图嵌入模型综述: 方法、数据集与应用
转自:Coggle数据科学
图分析用于深入挖掘图数据的内在特征,然而图作为非欧几里德数据,传统的数据分析方法普遍存在较高的计算量和空间开销。图嵌入是一种解决图分析问题的有效方法,其将原始图数据转换到低维空间并保留关键信息,从而提升节点分类、链接预测、节点聚类等下游任务的性能。
图是复杂系统中常用的信息载体,可以表示现实中许多复杂关系,如社交网络、犯罪网络、交通网络等。图结构作为一种非欧几里德数据,很难直接应用卷积神经网络和循环 神经网络。
为了构造用于图数据挖掘的特征表示,图嵌入将节点映射到低维空间,生成保留原始图中某些重要信息的低维向量。目前,图嵌入不仅在节点分类、链接预测、节点聚类、可视化等复杂网络上的机器学习任务中获得成功,还广泛用于社交影响力建模、内容推荐等现实任务。
图嵌入定义
-
图:表示为 ,其中 表示节点集, 表示边集。
-
静态图:给定图 ,如果节点和边的不随时间变化,图 为静态图。
-
动态图:按时间分成一系列演化图 , 表示演化图的数量,每个演化图 表示 时刻的状态。
-
一阶相似度:节点之间的成对邻近度。
-
二阶相似度:节点邻域结构的相似度。
-
图嵌入 :将每个节点映射成低维向量表示,保留了原始图中某些关键信息。

图嵌入分类
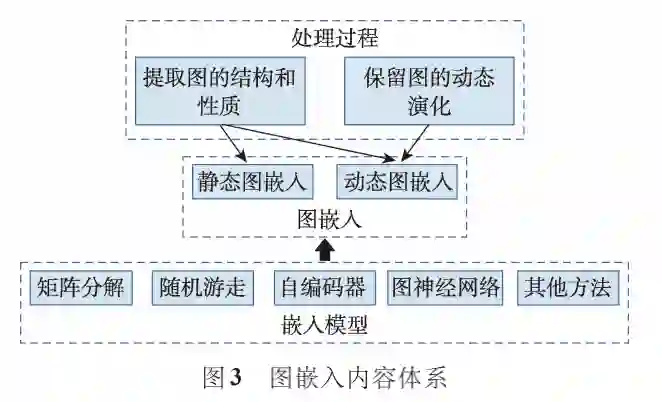
基于矩阵分解的图嵌入
基于矩阵分解的图嵌入通过分解节点关系矩阵获得低维嵌入。不同的关系矩阵采用的分解方法不同 ,例如邻接矩阵通常使用奇异值分解(SVD)的方法生成节点嵌入,而属性矩阵通常使用特征值分解的方法。
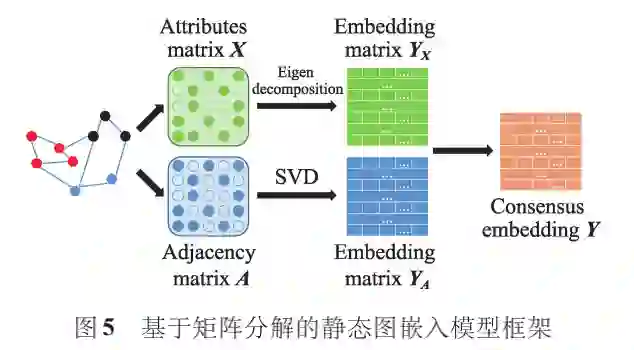
基于矩阵分解的静态图嵌入
基于矩阵分解的静态图嵌入模型对节点关联信息矩阵和属性信息矩阵进行特征分解,然后将分解得到的属性嵌入和结构嵌入进行融合,生成节点的低维嵌入表示。
局部线性映射LLE将每个节点表示为相邻节点的线性组合,构造邻域保持映射。具体实现分为三步:
-
以某种度量方式(如欧氏距离)选择 k个邻近节点; -
由 k个近邻线性加权重构节点,并最小化节点重建误差获得最优权重; -
最小化最优权重构建的目标函数生成 Y
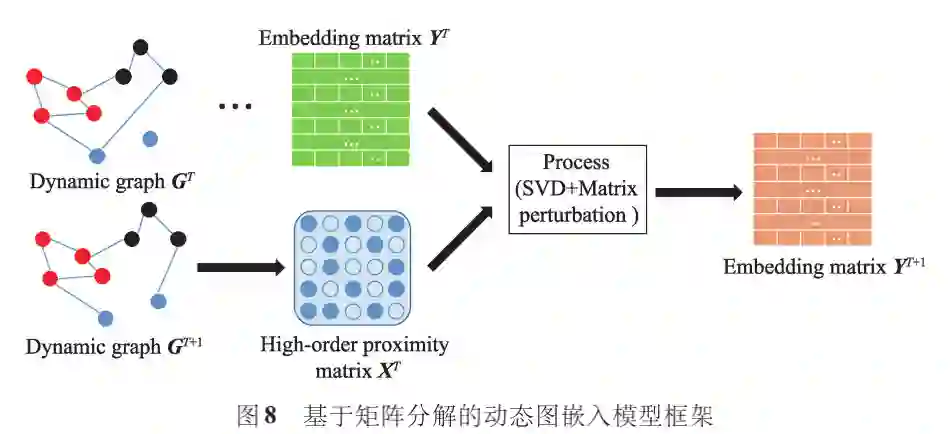
基于矩阵分解的动态图嵌入
基于矩阵分解的动态图方法利用特征分解构造图的高阶相似度矩阵,然后利用矩阵摄动理论更新图的动态信息。DANE采用分布式框架:离线部分,采用最大化相关性的方法捕捉图结构和节点属性的依赖关系;在线部分,使用矩阵摄动理论更新嵌入的特征值和特征向量。
基于随机游走的图嵌入
受word2vec的启发,基于随机游走的图嵌入方法将节点转化为词,将随机游走序列作为句子,利用Skip-Gram 生成节点的嵌入向量。随机游走法可以保留图的结构特性,并且在无法完整观察的大型图上仍有不错的表现。
基于随机游走的静态图嵌入
基于随机游走的静态图嵌入模型通过随机游走获得训练语料库,然后将语料库集成到 Skip-Gram 获得节点的低维嵌入表示。Deepwalk使用随机游走对节点进行采样,生成节点序列,再通过 Skip-Gram 最大化节点序列中窗口范围内节点之间的共现概率。
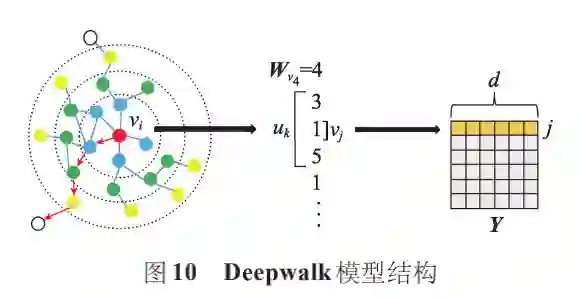
Deepwalk 不仅在数据量较少时有较好的表现,还可以扩展到大型图的表示学习。由于优化过程中未使用明确的目标函数,使得模型保持网络结构的能力受到限制。
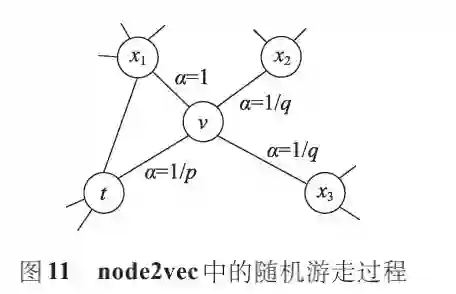
node2vec在 Deepwalk的基础上,引入有偏的随机游走,增加邻域搜索的灵活性,生成质量更高、信息更多的嵌入表示。通过设置 p 和 q 两个参数,平衡广度优先搜索和深度优先搜索策略,使生成的嵌入能够保持社区结构等价性或邻域结构等价性。
基于随机游走的动态图嵌入
CTDNE利用时间随机游走从连续型动态图中学习包含时间信息的嵌入表示。,CTDNE 采用的时间随机游走与静态图方法相似,但约束每个随机游走符合边出现的时间顺序,即边的遍历必须按照时间递增的顺序,由于每条边包含多个时间戳,使得同一节点可能在游走中出现多次。
基于自编码器的图嵌入
自编码器使隐藏层学习到的表示维度小于输入数据,即对原始数据进行降维。基于自编码器的图嵌入方法使用自编码器对图的非线性结构建模,生成图的低维嵌入表示。
基于自编码器的静态图嵌入
基于自编码器的图嵌入方法起源于使用稀疏自编码器的 GraphEncoder。其基本思想是将归一化的图相似度矩阵作为节点原始特征输入到稀疏自编码器中进行分层预训练,使生成的低维非线性嵌入可以近似地重建输入矩阵并保留稀疏特性。
基于自编码器的动态图嵌入
基于自编码器的动态图方法将每个时刻训练的参数作为下一时刻自编码器的初始值,从而在一定程度上保持生成嵌入的稳定性,提高模型的计算效率。
基于图神经网络的图嵌入
图神经网络(GNN)是专门处理图数据的深度模型,其利用节点间的消息传递来捕捉某种依赖关系,使生成的嵌入可以保留任意深度的邻域信息。
基于图神经网络的静态图嵌入
基于 GNN的静态图模型聚合节点邻域的嵌入并不断迭代更新,利用当前的嵌入及上一次迭代的嵌入生成新的嵌入表示。
-
GraphSAGE 不是为每个节点训练单独的嵌入,而是通过采样和聚合节点的局部邻域特征训练聚合器函数,同时学习每个节点邻域的拓扑结构及特征分布,生成嵌入表示。 -
图注意力网络(graph attention network,GAT)在 GCN 的基础上引入注意力机制,对邻近节点特征加权求和,分配不同的权值。
基于图神经网络的动态图嵌入
基于 GNN的动态图模型通常在静态图模型的基础上,引入一种循环机制更新网络参数,实现动态过程的建模,使生成低维嵌入可以有效保留图的动态演化信息。
-
DyRep将动态图嵌入假设为图的动态(拓扑演化)和图上的动态交织演化(节点间的活动)的中介过程。 -
DySAT通过邻域结构和时间两个维度的联合自注意力来计算节点嵌入,结构注意力块通过自注意聚集和堆叠从每个节点局部邻域中提取特征。
基于其他方法的图嵌入
LINE同样定义了一阶相似度和二阶相似度函数,并对其进行优化。一阶相似度用于保持邻接矩阵和嵌入表示的点积接近,二阶相似度用于保持上下文节点的相似性。LINE 分别优化一阶和二阶相似度的目标函数,然后将生成的嵌入向量进行拼接。
数据集与应用
静态图嵌入数据集
-
20-Newsgroup:由大约 20 000 个新闻组文档构成的数据集。这些文档根据主题划分成 20 个组,每个文档表示为每个词的 TF-IDF 分数向量,构建余弦相似图。为了证明聚类算法的稳健性,分别从 3、6和 9 个不同的新闻组构建了 3 个图。
-
Flickr:由照片分享网站 Flickr 上的用户组成的网络。网络中的边指示用户之间的联系关系。标签指示用户的兴趣组(例如黑白色摄影)。
-
DBLP:引文网络数据集,每个顶点表示一个作者,从一个作者到另一个作者的参考文献数量由这两个作者之间的边权重来记录。标签上标明了研究人员发表研究成果的 4个领域。
-
YouTube:YouTube 视频分享网站用户之间的社交网络。标签代表了喜欢视频类型(例如动漫视频)的观众群体。
-
Wikipedia:网页共现网络,节点表示网页,边表示网页之间的超链接。Wikipedia数据集的 TF-IDF矩阵是描述节点特征的文本信息,节点标签是网页的类别。
-
Cora、CiteSeer、Pubmed:标准的引文网络基准数据集,节点表示论文,边表示一篇论文对另一篇论文的引用。节点特征是论文的词袋表示,节点标签是论文的学术主题。
-
Yelp:本地商业评论和社交网站,用户可以提交对商家的评论,并与其他人交流。由于缺乏标签信息,该数据集常用于链接预测。
动态图嵌入数据集
-
Epinions:产品评论网站数据集,基于评论的词袋模型生成节点属性,以用户评论的主要类别作为类别标签。该数据集有 16个时间戳。
-
Hep-th:高能物理理论会议研究人员的合作网络,原始数据集包含 1993 年 1 月至 2003 年 4 月期间高能物理理论会议的论文摘要。
-
AS(autonomous systems):由边界网关协议日志构建的用户通信网络。该数据集包含从 1997年 11月 8 日到 2000 年 1 月 2 日的 733 条通信记录,通常按照年份将这些记录划分为不同快照。
-
Enron:Enron 公司员工之间的电子邮件通信网络。该数据集包含 1999 年 1 月至 2002 年 7 月期间公司员工之间的电子邮件。
-
UCI:加州大学在线学生社区用户之间的通信网络。节点表示用户,用户之间的消息通信表示边缘。每条边携带的时间指示用户何时通信。
图嵌入任务
网络重构
网络重构任务是利用学习到节点低维向量表示重新构建原始图的拓扑结构,评估生成的嵌入保持图结构信息的能力。好的网络嵌入方法能够捕捉到具有网络结构信息的嵌入表示,从而能够很好地重构网络。
节点分类
节点分类任务是利用图的拓扑结构和节点特征确定每个节点所属类别。节点分类任务可以利用已有标签节点和连接关系来推断丢失的标签。
链接预测
链接预测任务用于预测两个节点之间是否存在边或者预测图中未观察到的链接,评估生成嵌入在保持拓扑结构方面的性能。
聚类
聚类任务采用无监督的方式将图划分为若干个社区,使属于同一社区的节点具有更多相似特性。将生成的嵌入表示进行聚类,使具有相似特性的节点尽可能在同一社区。在。
异常检测
异常检测任务用于识别图中的“非正常”结构,通常包括异常节点检测、异常边缘检测和异常变化检测。图数据的异常检测主要是找出与正常数据集差异较大的离群点(异常点)。
可视化
可视化任务是对嵌入进行降维和可视化,从而直观地观察原始图中某些特征。对于可视化任务,好的嵌入表示在二维图像中相同或相近的节点彼此接近,不同的节点彼此分离。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
