近日,RecSys 2020官网公布了本届最佳长短文论文奖。
来自
腾讯PCG团队
的四
位作者Hongyan Tang、Junning Liu、Ming Zhao、Xudong Gong凭借研究出一种
新的多任务学习个性化推荐模型获得了最佳长论
文奖,获奖论文:
《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》
ACM RecSys(推荐系统会议)是用于介绍推荐系统广泛领域中的最新研究成果、系统和技术的国际会议。推荐是信息过滤的一种特殊形式,它利用过去的行为和用户相似性来生成信息项(items )列表,这些信息项是针对最终用户的喜好量身定制的。
RecSys与从事推荐系统的主要国际研究小组以及许多世界领先的电子商务公司汇聚在一起,因此,它已成为介绍和讨论推荐系统研究的最重要的年度会议。
官网地址:https://recsys.acm.org/best-papers/
RecSys 2020这次也公布了
五位最佳审稿人
(Best Reviewer):
Bart Goethals、Peter Knees、Scott Sanner、Steffen Rendle、Toine Bogers。
最佳长论文
获奖论文:《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》
论文链接:https://dl.acm.org/doi/10.1145/3383313.3412236
多任务学习(Multi-task learning,MTL)已成功应用于许多推荐应用中。然而,由于现实世界推荐系统中任务相关性的复杂性和竞争性,MTL模型往往会出现负迁移的性能退化。
此外,通过对SOTA MTL模型的大量实验,我们观察到了一个有趣的现象,即一个任务的性能通常会通过影响其他任务的性能而得到改善。为了解决这些问题,
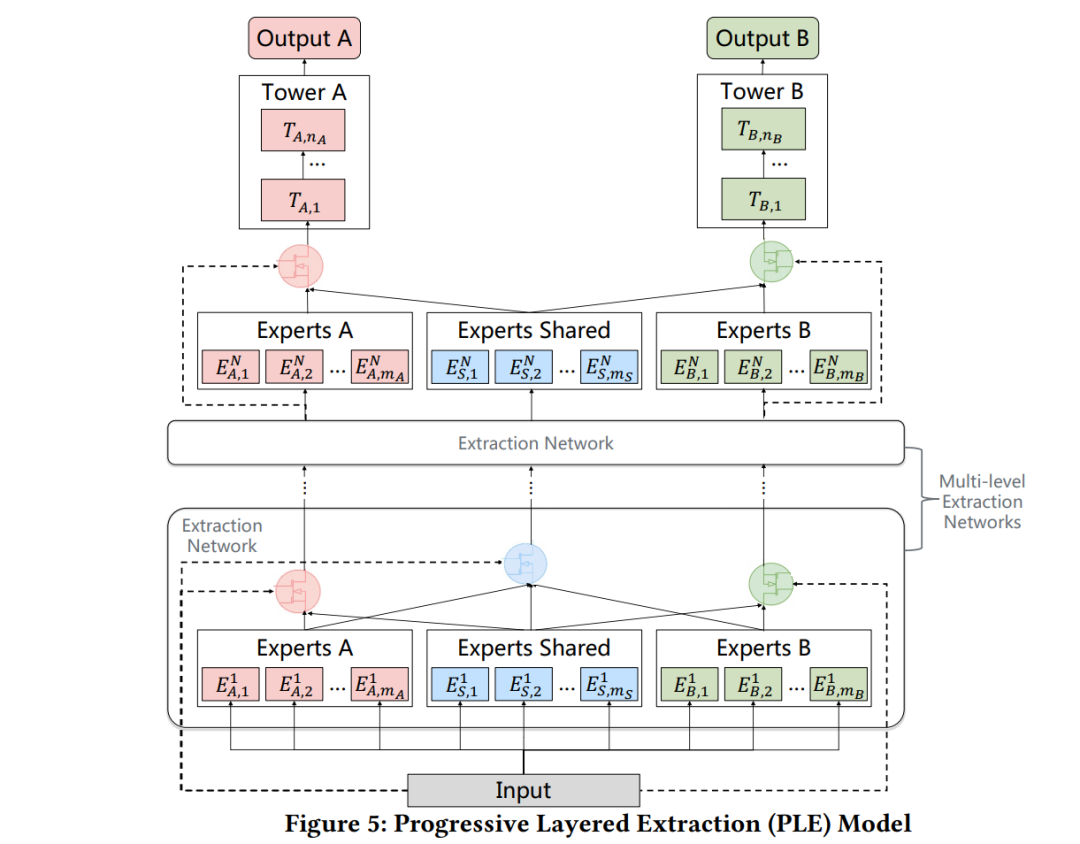
我们提出了一个具有新颖共享结构设计的渐进式分层抽取(PLE)模型:
PLE将共享组件和任务特定组显示分离,采用渐进式路由机制逐步提取和分离深层语义知识,提高了通用环境下跨任务联合表示学习和信息路由的效率。
在一个具有10亿样本的腾讯视频推荐数据集上,我们将PLE应用于复杂相关和正常相关的任务,从两个任务案例到多个任务案例的结果都表明,在不同的任务相关性和任务组规模下,PLE的性能显著优于最新的MTL模型。
此外,在腾讯大型内容推荐平台上对PLE的在线评价显示,与目前的SOTA MTL模型相比,浏览量增加了2.23%,观看时间增加了1.84%,这是模型的一个显著提升,证明了PLE的高效性。最后,在公开基准数据集上进行的大量离线实验表明,除了建议消除跷跷板现象外(seesaw phenomenon),PLE还可以应用于各种场景。
最佳短论文
论文题目:
《ADER: Adaptively Distilled Exemplar Replay Towards Continual Learning for Session-based Recommendation 》
论文链接:https://dl.acm.org/doi/10.1145/3383313.3412218
近年来,随着人们对隐私问题的关注,基于会话的推荐也越来越受到人们的关注。尽管最近基于神经会话的推荐系统取得了成功,但它们通常是使用静态数据集以离线方式开发的。然而,推荐建议需要不断的调整,以照顾到新的和过时的项目和用户,并需要在实际应用中“不断学习”。在这种情况下,推荐系统会使用每个更新周期中到达的新数据进行持续和周期性更新,更新后的模型需要在下一次模型更新之前为用户活动提供推荐。
使用神经模型进行持续学习的一个主要挑战是灾难性遗忘,在这种情况下,一个持续训练的模型会忘记它以前学习过的用户偏好模式。为了应对这一挑战,
我们提出了一种自适应蒸馏样本重放(ADER)方法,通过周期性地将先前的训练样本重放到当前同时具有自适应蒸馏损失的模型中。
实验是基于SOTA模型SASRec进行的,使用两个已被广泛使用的数据集,用几种著名的持续学习技术对ADER进行基准测试。经验证明,在每次更新周期中,ADER的性能始终优于其他baseline模型,甚至优于使用所有历史数据的方法。这一结果表明,ADER是一个有希望的解决方案,以减轻灾难性遗忘问题、建立更现实和可扩展的基于会话的推荐系统。
最佳长论文Runner-up(亚军)
获奖论文:
《Exploiting Performance Estimates for Augmenting Recommendation
Ensembles》
论文链接:https://dl.acm.org/doi/10.1145/3383313.3412264
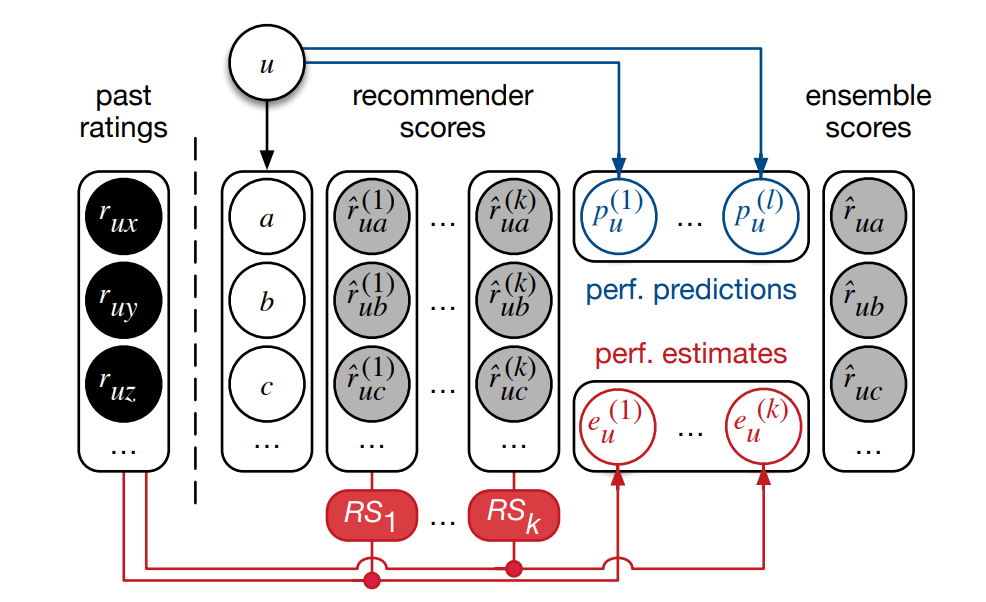
通过叠加将多个推荐系统集成在一起,可以有效地提高协同推荐的效率。最近的工作扩展了stacking ,使用额外的用户性能预测器,例如用户所做的评分总数来帮助确定每个基础推荐应该为集成系统贡献多少。
尽管如此,然而,尽管手工判别预测器的成本很高,且通常需要深入了解集成中每个推荐的优缺点,但只观察到一些微小的改进。为了克服这一局限性,
我们建议通过利用用户自己的历史评分来直接评估这些性能,而不是设计复杂的特征来预测给定用户的不同推荐的性能。
对来自多个领域的真实数据集进行的实验表明,使用性能估计作为附加特征可以显著提高SOTA集成器的精度,与不使用它们相比,实现nDCG@20平均提高了23%。
最佳长论文提名
![]()
在公布本次最佳长论文之前,RecSys 2020在开幕式上先提前公布了四篇最佳长论文提名,如上图所示。
如上所介绍,第二篇论文获得了最佳长论文奖,第四篇论文则是获得了最佳长论文奖亚军。
《SSE-PT:Sequential recommendation via ressonalized transformer》
![]()
论文链接:https://dl.acm.org/doi/pdf/10.1145/3383313.3412258
代码和数据链接:https://github.com/fulliwei9278/SSE-PT
论文作者:吴立伟,博士就读于UC Davis(加利福尼亚大学戴维斯分校)......
时间信息对于推荐问题至关重要,因为用户偏好在现实世界中是动态的。
深度学习的最新进展,特别是在自然语言处理中广泛使用的RNN和CNN之外,发现了各种注意机制和更新的体系结构,使得每个用户都能更好地使用项目的时间顺序。特别是SASRec模型,受自然语言处理中流行的Transformer模型的启发,取得了SOTA结果。然而,SASRec和最初的Transformer模型一样,本质上是一个非个性化的模型,不包括个性化的用户嵌入。
为了克服这一局限性,我们提出了一种个性化Transformer(SSE-PT)模型,在5个真实世界的数据集上的NDCG@10比SASRec高出近5%。此外,在研究了一些随机用户的参与历史之后,我们发现我们的模型不仅更易于解释,而且能够关注每个用户最近的参与模式。
此外,对我们的SSE-PT模型稍加修改—>SSE-PT++,它可以处理非常长的序列,并且在训练速度相当的情况下优于SASRec,在性能和速度要求之间取得了平衡。我们新颖地应用随机共享嵌入(SSE)正则化是个性化成功的关键。
NeurIPS 2020录用结果已出,欢迎各位作者投稿
![]()