.NET Core 数据抓取DotnetSpider实战
(点击上方蓝字,可快速关注我们)
来源:FunnyBoy
cnblogs.com/FunnyBoy/p/8453338.html
一、背景
一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得庆幸的,该库也支持.NET Core,于是趁着春节的空档研究一下整个开源项目,顺便实战一下。
目前互联网汽车行业十分火热,淘车,人人车,易车,汽车之家,所以我选取了汽车之家,芒果汽车这个店铺,对数据进行抓取。
二、开发环境
VS2017+.Net Core2.x+DotNetSpider+Win10
三、开发
3.1、新建.NET Core项目
新建一个.NET Core 控制台应用
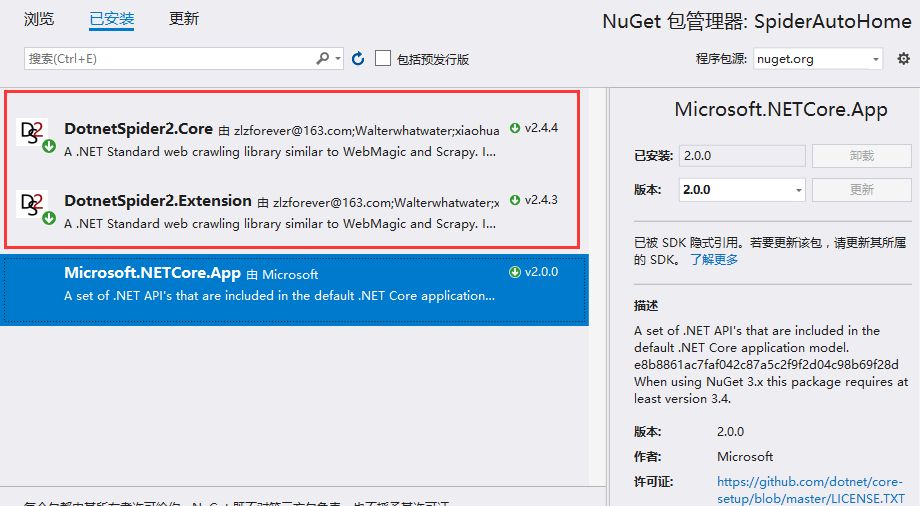
3.2、通过Nuget添加DotNetSpider类库
搜索DotnetSpider,添加这两个库就行了
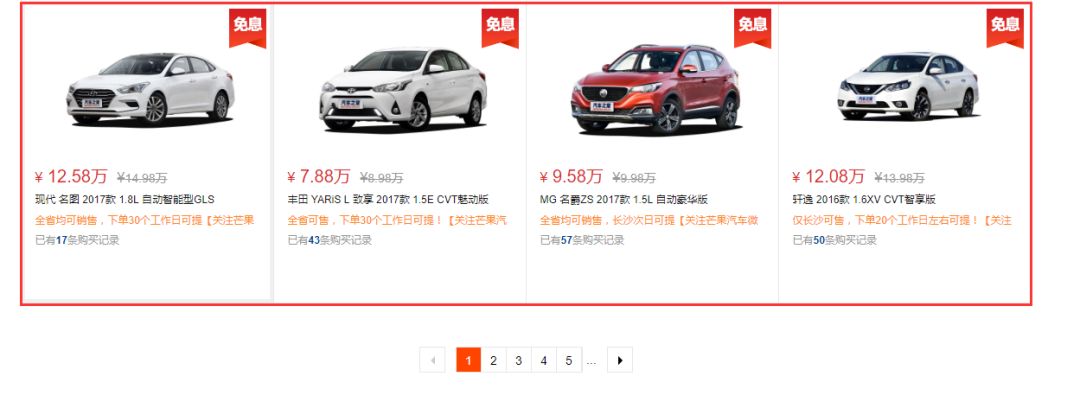
3.3、分析需要抓取的网页地址
打开该网页https://store.mall.autohome.com.cn/83106681.html,红框区域就是我们要抓取的信息。
我们通过Chrome的开发工具的Network抓取到这些信息的接口,在里面可以很清楚的知道HTTP请求中所有的数据,包括Header,Post参数等等,其实我们把就是模拟一个HTTP请求,加上对HTML的一个解析就可以将数据解析出来。
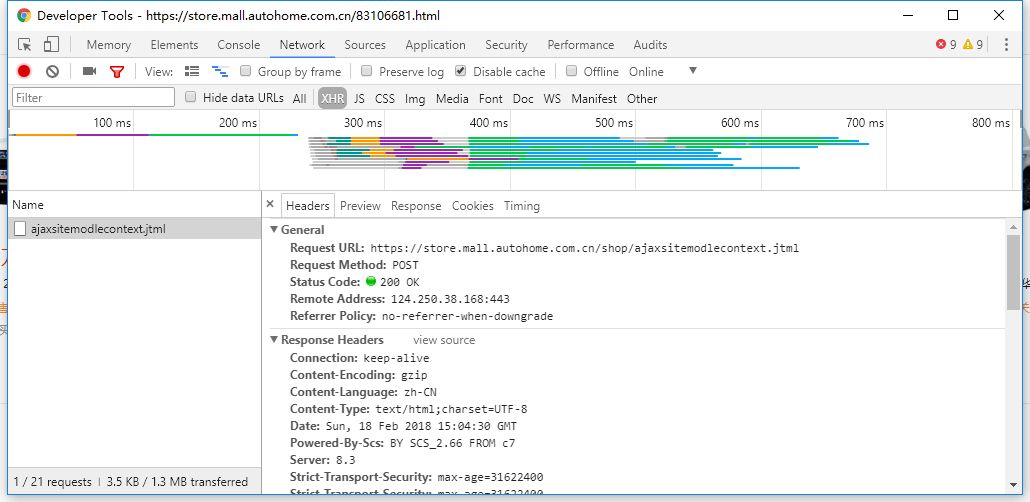
参数page就是页码,我们只需要修改page的值就可以获取指定页码的数据了。
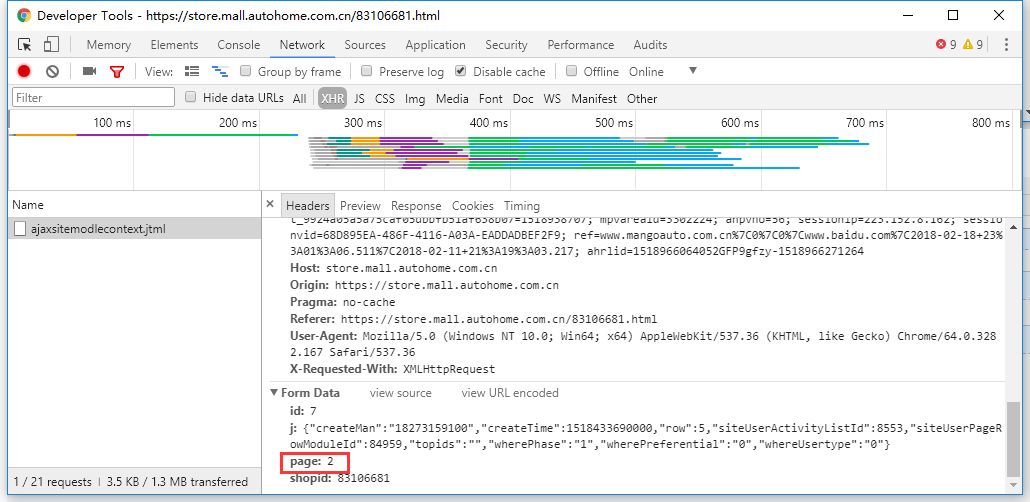
返回结果就是列表页的HTML。
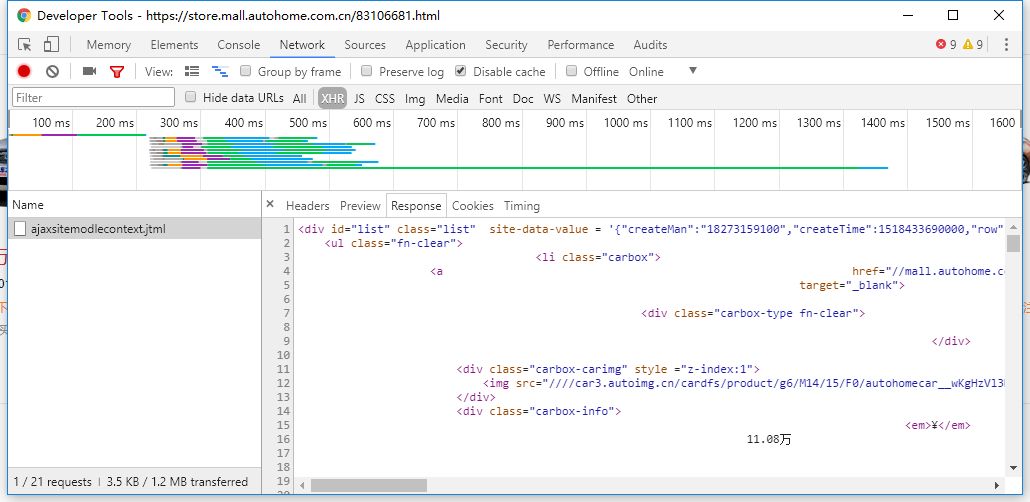
3.4、创建存储实体类AutoHomeShopListEntity
class AutoHomeShopListEntity : SpiderEntity
{
public string DetailUrl { get; set; }
public string CarImg { get; set; }
public string Price { get; set; }
public string DelPrice { get; set; }
public string Title { get; set; }
public string Tip { get; set; }
public string BuyNum { get; set; }
public override string ToString()
{
return $"{Title}|{Price}|{DelPrice}|{BuyNum}";
}
}
3.5、创建AutoHomeProcessor
用于对于获取到的HTML进行解析并且保存
private class AutoHomeProcessor : BasePageProcessor
{
protected override void Handle(Page page)
{
List<AutoHomeShopListEntity> list = new List<AutoHomeShopListEntity>();
var modelHtmlList = page.Selectable.XPath(".//div[@class='list']/ul[@class='fn-clear']/li[@class='carbox']").Nodes();
foreach (var modelHtml in modelHtmlList)
{
AutoHomeShopListEntity entity = new AutoHomeShopListEntity();
entity.DetailUrl = modelHtml.XPath(".//a/@href").GetValue();
entity.CarImg = modelHtml.XPath(".//a/div[@class='carbox-carimg']/img/@src").GetValue();
var price = modelHtml.XPath(".//a/div[@class='carbox-info']").GetValue(DotnetSpider.Core.Selector.ValueOption.InnerText).Trim().Replace(" ", string.Empty).Replace("\n", string.Empty).Replace("\t", string.Empty).TrimStart('¥').Split("¥");
if (price.Length > 1)
{
entity.Price = price[0];
entity.DelPrice = price[1];
}
else
{
entity.Price = price[0];
entity.DelPrice = price[0];
}
entity.Title = modelHtml.XPath(".//a/div[@class='carbox-title']").GetValue();
entity.Tip = modelHtml.XPath(".//a/div[@class='carbox-tip']").GetValue();
entity.BuyNum = modelHtml.XPath(".//a/div[@class='carbox-number']/span").GetValue();
list.Add(entity);
}
page.AddResultItem("CarList", list);
}
}
3.6、创建AutoHomePipe
用于输出抓取到的结果。
private class AutoHomePipe : BasePipeline
{
public override void Process(IEnumerable<ResultItems> resultItems, ISpider spider)
{
foreach (var resultItem in resultItems)
{
Console.WriteLine((resultItem.Results["CarList"] as List<AutoHomeShopListEntity>).Count);
foreach (var item in (resultItem.Results["CarList"] as List<AutoHomeShopListEntity>))
{
Console.WriteLine(item);
}
}
}
}
3.7创建Site
主要就是将HTTP的Header部信息放进去
var site = new Site
{
CycleRetryTimes = 1,
SleepTime = 200,
Headers = new Dictionary<string, string>()
{
{ "Accept","text/html, */*; q=0.01" },
{ "Referer", "https://store.mall.autohome.com.cn/83106681.html"},
{ "Cache-Control","no-cache" },
{ "Connection","keep-alive" },
{ "Content-Type","application/x-www-form-urlencoded; charset=UTF-8" },
{ "User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}
}
};
3.8、构造Request
因为我们所抓取到的接口必须用POST,如果是GET请求则这一部可以省略,参数就放在PostBody就行。
List<Request> resList = new List<Request>();
for (int i = 1; i <= 33; i++)
{
Request res = new Request();
res.PostBody = $"id=7&j=%7B%22createMan%22%3A%2218273159100%22%2C%22createTime%22%3A1518433690000%2C%22row%22%3A5%2C%22siteUserActivityListId%22%3A8553%2C%22siteUserPageRowModuleId%22%3A84959%2C%22topids%22%3A%22%22%2C%22wherePhase%22%3A%221%22%2C%22wherePreferential%22%3A%220%22%2C%22whereUsertype%22%3A%220%22%7D&page={i}&shopid=83106681";
res.Url = "https://store.mall.autohome.com.cn/shop/ajaxsitemodlecontext.jtml";
res.Method = System.Net.Http.HttpMethod.Post;
resList.Add(res);
}
3.9、构造爬虫并且执行
var spider = Spider.Create(site, new QueueDuplicateRemovedScheduler(), new AutoHomeProcessor())
.AddStartRequests(resList.ToArray())
.AddPipeline(new AutoHomePipe());
spider.ThreadNum = 1;
spider.Run();
3.10、执行结果
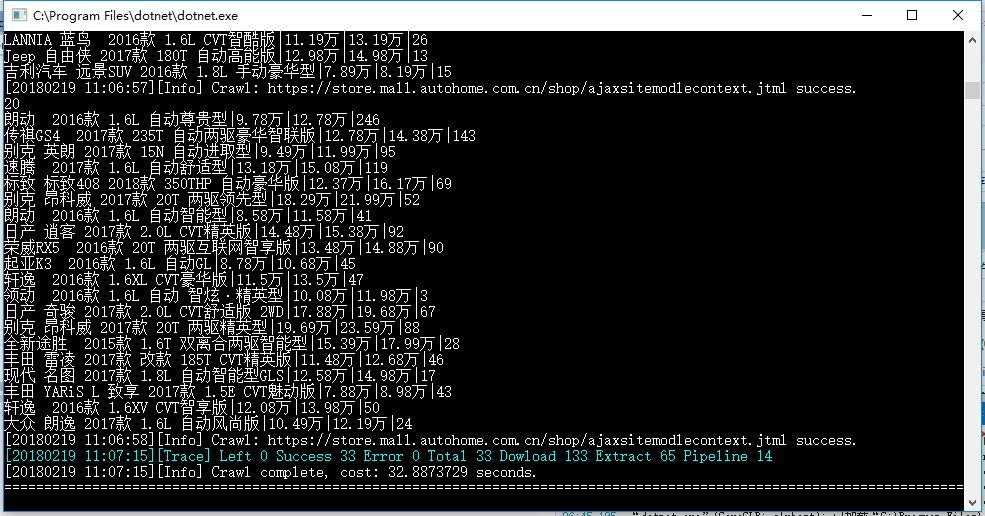
四、下次预告
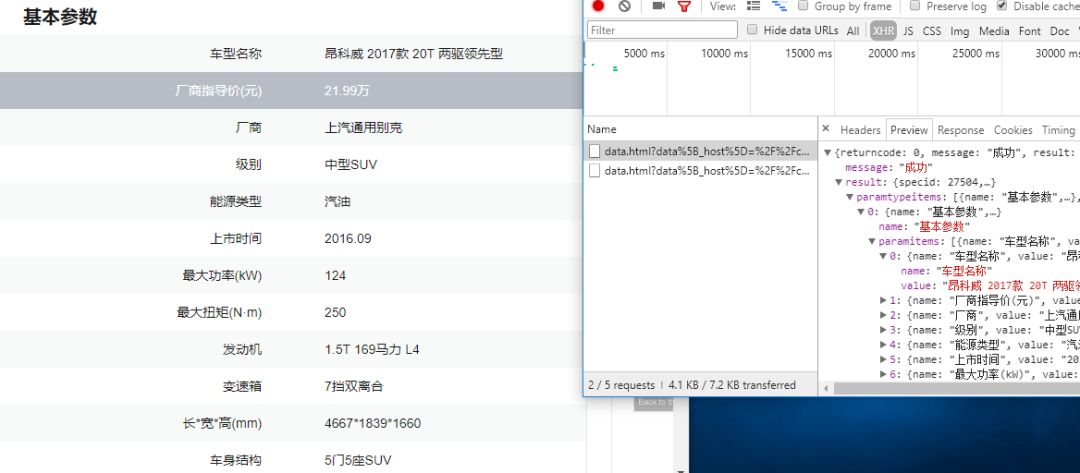
接下来我会将对商品的详情页数据(包括车型参数配置之类的)进行抓取,接口已经抓取到了,还在思考如果更加便捷获取到商品id,因为目前来看商品id是存储在页面的js全局变量中,抓取起来比较费劲。
五、总结
.NET 相对于别的语言感觉并不是那么活跃,DotnetSpider虽然时间不长,但是希望园子里面大伙都用起来,让他不断的发展,让我们的.Net能够更好的发展。
看完本文有收获?请转发分享给更多人
关注「DotNet」,提升.Net技能


淘口令:复制以下红色内容,再打开手淘即可购买
范品社,使用¥极客T恤¥抢先预览(长按复制整段文案,打开手机淘宝即可进入活动内容)




