【Coling-2020】面向机器阅读理解的双向认知思维网络
《Bi-directional Cognitive Thinking Network for Machine Reading Comprehension》
面向机器阅读理解的双向认知思维网络

论文地址:https://www.aclweb.org/anthology/2020.coling-main.235.pdf
代码地址:https://github.com/a414351664/BCTN-in-COLING-2020
摘要
本文从互补学习系统理论的角度提出了一种新的阅读理解双向认知知识框架(BCKF)。它旨在模拟大脑中两种回答问题的思维方式,包括逆向思维和惯性思维。为了验证该框架的有效性,我们设计了一个相应的双向认知思维网络(BCTN),对文章进行编码,生成一个给定答案(问题)的问题(答案),并对双向知识进行解耦。该模型具有逆向推理的能力,有助于惯性思维产生更准确的答案。在DuReader数据集中观察到有效地改善,证实了我们的假设,即双向知识有助于QA任务。同时,这个新颖的框架也展示了机器阅读理解和认知科学的一个有趣的视角。
1.介绍
机器阅读理解(MRC)已经取得了长足的进步,一系列的神经模型在一些基准上,如SQuAD,迅速接近人类的对等水平。然而,现有的方法在认知科学的水平上还处于初级阶段。近年来,脑科学和心理学为类脑计算的发展和模拟人类的感知、思考、理解和推理能力提供了重要的基础。
思维是人脑对客观事物的性质、相互关系和内在规律的概括和间接反映。在心理学中,有两种思维是互补的:一种是从前向刺激到后向刺激的惯性思维,另一种是从后向刺激到前向刺激的逆向思维。比如数学中常用的反证法,就是对结论取反,一直推导到矛盾结束。具体地说,在MRC任务中,这两种思维可以看作是从问题(答案)到答案(问题)的推理过程。例如,如图1所示,我们可以通过定位实体{怀孕的孕妇}和{枇杷}很容易得到答案。相反地,生成问题可以通过阅读答案和文章来推理,这个答案描述了两个方面的问题,包括{孕妇能吃枇杷}和{孕妇吃枇杷有什么好处}。我们希望这种逆向推理问题的能力能够提高阅读理解任务的表现。

以往的方法只考虑一个正向的逻辑关系,即基于给定的问题和文章。他们忽略了给定段落和答案之间的反向关系。尽管有相关工作提出了一个既问又答的联合模型,但它将正向和逆向的知识耦合起来,而不是以一种解耦合的方式进行处理。类似的,我们假设逆向推理问题的能力可以帮助模型获得更好的性能。这部分源于心理学的观察,即在阅读时设计问题可以帮助学生提高阅读和理解的文本处理能力。
因此,可以从人类的认知过程中获得对问题解决方案的见解。互补学习系统理论(CLST)认为,人脑包含互补的学习系统,在我们试图理解一个经历过的情况时,支持同时使用许多信息源。其中一个系统是通过累积学习逐步获得一个完整的知识体系,包括我们对词义、常见事物性质和熟悉情景特征的知识。就像惯性思维一样,长时间学习现实世界中不同事物之间的关系。另一个系统是一个类似于逆向思维的快速学习系统,它的目标是从另一个不寻常的角度来刺激和增强大脑中不经常使用的回路区域。
2.双向认知知识框架
在互补学习系统理论(CLST)的启发下,我们提出了双向认知知识框架(BCKF)。如图2(a)所示,蓝色和方块包含围绕一组输入组织的新皮层系统。红盒是内侧颞叶(MTL)系统,其中蓝色椭圆形(融合系统、惯性思考器、逆向思考器、推理机和门控制器)代表与橙色椭圆有着直接或间接相关的关系,这些橙色的椭圆定义为包含少量信息(如视觉和语言输入)的输入池。绿色箭头表示不同蓝色椭圆之间的学习连接,它们将嵌入的元素绑定在一起,以便以后重新激活。绿色虚线表示双向思考者包含推理模块。蓝色箭头表示不同系统之间的信息传输。红色和蓝色的圆形箭头表示自我学习和自我更新。控制者决定记忆中逆向思维的刺激强度,以便在不同的情况下做出不同的决定。最后,理解系统通过惯性思维和逆向思维相结合来指导模型的行为和对语言的理解。
3.方法
本文提出了双向认知知识框架(BCKF)。并设计相应的双向认知思维网络(BCTN)来验证逆向思维的有效性,如图2所示。
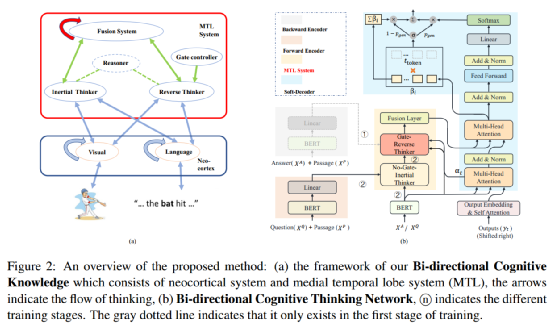
该方法概述:(a)我们的双向认知知识框架由大脑皮层系统和内侧颞叶系统(MTL)组成,箭头表示思维的流动,(b)双向认知思维网络,n表示不同的训练阶段。灰色虚线表示它只存在于训练的第一阶段。
根据图2的概述,我们提出的基于双向认知知识框架的模型由以下模块组成,模型的训练包括两个阶段。
在{第一阶段}(反向编码器->基于门控的反向思考器->融合层->软解码器)中,反向编码器模拟答案和文章之间的交互关系,生成问题,称为反向思维训练。
前向编码器类似于具有不同参数和输入的反向编码器,在{第二阶段}(正向编码器->无门的惯性思考器->基于门控的反向思考器->融合层->软解码器)期间,使用给定的段落和问题进行再训练,生成最终的答案,称为惯性思维再训练。
内侧颞叶(MTL)系统包括基于门控的反向思考器、无门的惯性思考器和融合层。基于门控的反向思考器从逆向的一面学习神经元的反向连接,并决定记忆中反向思维的刺激强度。无门的惯性思考器建立文章和问题的正向关系。融合层结合双向知识为解码做准备。
软解码器输出一个指针生成器加复制机制的答案(问题),以综合词汇分布和源输入的tokens分布。
3.1 逆向思维训练
在这一节中,我们用答案和文章训练基于门控的反向思考器,其中保留的参数被视为大脑中反向回路的连接。所述图2(a)中的控制器,其确定存储器中反向思维的刺激强度,以在不同的情况下做出不同的决定。最后,解码器根据答案推断出问题。
反向编码器
我们使用BERT的编码器,添加了特殊分类嵌入([CLS]),它对两个句子之间的蕴涵信息进行编码,并用一个特殊的符号([SEP])将答案A和段落P分开。输入的总长度是L=(K+N+3),其中K和N分别是答案和文章的长度。为了review答案(问题),找到答案(问题)相关的语义信息,我们再用一个BERT对答案(问题)进行编码,得到一个带有K+2个tokens的纯答案向量V。
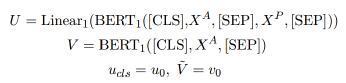
基于门控的反向思考器
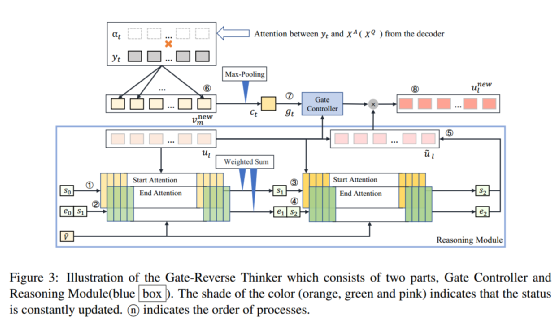
示意图说明,它由两部分组成:门控制器和推理模块(蓝框)。颜色的阴影(橙色、绿色和粉色)表示状态不断更新。n表示进程的顺序。
如图3所示,推理模块(蓝框)包含由开始(橙色)和结束(绿色)子块组成的推理块。这两个子块具有时序依赖性,即在计算结束子块时需要考虑起始子块的结果。推理模块模拟人类的思维过程,通过多个推理步骤不断挖掘U和V之间的关系。在第j步推理过程中,sj和ej是推理的起始和结束向量,可以看作是隐藏状态来增强U的表示。
最终的推理向量s2和e2基于与答案(或问题)的相关性融合所有可能的推理片段。此外,思考器基于已经解码的词来计算门控向量g,以确定记忆中逆向思维的刺激强度。因此我们可以得到最终的隐层状态的表示:
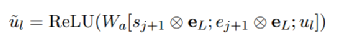
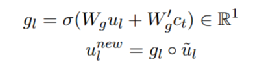
ul 表示的BERT的第l个token编码,gl 表示第l个token的打分,最终的unew即编码器的输出表示。
融合层
为了将逆向思维和惯性思维相结合,我们采用了Wang等人(2018a)中使用的融合核来更好地理解语义:
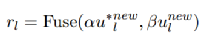
软解码器
我们在单词嵌入层和self-attention提供的嵌入之上使用了一组Transformer解码器块。此外,还使用了指针softmax机制,该机制学习在从文档复制单词和从指定词汇表生成单词之间进行转换。
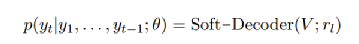
3.2 惯性思维再训练
接下来我们会重复第二阶段的训练,同样的以BERT作为正向编码器,经过无门的惯性思考器得到正向的知识,同时基于门控的反向思考器基于第一阶段训练得到的参数,模拟逆向的知识,在这个过程中,我们把双向的知识进行了解耦合,得:
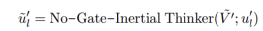
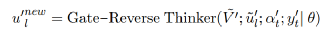
最终进行双向知识得融合和解码,两个超参数表示的是人工设计的,来决定双向思维的比例:
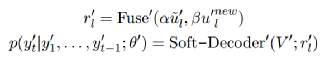
4.实验设置
4.1 数据集
为了证明我们工作的有效性,我们选择了DuReader基准数据集,它是从真实世界的搜索引擎(BaiDu)设计的。在数据量方面,它包含了300k个问题,并且数据被分成了一个训练集(290k对)和一个开发集(10k对)。测试分割对公众是隐藏的,因此,我们从开发数据中随机抽取5k个问题-答案对作为验证集,并使用其余的开发数据来报告测试结果。至于评价指标,答案是人为生成的,因此DuReader中的评测指标我们考虑的是{ROUGE-L}(R-L)和{BLEU-4}(B-4)。
4.2 实验结果
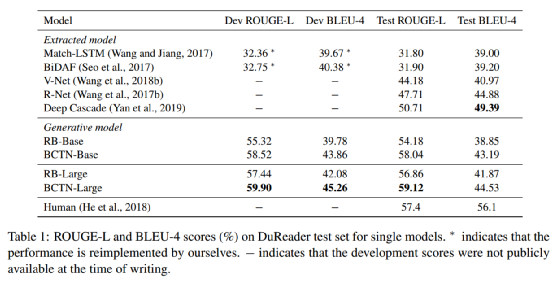
在DuReader数据集中,基线可分为三类:最新模型、RoBERTa-base(RB-base)模型和RoBERTa-large(RB-large)模型。RB-base和RB-large表明我们直接使用预先训练好的语言模型作为编码器,而不需要MTL系统。为了降低模型的复杂度,以往的方法将其转化为抽取任务。因此,我们将模型分为抽取模型和生成模型。如表1所示,我们在DuReader上的单个模型的主要结果优于BERT-Style的基线。在RoBERTa基础模型上ROUGE-L和BLEU4分别增加了3.86%和4.34%,在RoBERTa大型模型上,ROUGE-L和BLEU-4分别增加了2.26%和2.66%。虽然我们的模型在BLEU-4上比提取模型略有下降,但它在ROUGE-L上的表现要优于它们约8.4%。这是因为抽取式模型相比而言,通常具有更好的性能。这一现象在生成摘要任务中也可以体现。
4.3 消融实验和不同参数的影响
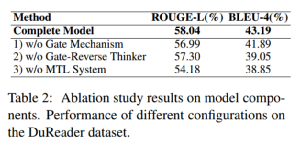
我们对我们的模型进行了消融研究,以讨论在我们的框架中可以移除的增强组件的影响。表2显示了我们提出的BCTN中不同部分的有效性。注意,通过删除所有不同的元素,配置3减少到RB基本模型。
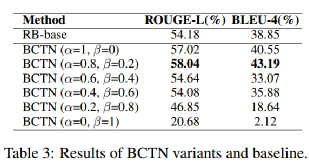
此外,我们手动设置不同的参数alpha和beta来探索双向知识如何影响BCTN的性能。从表3可以看出,仅使用惯性思维时,模型在ROUGE-L上的性能达到57.02%,而加入反向思维后,模型达到了一个峰值。在模型只使用逆向思维而忽略惯性思维的情况下,模型的有效性显著下降。这与心理学中的人类行为相一致,即逆向思维可以帮助惯性思维产生更准确的答案,仅仅使用逆向思维或惯性思维是不够的。
4.4 Case study
定性地说,我们在加入双向思考者之前和之后观察到了一些有趣的例子。如表4所示,在案例1中,提出的模型输出了一个生成性问题{如何通过“噩梦结束”}的大师级别,该问题的语义与gold question相同。我们提出的BCTN得到了正确的答案,并给出了更详细的解释。然而,RB基线输出了一个错误的答案,尤其是句子{他们必须到达血}。在案例二中,也可以得出同样的结论。RB基线的答案描述的是枇杷的营养成分,而不是真正的问题对应的答案。但BCTN不仅给出了正确的反应,而且解释了孕妇为什么能吃枇杷。在我们的模型的帮助下,答案变得更加可解释和正确,说明我们的想法确实可以帮助系统回答更准确的问题。

5.结论
本文从心理学角度提出了与双向认知知识框架(BCKF)相对应的双向认知思维网络(BCTN)。BCTN通过模拟惯性思维和逆向思维,以双向知识回答问题。我们将这两个部分的知识解耦,进行最终的答案生成。为了确定记忆中反向思维的刺激强度,我们考虑解码后的tokens来计算基于门机制的分数。我们证明了所提出的BCTN方法是有效的,它与文献中关于DuReader的单模型方法相比具有竞争力。我们未来的工作将考虑使用不同的数据集和设计各种模型来模拟我们大脑的行为,以尝试获取人类水平的语言理解和智能。这篇论文的工作是我们在认知科学中的浅层理解,我们希望有更多的研究者能够共同交流和学习。最后,我们相信我们的框架可以推广到其他的生成任务,例如摘要生成和image caption等任务。
团队介绍
中国科学院信息工程研究所雏鹰团队,在ACL、AAAI、IJCAI、TIP、ACM Multimedia、EMNLP、COLING等国际/国内会议及期刊上均有论文发表,同时也在2019年世界视觉对话比赛,WMT 2020国际机器翻译大会,SemEval2020国际语义评测大会,CCMT 2019全国机器翻译大会取得TOP-3的成绩。目前由胡玥老师和于静老师带领,学生总共13名,博士生10名,硕士生3名。主要的研究方向分为两大类,一类是自然语言处理,一类是跨媒体智能分析。在自然处理领域中,主要研究机器翻译,机器阅读理解,对话系统。在跨媒体智能分析领域,主要研究视觉问答,视觉对话,跨媒体检索以及图像视频描述生成。欢迎对上述方向感兴趣的研究学者和同学们加入到我们团队共同学习!共同交流!
联系邮箱:胡玥huyue@iie.ac.cn、于静yujing@iie.ac.cn
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“BCTN” 可以获取《【Coling-2020】面向机器阅读理解的双向认知思维网络》专知下载链接索引





