从知识图谱到认知图谱: 历史、发展与展望
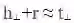 ,图4为TransH模型向量空间的示意图。这个方向的众多改进工作,如TransR[16]、TransG[17]等在Wang等人[18]的综述中得到了很好的概括。
,图4为TransH模型向量空间的示意图。这个方向的众多改进工作,如TransR[16]、TransG[17]等在Wang等人[18]的综述中得到了很好的概括。
丁铭
CCF学生会员。清华大学博士生。主要研究方向为自然语言处理、图学习和认知智能。dm_thu@qq.com

阅读原文,直达“ KDD”小组,了解更多会议信息!
登录查看更多
相关内容

人工智能已经在“听、说、看”等感知智能领域达到或超越了人类水准,但在需要外部知识、逻辑推理或者领域迁移的认知智能领域还处于初级阶段。认知图谱将从认知心理学、脑科学及人类社会历史中汲取灵感,并结合跨领域知识图谱、因果推理、持续学习等技术,建立稳定获取和表达知识的有效机制,让知识能够被机器理解和运用,实现从感知智能到认知智能的关键突破。认知图谱(Cognitive Graph)旨在结合认知心理学、脑科学和人类知识,研发知识图谱、认知推理、逻辑表达的新一代认知引擎,实现人工智能从感知智能向认知智能的演进。认知图谱是计算机科学的一个研究分支,它企图了解智能的实质,并实现感知智能系统到认知智能系统的重大技术突破。该领域的研究包括认知图谱表示、认知图谱构建、认知图谱推理、认知图谱应用等。




相关VIP内容
相关资讯
相关论文