码项目,可以作为商业应用程序的基准,编译演示程序也是轻而易举。
【视频】NVIDIA Xavier测试Demo 1:https://www.bilibili.com/video/av40317774/?p=1
第一个演示展示的是Xavier的特性跟踪功能,为便于测试,输入源是一段预先录制的视频。虽然视频输出限制为30fps,但算法运行速度高达200~300fps,此时Jetson AGX平台的总功耗在14W左右。在算法fps中存在相当多的抖动,这可能归因于在限制fps的输出模式下由于工作负载的持续时间较短而导致的调度噪声。
【视频】NVIDIA Xavier测试Demo 2:https://www.bilibili.com/video/av40317774/?p=2
第二个演示展示的是Hough变换滤波器的应用,这是一个特征提取算法,用于进一步的图像分析。与第一个演示类似,该算法可以在单个视频流上以非常高的帧速率运行,不过在实际环境中通常都是多视频流输入,单个视频流下的性能仅供参考。在这个演示中,平台功耗也在14W左右。
【视频】NVIDIA Xavier测试Demo 3:https://www.bilibili.com/video/av40317774/?p=3
第三个演示展示的是通过运动预判算法确定运动对象的运动矢量,这是汽车应用程序中一个相对简单的用例。
【视频】NVIDIA Xavier测试Demo 4:https://www.bilibili.com/video/av40317774/?p=4
第四个演示展示的是EIS(电子图像稳定)的计算实现,通过给定一个输入视频流,系统将裁剪帧的边缘并使用此空间作为稳定窗口,输出抖动较少的稳定图像。
【视频】NVIDIA Xavier测试Demo 5:https://www.bilibili.com/video/av40317774/?p=5
最一个“DeepStream”演示,也是最令人印象深刻,展示了在25个720p视频流同时输入下,系统对每个视频输入流执行基本对象检测。这种工作负载也是在现实中使用最多案例,能够充分考验Xavier的处理能力。在这一演示中,平台功耗大幅上升至40瓦左右,也在情理之中。
虽然Xavier的视觉计算和机器推理性能非常劲爆,但许多人更感兴趣的则是NVIDIA最新一代Carmel自研架构,这也是目前业界罕见的定制Arm架构之一。
内存延迟
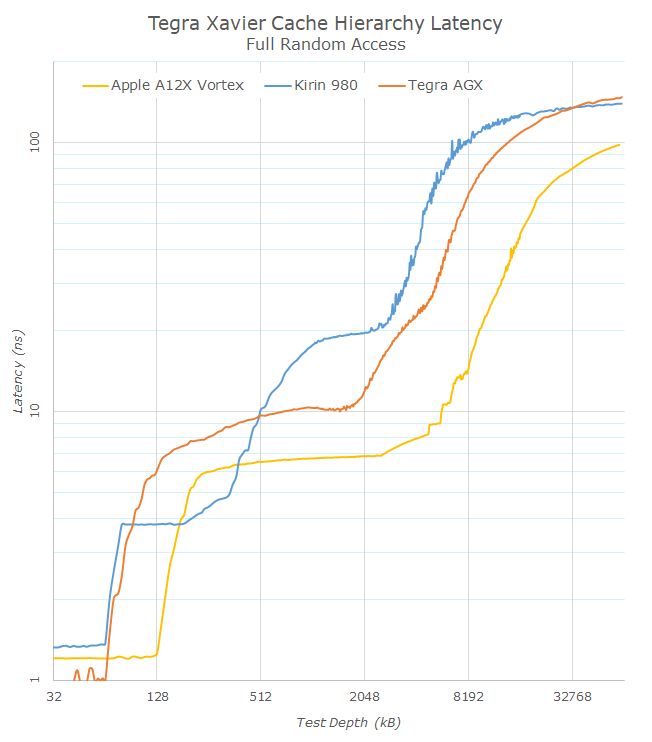
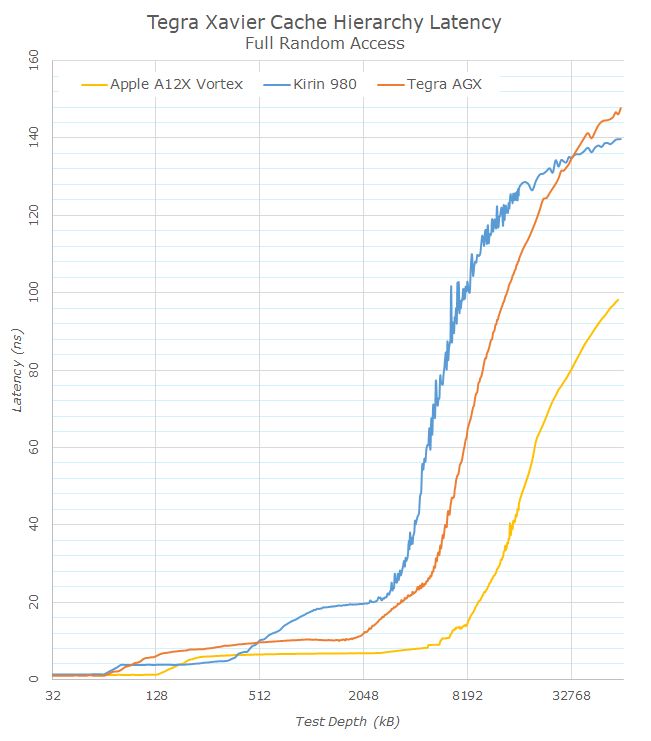
在进入SPEC2006测试之前,先来看看NVIDIA设计的缓存子系统设计,其延迟与Arm阵营中其他平台相比处于何种水平。
在第一项缓存测试的延迟曲线指数图上,可以清楚的看出系统各缓存层次之间的结构级别。Carmel架构拥有64KB L1数据缓存,其延迟居然低至不到1ns,这是非常少见的高水平。在L1缓存之上是2MB L2缓存和4MB L3缓存,其中L3缓存看起来使用了非统一访问的设计,它的延迟随着测试深度增大而持续上升。
切换到线性图表来看,NVIDIA的Carmel架构确实具有优于Arm Cortex A76和Kirin 980的L3缓存延迟。不过这一优势并没有延续到内存控制器的延迟表现上,虽然Xavier配备了256bit LPDDR4X内存控制器,峰值带宽高达137GB/s,比麒麟980的64bit和苹果A12X的128bit都要高,然而得益于巨大的8MB L2缓存和8MB系统缓存,苹果在所有测试深度上都具有巨大的内存延迟优势。这并非是NVIDIA的设计水平不够高,而是7nm堆起缓存来就是这么任性……
SPEC2006测试之单核效能
NVIDIA为Jetson AGX平台提供了一套Ubuntu Linux(18.04 LTS)的定制系统,在测试平台方面拥有很大的灵活性,不过更令人遗憾的是,ARM在Linux上可用的浏览器依然基于缺乏优化的Javascript JIT引擎,导致浏览器性能远远低于其他移动设备。
为了更好的模仿iOS和Android的设置,测试选择了Clang 8.0.0编译器。为了简单起见,测试除使用了-Ofast参数和一个针对Cortex A53的调度模型(它的总体性能比没有模型或针对Cortex A57的要好)之外,没有使用其他任何特殊的标志。
Jetson AGX平台的空载功耗为8.92W,相对较高,这主要是因为其电路板并非为低功耗所优化,且测试中连接了HDMI视频输出。
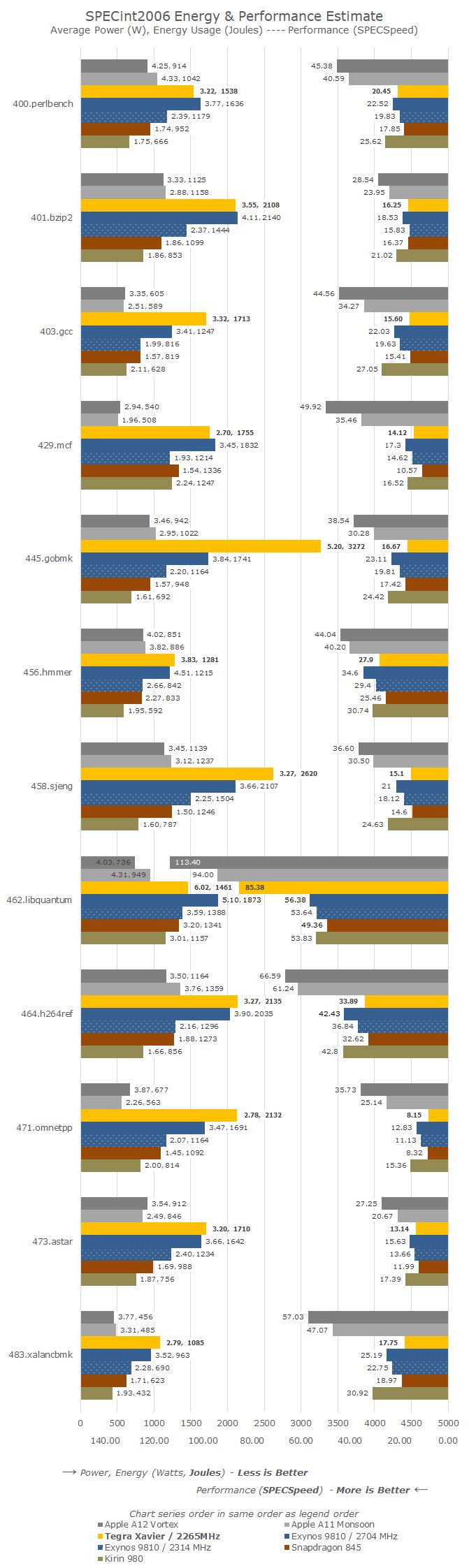
在整数基准测试中,Xavier的性能非常均衡,但并非最强。总体而言,在大多数工作负载下的性能与骁龙845中使用的小改版Cortex A75非常相似,唯一不同的是462.libquantum测试项,Xavier凭借更大的内存带宽跑出了更高的性能。
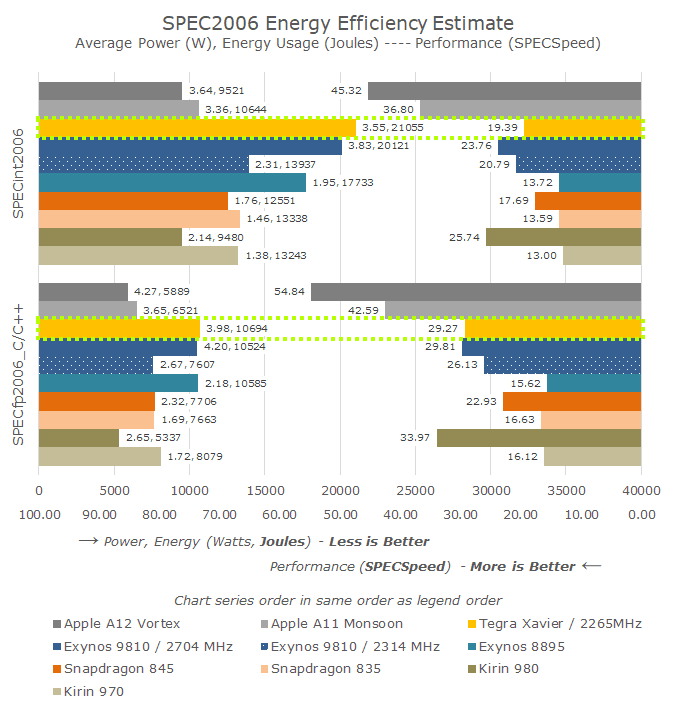
在功耗和能耗比方面,Xavier不是最好的,但也在情理之中。事实上Xavier针对的是一个完全不同的行业,这意味着它的能耗优化取向与手机等移动设备大不相同。而且Xavier所使用的12nm FFN工艺也落后于Exynos 9810年和骁龙845所使用的三星的10nm LPP,更比不上麒麟980和苹果A12所用的最新7nm工艺。
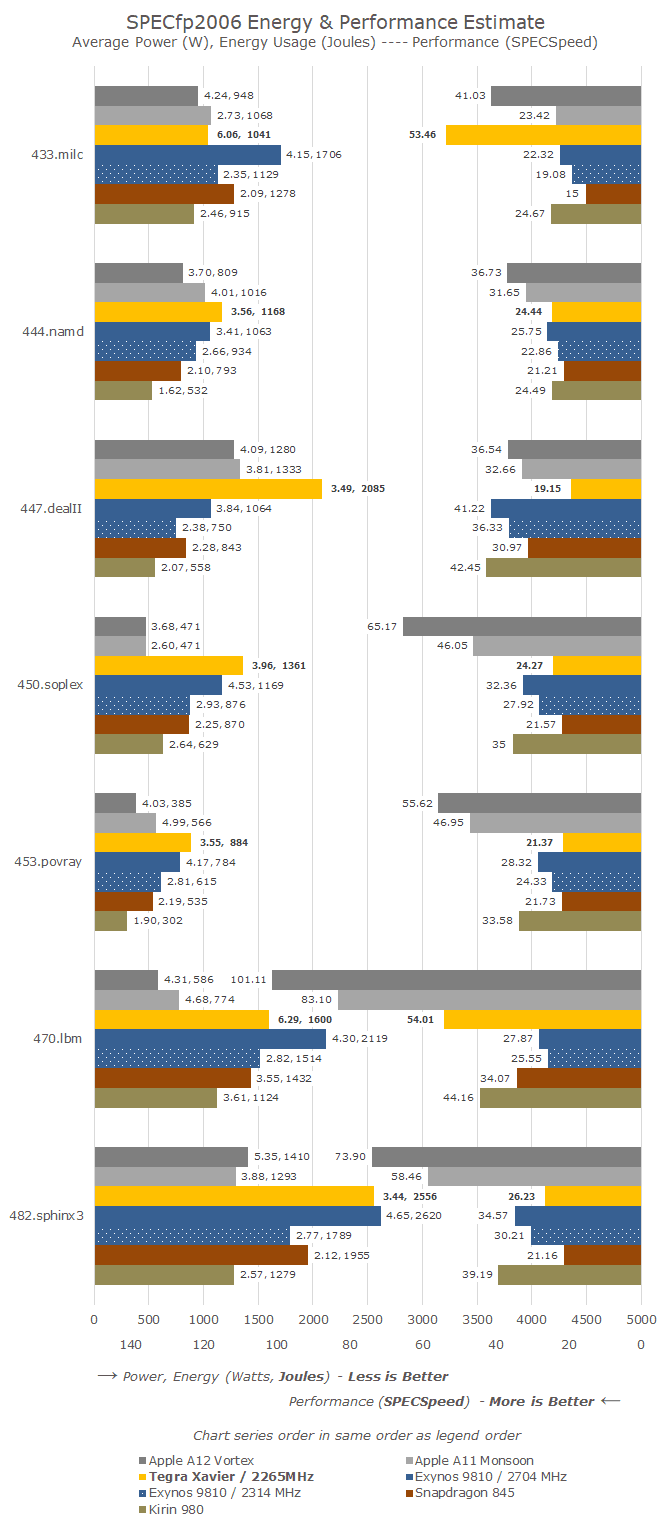
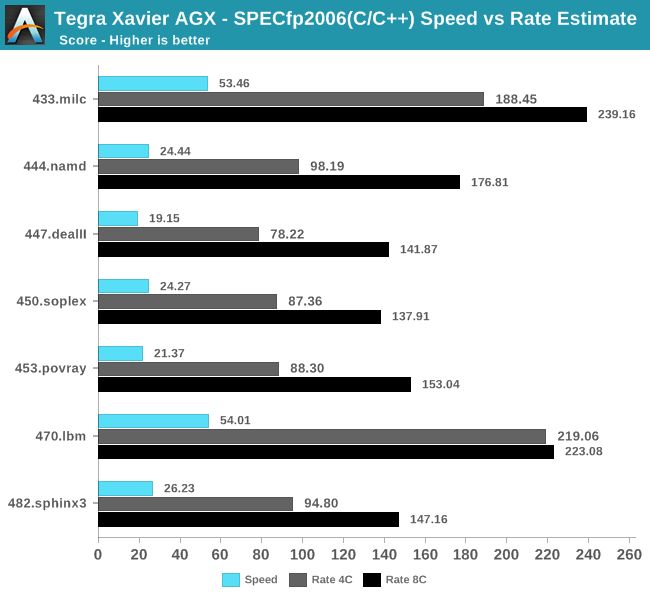
在浮点基准测试中,Xavier的整体表现更好,尤其是在433.milc和470.lbm等一些对内存子系统敏感的测试项中。而在其他的测试项中,Xavier与Cortex A75的性能依然非常相似。
以下是一些基于ARMv8指令集的架构在SPEC2006测试中的性能比较:
无法量化对比Carmel架构的一方面原因是它特殊的特性,这是一款带有ASIL-C功能安全功能的CPU,目前在这方面唯一可对比的竞争对手是Arm最新的自动驾驶芯片Cortex A76AE。虽然后者至少在未来一年或更长时间内都无法流片,但随着Arm投身到这一领域,Carmel架构和Xavier芯片的后辈们可能会面临激烈的竞争。
总体而言,Carmel架构对于NVIDIA及其内部微架构体系来说是一个巨大的进步,然而在与其他公司的最新架构进行比较时,Carmel架构在性能和能耗上都没能表现出一战定乾坤之能,略逊于前辈Denver的风采。鉴于Xavier使用的12nm FFN工艺与最新的7nm有着一两代的代差,Jetson AGX也不是为低功耗而生的平台,这也是意料之中的事情。
SPEC2006测试之多核效能
在以往的测试中,由于移动设备上温度墙和功耗墙的存在,很难在CPU测试探出这些芯片和架构真正的多核效能,而Jetson AGX平台则没有这些问题,无论供电还是散热都有充分保障,这使它成为测试Xavier芯片和Carmel架构多核效能的绝佳机会。
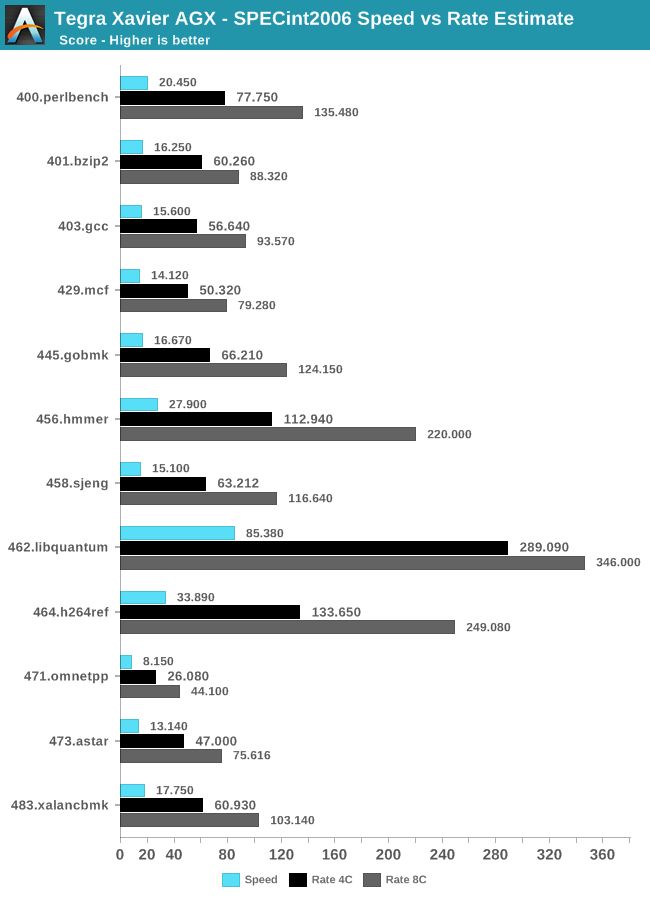
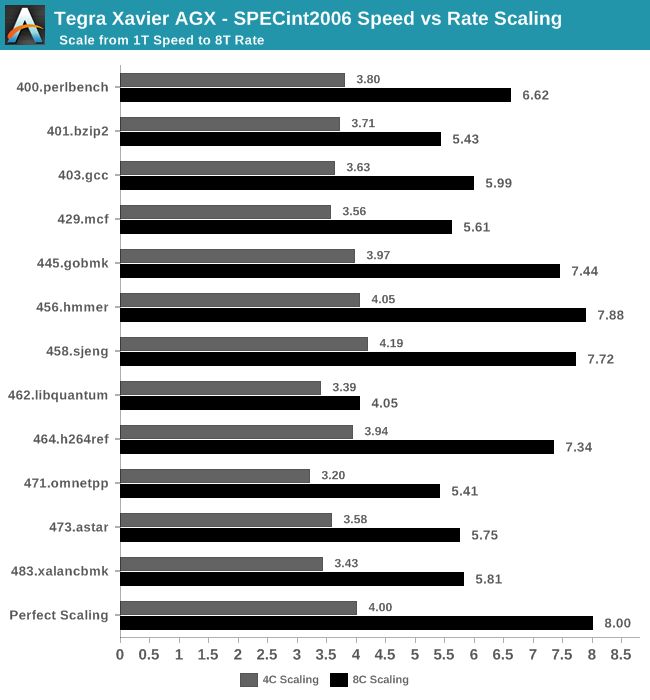
多核效能测试在4核和8核上执行,整数测试结果显示,4核运行时的性能与预期大致相仿,但在8核齐开的状态下,其性能要比预期稍低一些。为了更好地展示测试结果,我们将4核和8核的测试成绩换算成倍数,与单核性能进行比较:
可以看出,在大多数测试项中,4核的效能都在单核的3.6~4.2倍之间,只有少数低至3.2倍,而8核齐开时,却在近半测试项中却出现了效能只有5.X倍的情况。
由于Xavier的CPU部分由4个CPU集群组成,2个CPU核心之间共享2MB L2缓存,因此可能会出现集群中的核心之一资源受到约束的情况。在默认情况下,Xavier的核心调度方式是优先在每个集群中各填充一个核心,然后再调度余下的核心。
而这也就意味着在4核效能测试中,每个集群各调用了一个核心,每个核心都相当于独占了2MB L2缓存使用;而在8核效能测试中,L2缓存必须在两个核心之间共享,从而产生两个核心抢占缓存资源导致效能变差的情况。462.libquantum等工作负载在这种CPU设置下受到严重影响。
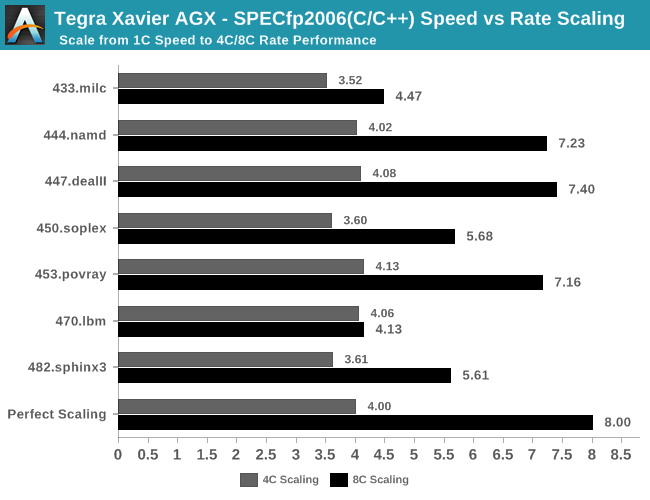
同样的分析也适用于浮点测试,一些对内存不太敏感的测试项在核心数量改变时没有那么多问题,但在433.milc和470.lbm等测试项中,8核全开时的效能同样不尽人意。
综合来看,NVIDIA对于Xavier的CPU集群设计是非常独特的,也许NVIDIA认为Jetson AGX所面对的大部分工况在核心扩展方面都不成问题,亦或是认为在机器人或自动驾驶场景下集群中的核心都在锁定状态下同步运行,理论上不会出现共享L2缓存时可能存在的资源争用问题吧。
NVIDIA的Jetson AGX平台为机器人何自动驾驶平台提供了充裕的灵活性和基础性能,其最大的卖点是Xavier强大的视觉计算和机器推理性能。
对于关注NVIDIA自研Carmel架构的人来说,实测结果显示其单核性能略高于Arm Cortex A75,多线程性能也很不错,尽管在某些场景下8核全开的效能会跌落一些,但在机器人和自动驾驶领域,这样的设计或许反而会化腐朽为神奇,一切还都未可知。
虽然在常规测试中没有拔得头筹,但考虑到其时间节点,Xavier依然是一颗强大且均衡的SoC。在眼下的AI芯片领域都在追求纯AI运算的精简设计时,NVIDIA是唯一没有放弃高性能CPU的一家,同时也是将CPU、GPU、AI三部分平衡做的最好的一家。
据雷锋网了解,目前还有很多视觉算法仍处于非常传统的阶段,无法通过GPU或Tensor Core加速,只能依靠强大的CPU来硬扛,在这些场景下,只有Xavier这样拥有高性能CPU的芯片才能购堪当大用。
虽然Jetson AGX开发套件价格高达2500美元,但对于那些需要大量视觉处理,或需要实现工业自动化的公司而言,Jetson AGX绝对是比其他平台更容易接受且更开放的选择。
雷锋网认为,Jetson AGX相比其他产品更有价值的一个方面是NVIDIA正在创建一个强大的软件生态系统和开发环境,使开发者能够更轻松地实现其产品。对NVIDIA来说,未来的挑战在于如何保持对Arm公版架构的领先,以及如何维持厂商的认可度。
via:Anandtech
- END -
◆ ◆ ◆
推荐阅读
关于「AI投研邦」
雷锋网旗下会员组织,聚焦AI+10大领域 :AI+汽车(智能驾驶)、AI+教育、AI+金融、AI+智慧城市、AI+安防、AI+医疗等。仅剩199个早鸟席位,欢迎加入。



