GPT-GNN:图神经网络的生成式预训练方法

作者 | Dyson
GNN通过端到端的有监督学习训练对于某一输入图上的一个任务,但是对于同一输入图数据,当训练的目标任务变化时,往往只能通过不同任务对应不同标注的数据集训练对应于每个任务的专用GNN网络模型。
事实上,在NLP任务中也同样存在着类似的问题,作者利用自然语言处理中预训练的思想: "从大量的未标记语料库中训练一个模型,然后将学习到的模型转移到只有少量标记的下游任务",尝试通过对图神经网络进行预训练,使得GNN能够捕获输入图的结构和语义属性,从而轻松地将其推广到任何下游任务。
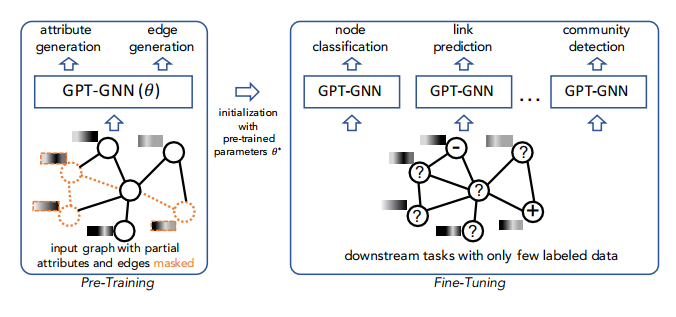
GNN的预训练
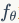 对于任意的一个没有标注的图数据
对于任意的一个没有标注的图数据
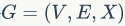 ,
仍然能够针对不同的下游任务进行良好的初始化。
而对于如何建立一个预训练GNN的无监督学习的任务,作者采用了生成式的方法,通过生成图的节点属性和图的结构信息,来提供无监督数据供GNN进行预训练。
,
仍然能够针对不同的下游任务进行良好的初始化。
而对于如何建立一个预训练GNN的无监督学习的任务,作者采用了生成式的方法,通过生成图的节点属性和图的结构信息,来提供无监督数据供GNN进行预训练。
生成式预训练框架
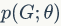 来描述图
来描述图
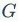 中
节点的属性和相互的连接关系,预训练的目标是寻找最大的参数值
中
节点的属性和相互的连接关系,预训练的目标是寻找最大的参数值
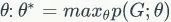 。
这里的参数
。
这里的参数
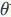 可以代表是图中的节点属性与连边关系(即图的结构信息)。
可以代表是图中的节点属性与连边关系(即图的结构信息)。
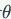 代表的节点和边进行逐个生成,并记图中第
代表的节点和边进行逐个生成,并记图中第
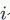 个位置,排列数为
个位置,排列数为
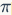 的节点为
的节点为
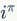 。
通过这种方法,将变量
。
通过这种方法,将变量
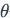 分解为不同排列的属性值和连边值,即:
分解为不同排列的属性值和连边值,即:
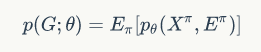
 的节点的概率都是相同的,那么对于一个固定的节点排列,自回归概率的对数展开式可以表示为
的节点的概率都是相同的,那么对于一个固定的节点排列,自回归概率的对数展开式可以表示为
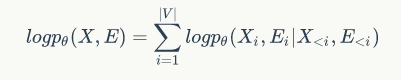
 中,我们使用所有在
之前生成的节点属性,以及这些节点之间的结构(边)来生成一个新节点
中,我们使用所有在
之前生成的节点属性,以及这些节点之间的结构(边)来生成一个新节点
 ,所以生成模型问题转化成了上式中的条件概率如何确定的问题。
,所以生成模型问题转化成了上式中的条件概率如何确定的问题。
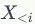 与节点对应的连边
与节点对应的连边
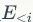 相互独立,就会忽略掉属性与图结构信息之间重要的关联关系,相当于并没有发挥出GNN处理图结构化数据过程中的信息聚合的能力,因此做GNN的预训练任务需要寻求新的解决方法。
相互独立,就会忽略掉属性与图结构信息之间重要的关联关系,相当于并没有发挥出GNN处理图结构化数据过程中的信息聚合的能力,因此做GNN的预训练任务需要寻求新的解决方法。
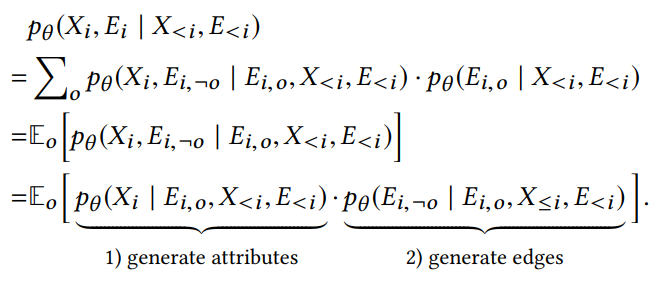
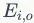 表示已知的结构信息,
表示已知的结构信息,
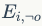 表示生成的边(在数据处理中,作者采用mask的方式处理成节点剩余的连接关系)。
表示生成的边(在数据处理中,作者采用mask的方式处理成节点剩余的连接关系)。
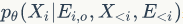 表示利用前
表示利用前
 个点的属性信息与结构信息,以及当前节点的已知结构信息(即利用节点
个点的属性信息与结构信息,以及当前节点的已知结构信息(即利用节点
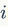 的邻点信息),生成当前第
个节点的属性。第二项
的邻点信息),生成当前第
个节点的属性。第二项
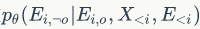 代表通过当前节点的已知结构信息与前
代表通过当前节点的已知结构信息与前
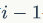 个点的属性信息与结构信息生成当前节点的余下连边信息。
个点的属性信息与结构信息生成当前节点的余下连边信息。
属性和结构信息生成
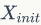 来表示这些屏蔽的属性。
而对于连边生成的节点,作者保留它们的属性信息,直接将两者(属性信息与结构信息)一并送入GNN中做信息聚合。
来表示这些屏蔽的属性。
而对于连边生成的节点,作者保留它们的属性信息,直接将两者(属性信息与结构信息)一并送入GNN中做信息聚合。
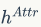 与
与
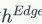 。
因为属性节点生成中使用了虚拟标记进行过替换,
相较于
。
因为属性节点生成中使用了虚拟标记进行过替换,
相较于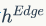 包含更少的信息,因此在GNN的信息传递过程中作者只用
,然后使用不同的解码器来对这两种不同类型的节点表示
与
进行属性和连边的生成。
包含更少的信息,因此在GNN的信息传递过程中作者只用
,然后使用不同的解码器来对这两种不同类型的节点表示
与
进行属性和连边的生成。
 ,
当该距离取得最小值时,等价于得到上述公式第一项
,
当该距离取得最小值时,等价于得到上述公式第一项
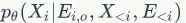 的最大似然概率(相当于最大化观察每个节点属性的可能性),从而使预训练后的模型捕捉到图数据的语义特征。
的最大似然概率(相当于最大化观察每个节点属性的可能性),从而使预训练后的模型捕捉到图数据的语义特征。
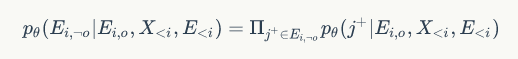
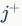 中通过负采样
中通过负采样
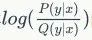 的方法,从所有没有连接的节点与所有有连接的节点中采样有连接但是没有连边信息(remaining edges)的节点,计算通过连边生成节点训练的loss函数:
的方法,从所有没有连接的节点与所有有连接的节点中采样有连接但是没有连边信息(remaining edges)的节点,计算通过连边生成节点训练的loss函数:
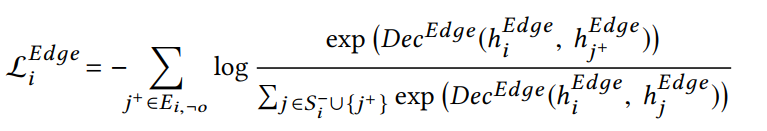
 ,
接着,随机选择数据中的一部分目标节点的边作为已知结构信息
,
接着,随机选择数据中的一部分目标节点的边作为已知结构信息
 ,
则数据中剩下未被选择的边
则作为被mask掉的边在数据处理中被删除(对应数据集给出的邻接矩阵也同样需要变化)。
接着将图中的每个节点划分为由属性生成的节点和由边生成节点。
,
则数据中剩下未被选择的边
则作为被mask掉的边在数据处理中被删除(对应数据集给出的邻接矩阵也同样需要变化)。
接着将图中的每个节点划分为由属性生成的节点和由边生成节点。
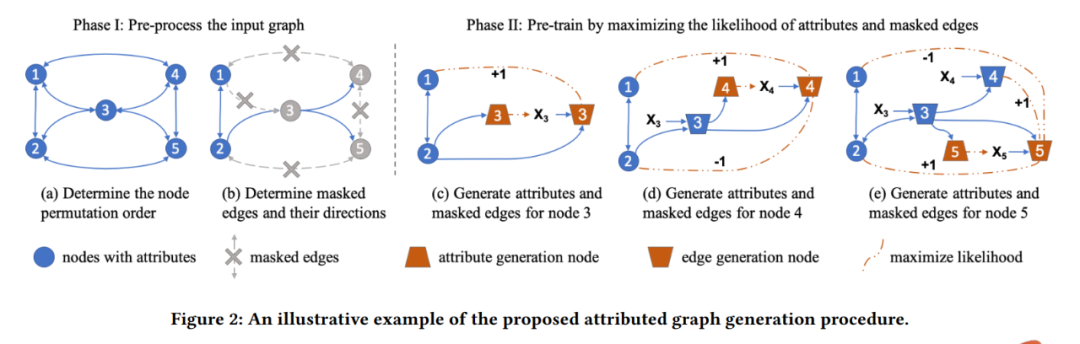
GPT-GNN在异构图和大规模图数据上的表现
模型评价与实验
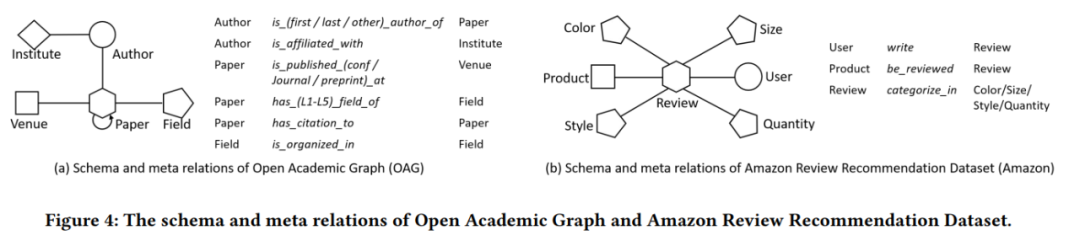
基线设置
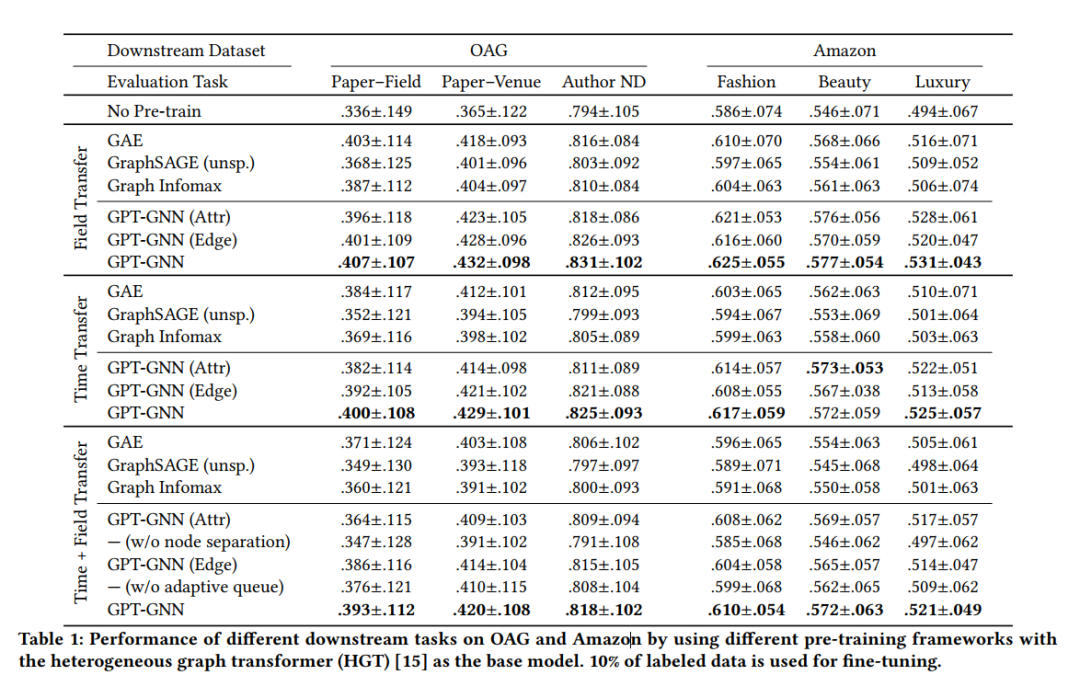
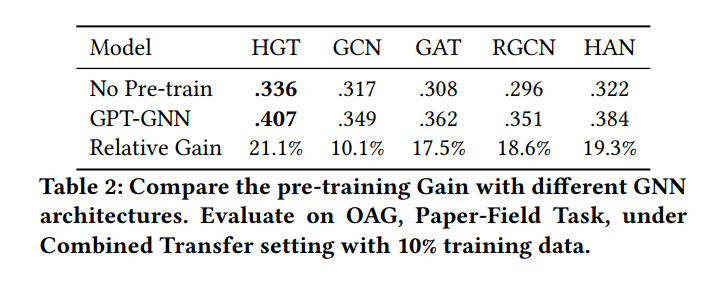
预训练和Fine-Tuning
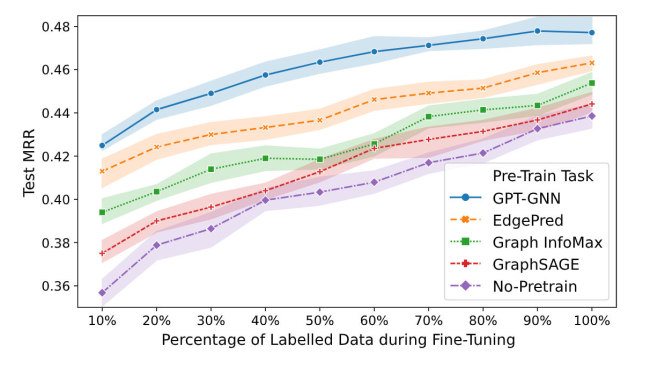
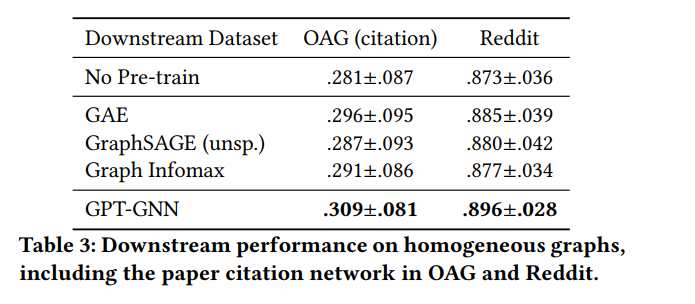
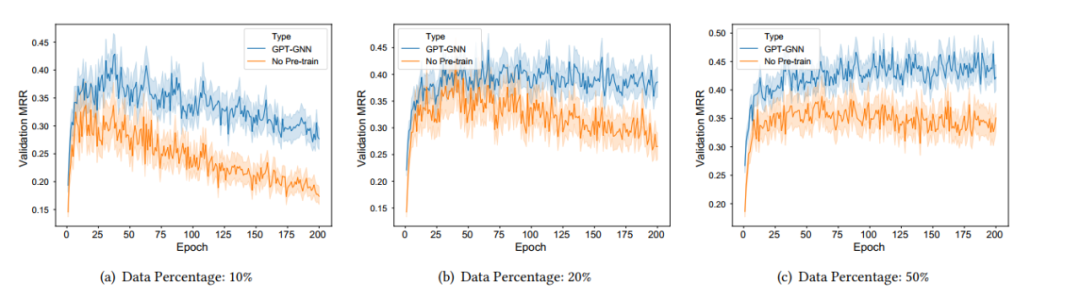
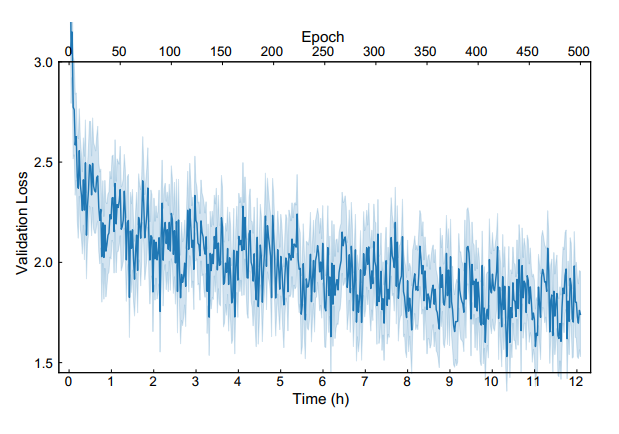
结论
AI科技评论联合博文视点赠送周志华教授“森林树”十五本,在“周志华教授与他的森林书”一文留言区留言,谈一谈你和集成学习有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,每人送出《集成学习:基础与算法》一本。
活动规则:
1. 在“周志华教授与他的森林书”一文留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年8月23日 - 2020年8月30日(23:00),活动推送内仅允许中奖一次。

阅读原文,直达“ KDD”小组,了解更多会议信息!
登录查看更多
相关内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
78+阅读 · 2020年3月1日



相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
78+阅读 · 2020年3月1日
相关资讯
相关论文