中国方言一览

1987年由中国社会科学院和澳大利亚人文科学院合作编制、由朗文出版(远东)有限公司出版的《中国语言地图集》是方言学和少数民族语言学研究的集大成者,在国内语言学研究的历史上也具有重要标志性意义。
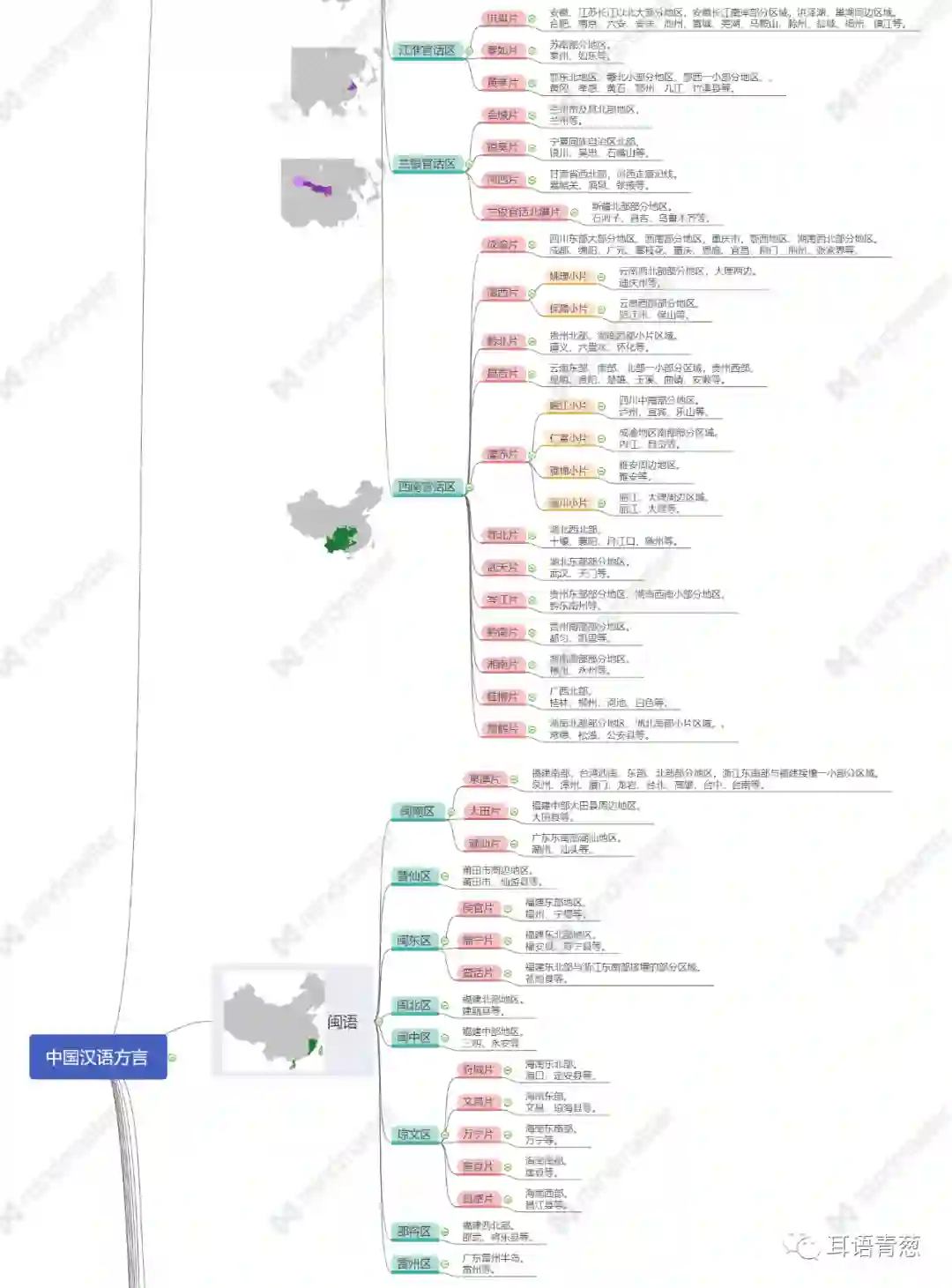
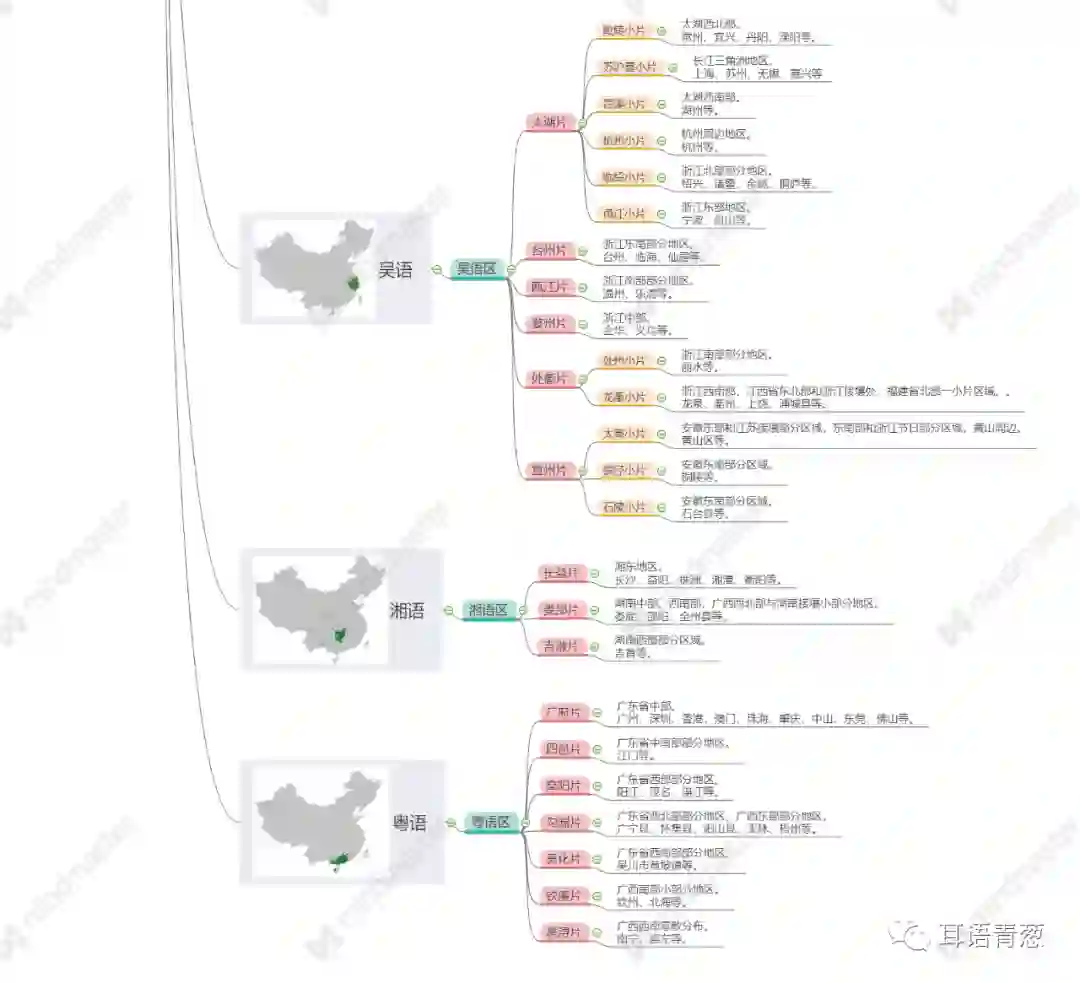
《地图集》将中国汉语方言分为了“语大区——语区——语片——语小片——方言点”五个层次,将汉语方言分为了官话、闽语、赣语、客家话、徽语、晋语、平话、吴语、湘语和粤语共十大类,其中官话下又分东北官话、北京官话、北方官话、中原官话、胶辽官话、兰银官话、江淮官话、西南官话等八个语区,闽语下也分为闽南话等八个语区。值得注意的是,晋语首次从官话中分出,独自成为一个语区;徽语也首次从吴语中分出,划为独立的语区。按照地域来看,官话和晋语属于北方方言,粤语、闽语、客家话和平话属于南方方言,剩下的赣语、湘语、徽语和吴语属于南北之间过渡的方言。
下表是根据《地图集》梳理出的中国汉语方言一览表。按照《地图集》对方言层级的划分方法,该表将方言划分精确到了方言小片一级,包括方言大区、方言区、语片和小片四级。在梳理的过程中,能明显感觉到相比起以官话为主的西北、西南、东北和北方地区,南方和东南地区方言组成极为复杂,一个省份同时包含多种方言语区,并出现多个方言交汇地带,甚至有些地区有同时几种方言交织在一起,同一地级市或自治州内,不同县所属的方言语区完全不同。


由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




