CVPR 2020 | 如何同时保证NAS的效率和有效性?暗物智能等提出基于知识蒸馏的分块监督神经网络搜索算法
机器之心编辑部
近日,计算机视觉顶会 CVPR 2020 接收论文结果公布,从 6656 篇有效投稿中录取了 1470 篇论文,录取率约为 22%。本文介绍了 暗物智能研究院和蒙纳士大学 等被 CVPR 2020 接收的一篇论文《Blockwisely Supervised Neural Architecture Search with Knowledge Distillation》。

论文链接:https://arxiv.org/abs/1911.13053
代码链接:https://github.com/changlin31/DNA
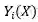 为超网的第 i 个块的输出特性图。采用 L2 范数作为损失函数,以 K 表示 Y 中神经元的数目,方程中的损失函数可以写为
为超网的第 i 个块的输出特性图。采用 L2 范数作为损失函数,以 K 表示 Y 中神经元的数目,方程中的损失函数可以写为
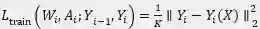 , 值得注意的是,对于每个块,作者使用教师模型的第(i-1)个块的输出 Y_(i-1) 作为超网的第 i 个块的输入。如此可以有效的将超网的各模块独立开,且能以并行的方式加快超网训练速度。
, 值得注意的是,对于每个块,作者使用教师模型的第(i-1)个块的输出 Y_(i-1) 作为超网的第 i 个块的输入。如此可以有效的将超网的各模块独立开,且能以并行的方式加快超网训练速度。

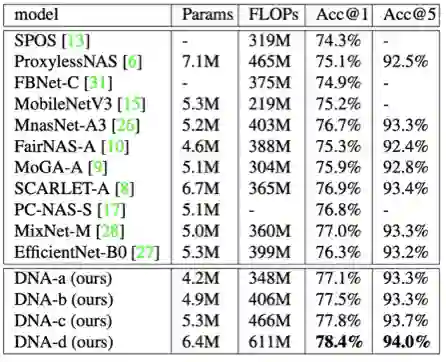
表1: ImageNet 结果对比。
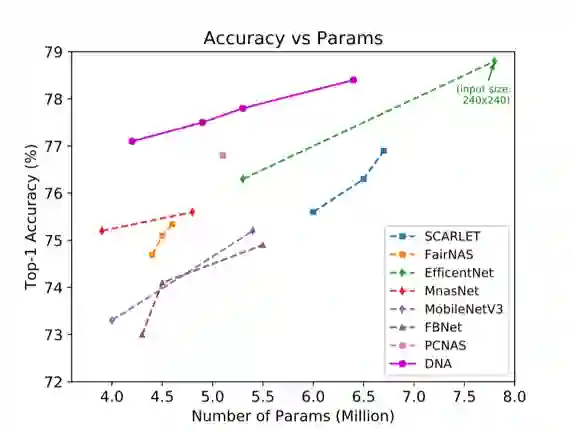
图2: ImageNet 精度-参数量对比图。

表2: 迁移学习结果对比。

图3: DNA-SPOS模型排序对比图。
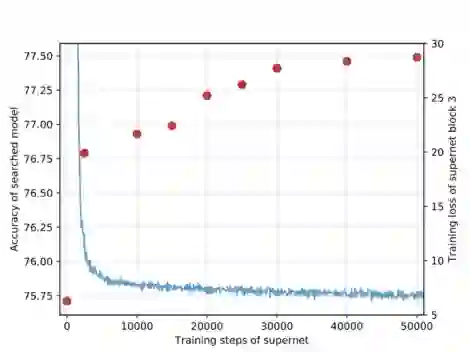

图5: 训练过程教师网络-超网特征图对比。
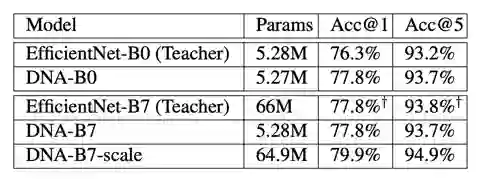
表3: 教师模型对比。
登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文