概率图模型笔记(PART I)

没有花里胡哨的标题,对于基础的算法知识要踏实掌握,分享一份概率图模型学习笔记,一起交流。
写在前面
其实接触概率图模型也有一段时间了,从开始入坑NLP起,也陆陆续续看了很多关于图模型这方面的论文、博客和教程等,但是总是不能形成一个完整的体系,所以这次就下决心花点时间好好去整理复习一下。网上的资料很多,但是那都是别人的,最重要的还是要学会整理融合成自己的知识。
今天这篇主要就介绍一下图模型的基础知识,后面陆续会整理HMM, CRF等比较常见常用的概率图模型。
概率论只不过是把常识归纳为计算问题。 (皮诶尔·西蒙·拉普拉斯)
什么是概率图
我们首先肯定都知道什么是图。图就是由结点和结点之间的链接组成的。那么概率图就是在图结构的基础上集成了“概率”的概念,也就是,概率图中的结点变成了随机变量,链接变成了这些随机变量之间的概率关系(依赖关系)。
在宗成庆老师的统计自然语言处理一书中,有关于图模型的整体框架,对后面理解各种类型的图模型有非常好的帮助: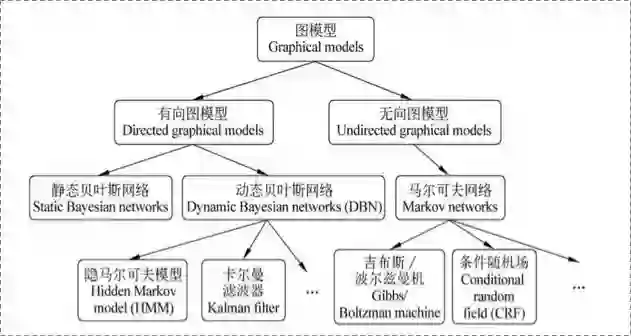
-
在有向图模型中,结点之间的链接有一个特定的方向,表达变量之间的因果关系; -
在无向图模型中,节点之间没有方向限制,用于表达随机变量之间的软限制
有向图 VS 无向图
有向图
有向图又可以称作贝叶斯网络、信念网络、有向无环图模型
有向图的一般模型如下所示: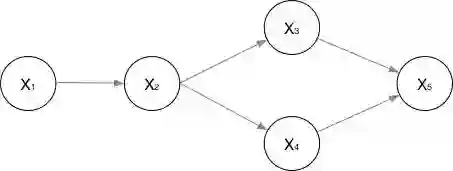
下面我们通过一个栗子更好地了解有向图。
有向图的条件独立判断与d-划分
首先我们来看三种简单的条件独立情况。
1、tail-to-tail
节点C链接的是两个箭头的尾部, 如下图
根据上图可以写出三个随机变量的联合分布:
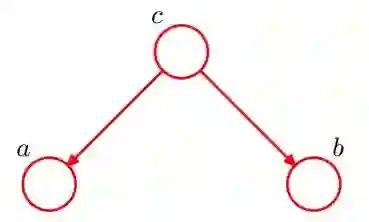
接着我们去判断a, b两个节点是否条件独立,有两种情况:
「(1)没有变量是观测变量」 此时我们可以对a,b,c的联合分布对c求积分,如果考虑c是离散的,可得:
可见a,b并不独立
「(2)变量C是观测变量」 此时我们有:
可知a,b是条件独立的
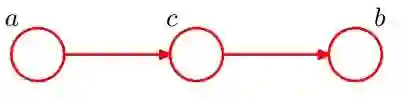
2、head-to-tail
同样我们分为两种情况讨论a,b的条件独立性(这里就不具体写出了)
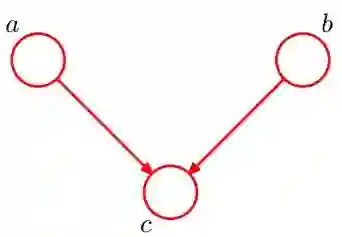
3、head-to-head
也是同样方法去分析。
一个总结(d-划分)
对于 DAG 图 E,如果A,B,C是三个集合(可以是单独的节点或者是节点的集合),为了判断 A 和 B 是否是 C 条件独立的, 我们考虑 E 中所有 A 和 B 之间的 「无向路径」 。对于其中的一条路径,如果满足以下两个条件中的任意一条,则称这条路径是「阻塞(block」)的:
(a)路径中存在某个节点X是 「head-to-tial」 或者 「tail-to-tail」 节点,并且 X 是包含在 C 中的;
(b)路径中存在某个节点X是「head-to-head」节点,并且 X 或 X 的儿子是不包含在 C 中的;
如果 A,B 间所有的路径都是阻塞的,那么 A,B 就是关于 C 条件独立的;否则, A,B 不是关于 C 条件独立的。
一个栗子
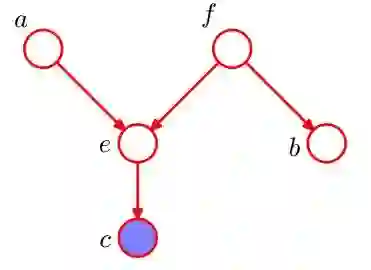
给定下面一个DAG,判断图中a和b是否在c条件下独立?a和b是否在f条件下独立?
「问题1」:a到b只有一条路径a->e->f->b,考虑路径上除了a和b之外的节点e和f:其中e是head-to-head类型的,且e的儿子节点就是c,根据上述可知e不阻断;对于f,是tail-to-tail类型的,且f不在c中,f也不阻断;因此a,b不是c条件下独立。
「问题2」:路径 a->e->f->b 上的所有节点。考虑路径上的点e和f:节点 e 是head-to-head 类型的,e 和她的儿子节点 c 都不在 f 中,e是阻断路径的节点。节点 f 是tail-to-tail类型节点,且 f 节点就在 f中,所以 f 节点阻断了路径。结论:a 和 b是 f 下条件独立的。
无向图
无向图又可以称作马尔科夫网络、马尔科夫随机场,如下图所示:
概率无向图的判断
这里首先给出判定条件:
如果联合概率分布满足成对、局部或者全局马尔科夫性,则称此联合概率分布为概率无向图模型。
接着我们来看什么是马尔科夫性
-
成对马尔可夫性:
-
局部马尔可夫性:
-
全局马尔科夫性:
条件独立判断
在有向图的情形下,我们可以通过d-划分来判断一个特定的条件独立性质是否成立。那么在无向图中,有没有类似的判定方法呢?
还是对于A,B,C,我们考虑链接集合A的结点和集合B的结点的所有可能的路径。如果所有这些路径都通过了集合C中的一个或多个节点,那么所有这样的路径都被“阻隔”,可以判断集合A与集合B在给定C的条件下独立。
还有另一种更明了的判定方式。我们把集合C中的所有结点以及与这些结点相连的链接全部删除,然后去考察A和B结点之间是否存在一条路径,如果没有这样的路径,则条件独立性质成立。
概率无向图模型的因子分解
概率无向图模型的最大特点就是易于因子分解,也就是将整体的联合概率写成若干子联合概率的乘积的形式。
首先我们需要了解什么是“团”与“最大团”
「团」:无向图中任何两个结点均有边链接的结点子集;
「最大团」:无向图中的某一个团C无法再加入另一个结点使其成为更大的团,则C为最大团
那么怎么做因子分解呢?
将概率无向图模型的联合概率概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为因子分解。
最后直接看公式
其中,Z(x)为归一化因子,目的就是为了让结果称为概率(对比softmax理解)
后面那个phi函数称为势函数,通常定义为指数函数:
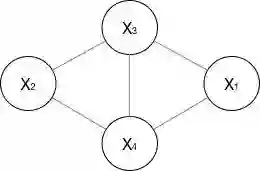
好的,举个栗子:比如我们需要将上面这个无向图进行因子分解
-
首先,找出最大团:(X1, X3, X4)和(X2, X3, X4) -
求因子分解:
判别式模型 VS 生成式模型
在有监督的模式识别或者机器学习问题中,我们可以把模型分为生成式和判别式两种。刚接触的时候也是对这俩模型傻傻分不清楚,无法触及到两者的本质区别,然后各种翻阅知乎博客,慢慢有了一些具体的认识。可以参考:
机器学习“判定模型”和“生成模型”有什么区别?[1]
判别式模型与生成式模型[2]
结合下面的图记录一下自己的理解。
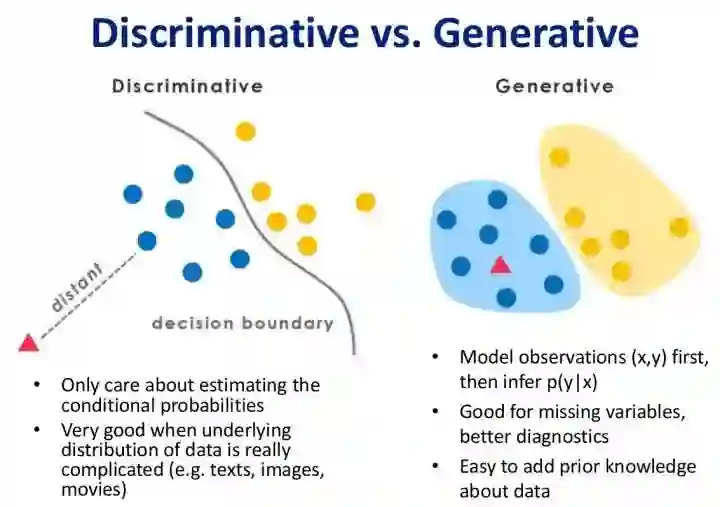
对于一个特定的机器学习问题(输入为X,输出或者说标签为Y),我们的建模思路大致有以下两种:
-
第一种,我们从输入X中通过特种工程提取出合适的特征,直接进行根据特征和标签Y进行学习,最终得到一个合适的模型(对应上图就是decision boundary); -
第二种,我们既然有了训练数据,为什么不先去了解一下数据是怎么分布的呢?如果我们可以通过某种方式得到X和Y的联合分布,那么对于新来的测试数据,我们就可以利用这个联合分布来求出所对应的新标签Y(具体例子参考朴素贝叶斯模型可以很清楚):
好了,上面说的第一种建模思路对应的就是判别式模型,第二种思路对应的就是生成式模型,总结一下:
-
判别式模型主要有:Logistic Regression、SVM、Traditional Neural Network、Nearest Neighbor、CRF、Linear Discriminant Analysis、Boosting、Linear Regression; -
生成式模型主要有:Gaussians, Naive Bayes, Mixtures of Multinomials、Mixtures of Gaussians, Mixtures of Experts, HMMs、Sigmoidal Belief Networks, Bayesian Networks、Markov Random Fields、Latent Dirichlet Allocation -
由生成式模型可以得到判别式模型,但由判别式模型得不到生成式模型
本文参考资料
机器学习“判定模型”和“生成模型”有什么区别?: https://zhuanlan.zhihu.com/p/30941701
[2]判别式模型与生成式模型: http://www.leexiang.com/discriminative-model-and-generative-model
- END -

推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。