一文看懂滴滴的人脸口罩识别技术和国际CV比赛进展


桔妹导读:2020年新春伊始,新冠疫情爆发。为有效预防感染,保障司乘生命安全,滴滴利用在计算机视觉技术的多年研发积累,研制了口罩识别防疫系统。本文重点介绍口罩识别系统的框架、原理和方法,同时也介绍图像技术团队今年在国际计算机视觉领域的比赛进展。





-
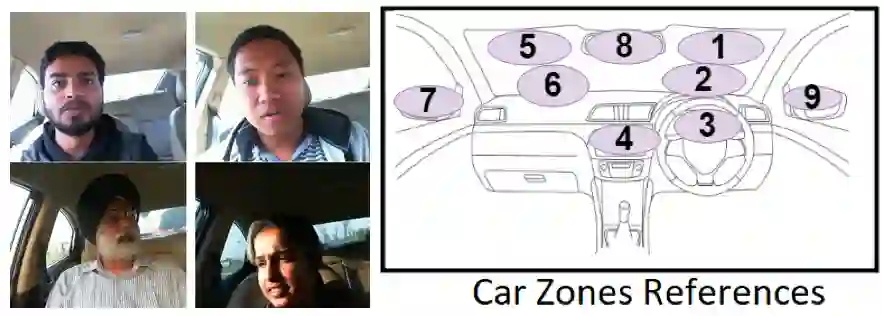
数据集中视线区域即包含跨度较大的左右后视镜,也包含跨度距离较近的仪表盘、正前方和正上方等区域; -
数据集中司机包含不同的年龄、性别、装扮的差异,以及眼镜、墨镜等不同物体的面部遮挡,反光、模糊等图像质量影响; -
数据采集拍摄所用的摄像头的位置也是不同的,有在正上方的,也有在下方中控台位置的,因而成像角度差异巨大。



-
通过视频理解的方向,对视频做end-end的建模,通过时序建模抽取有用的语义信息来建模,获取视频的分类; -
通过人脸表情的方向,通过提取视频的人脸特征,并利用人脸特征的时序来建模; -
通过肢体方向,使用人脸、肢体关键点的特征来建模,有利于提取视频的行为特征; -
通过融合视频、人脸表情、肢体等多个维度的特征,来实现最终的模型输出。




-
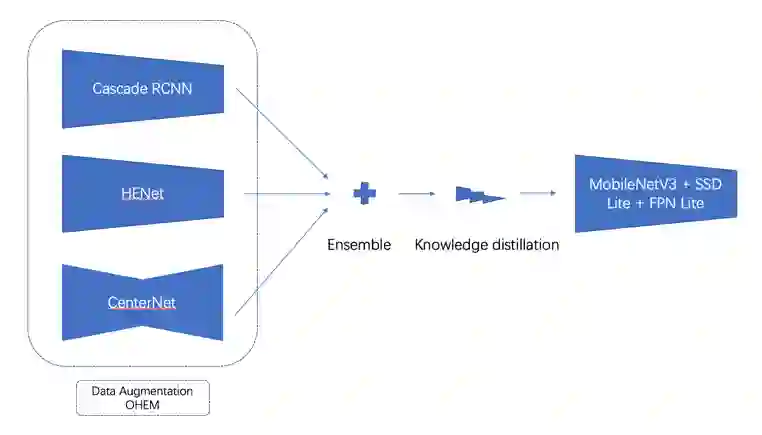
数据集中含有大量受黑夜、雨雾、抖动等低质量样本,整体数据集难度较大; -
数据集分布极不均衡:大量的数据样本集中在汽车这个类别上,而其他类别尤其是自行车的数据样本极为稀疏; -
数据集标注标准不统一:部分受遮挡的目标标注标准不统一;
▬
![]()
2017年6月加入滴滴,任首席算法工程师,负责交通出行场景中的图像技术研发工作。2006年博士毕业于北京邮电大学,博士论文获得2007年北京邮电大学优秀学位论文。曾在松下、百度和微软等多家知名公司工作,专注于AI技术研发。近年了参加过多个国际计算机视觉比赛,荣获多个第一。在NeurIPS、CVPR、ECCV、PKDD、LNCS、LNAI等发表近20篇论文,在国内外申请发明专利近百项。

团队招聘
▬
滴滴图像技术团队基于滴滴积累的海量交通出行场景数据,研发各种视觉感知、识别和理解技术,包括人脸识别、光学字符识别、目标识别和视频理解等,并成功地将这些技术应用于司机服务质检、司乘安全、智慧交通等各个领域,为出行安全和乘车体验保驾护航。
团队长期招聘计算机视觉工程师和专家,工作内容包括不局限于:目标检测/分类/跟踪/理解,人体关键点检测,语义标注,场景分析,视频分析,视频动作/行为/关系理解,光学字符识别,人脸/行人识别等。欢迎有兴趣的小伙伴加入,可投递简历至 diditech@didiglobal.com,邮件请邮件主题请命名为「姓名-应聘部门-应聘方向」。

扫码了解更多岗位
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文