基于维基百科的图像文本数据集 (WIT)


发布人:Google Research 软件工程师 Krishna Srinivasan 和 研究员 Karthik Raman
多模式视觉语言模型依赖大量数据集来对图像和文本之间的关系进行建模。一般来说,这些数据集有两种创建方法:手动为图像添加文字说明,或抓取网页并提取替代文本 (alt-text) 作为文字说明。虽然前一种方法更利于产生更高质量的数据,但高强度的人工注释过程限制了可创建的数据量。另一方面,虽然自动提取方法可以产生更大的数据集,但却需要通过启发式算法以及仔细过滤来确保数据质量,或者扩展模型来保证强大性能。现有数据集的另一个缺点是极少涉及非英语语言。这不禁让我们产生疑问:我们能否突破这些限制,创建包含各种内容的高质量、大规模、多语言数据集?
图像和文本之间的关系
https://ai.googleblog.com/2014/11/a-picture-is-worth-thousand-coherent.html
确保数据质量
https://ai.googleblog.com/2018/09/conceptual-captions-new-dataset-and.html
对此,我们推出了基于维基百科的图像文本 (WIT) 数据集。这是一个大型多模式数据集,通过从维基百科文章和 Wikimedia 图像链接中提取与图像相关的多种不同文本选择集创建而成。在创建过程中会执行严格的过滤环节,以便仅保留高质量的图像文本集。
基于维基百科的图像文本 (WIT) 数据集
https://github.com/google-research-datasets/wit
如我们在 SIGIR 2021 上发布的“WIT:适用于多模式、多语言机器学习的基于维基百科的图像文本数据集 (WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning)”中详细说明的那样,该过程产生一个包含 3750 万个实体丰富的图像文本示例精选集,其中涵盖 1150 万张独特的图像,跨越 108 种语言。大家可凭知识共享许可下载并使用 WIT 数据集。此外,我们也很高兴地宣布,我们将与 Wikimedia Research 以及其他外部协作者携手在 Kaggle 举办 WIT 数据集的竞赛。
WIT:适用于多模式、多语言机器学习的基于维基百科的图像文本数据集
https://dl.acm.org/doi/10.1145/3404835.3463257
下载并使用
https://github.com/google-research-datasets/wit
WIT 数据集的竞赛
https://www.kaggle.com/c/wikipedia-image-caption/overview
|
数据集 |
图像 数量 |
文本 |
上下文 文本 |
语言数量 |
|
Flickr30K |
32K |
158K |
- |
< 8 |
|
SBU Captions |
1M |
1M |
- |
1 |
|
MS-COCO |
330K |
1.5M |
- |
< 4;7 (仅限测试) |
|
CC-3M |
3.3M |
3.3M |
- |
1 |
|
CC-12M |
12M |
12M |
- |
1 |
|
WIT |
11.5M |
37.5M |
~119M |
108 |
相比以往数据集,WIT 的语言更多,规模更大
WIT 数据集的独特优势包括:
1. 大规模: WIT 是公开提供的最大的图像文本示例多模式数据集。
2. 多语言: WIT 拥有 108 种语言,是其他数据集的十倍或以上。
3. 上下文信息: 与典型的多模式数据集(每个图像只有一个文字说明)不同,WIT 包含许多页面级和部分级上下文信息。
4. 现实世界实体: 维基百科是一个覆盖广泛的知识库,其丰富的现实世界实体可以在 WIT 中得以体现。
5. 具有挑战性的测试集:在我们最近获得 EMNLP 接受的研究中,所有最先进的模型在 WIT 上表现出的性能都明显低于传统评估集,例如平均召回率 (recall) 下降约 30 点。
最近获得 EMNLP 接受的研究
https://arxiv.org/abs/2109.05125


WIT 的主要目标是在不牺牲质量和概念覆盖面的情况下创建大型数据集。因此,我们选择利用当今最大的在线百科全书:维基百科。
就可用信息的深度而言,我们以维基百科上的“Half Dome”(加州约塞米蒂国家公园)页面为例如下所示,文章为图像提供了许多有趣的文本说明和相关的上下文信息,如页面标题、主要页面描述以及其他上下文信息和元数据。
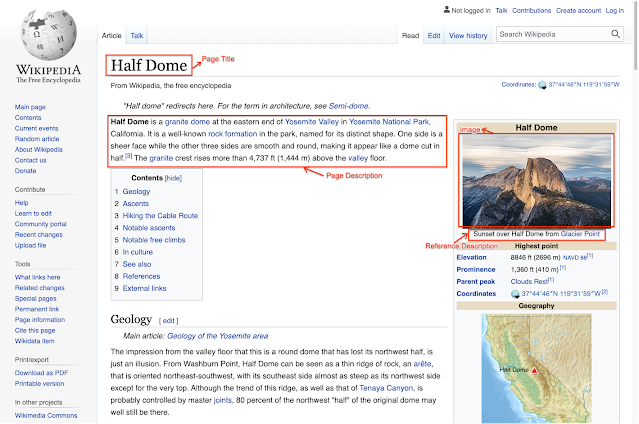
维基百科页面示例,其中包含可供提取的各种图像相关文本选择集和上下文。选自维基百科“Half Dome”页面:照片由 David Iliff 拍摄。许可证:CC BY-SA 3.0
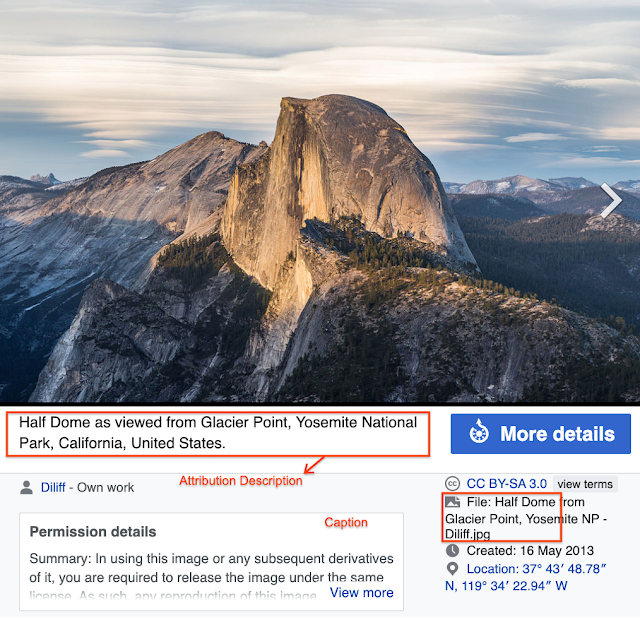
此特定“Half Dome”图像的维基百科页面示例。选自维基百科“Half Dome”页面:照片由 David Iliff 拍摄。许可证:CC BY-SA 3.0
我们首先选择包含图像的维基百科页面,然后提取各种图像文本关联内容和周围的上下文。为进一步优化数据,我们执行严格的过滤环节来确保数据质量。过滤过程包含:
●
基于文本的过滤,以确保文字说明的可用性、长度和质量(例如通过删除通用默认填充文本);
●
基于图像的过滤,以确保每个图像都具有特定的大小且拥有允许的许可;
●
基于图像和文本实体的过滤,以确保适合研究(例如排除仇恨类言论)。
接着我们进一步对图像文字说明集随机抽样,由真人进行校对评估,他们中绝大多数人都认可一个结论:98% 样本其图像与文字说明一致。
WIT 拥有 108 种语言的数据,是首个大规模、多语言、多模式数据集。
|
图像文本集数量 |
独特语言 数量 |
图像数量 |
独特语言 数量 |
|
> 1M |
9 |
> 1M |
6 |
|
500K - 1M |
10 |
500K - 1M |
12 |
|
100K - 500K |
36 |
100K - 500K |
35 |
|
50K - 100K |
15 |
50K - 100K |
17 |
|
14K - 50K |
38 |
13K - 50K |
38 |
WIT:跨语言覆盖统计信息

出现在十几个维基百科页面,且涵盖超过 12 种语言的图像示例。选自维基百科“Wolfgang Amadeus Mozart”页面
大多数多模式数据集仅为给定图像提供单个文本说明(或类似文字说明的多个版本)。WIT 是首个提供上下文信息的数据集, 可以帮助研究人员就上下文对图像文字说明以及图像选择的影响进行建模。
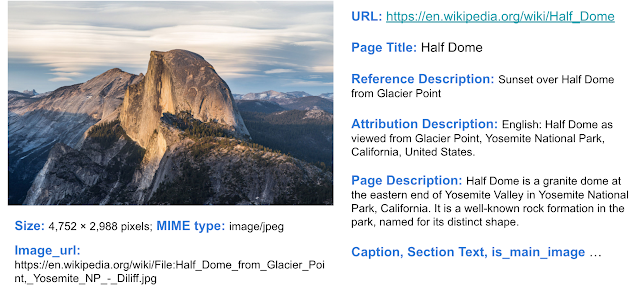
显示图像文本数据和额外上下文信息的 WIT 数据集示例
具体而言,可能有助于研究的 WIT 关键文本字段包括:
●
文本说明:WIT 提供三种不同的图像文字说明,包括(可能受上下文影响的)“参考描述”、(可能不受上下文影响的)“属性描述”,以及“替代文本描述”。
●
上下文信息:包括页面标题、页面描述、网址和有关维基百科部分的局部上下文(包括部分标题和文本)。
如下所示,WIT 在以下不同字段具有广泛的覆盖。
|
WIT 图像 文字字段 |
训练 |
Val |
测试 |
合计/独特 |
|
行/元组 |
37.1M |
261.8K |
210.7K |
37.6M |
|
独特的图像 |
11.4M |
58K |
57K |
11.5M |
|
参考描述 |
16.9M |
150K |
104K |
17.2M/16.7M |
|
属性描述 |
34.8M |
193K |
200K |
35.2M/10.9M |
|
替代文本 |
5.3M |
29K |
29K |
5.4M/5.3M |
|
上下文文本 |
- |
- |
- |
119.8M |
WIT 的关键字段兼有文本说明和上下文信息
维基百科广泛覆盖各种概念,这意味着 WIT 评估集作为评估基准非常具有挑战性,即使对于最先进的模型而言也是如此。在图像文本检索方面,我们发现传统数据集的平均召回分数 (mean recall scores) 为 80 秒,而对于 WIT 测试集而言,资源丰富的语言为 40 秒,资源不足的语言为 30 秒。我们希望这可以转而帮助研究人员构建更强大、更稳健的模型。
此外,非常高兴地宣布,我们将携手 Wikimedia Research 以及一些外部协作者共同组织 WIT 测试集的竞赛。竞赛将在 Kaggle 举办,竞赛任务为图像文本检索。我们将给定一组图像和文本说明,而参赛者的任务是为每个图像检索适当的文字说明。
为促进该领域的研究,维基百科为大部分训练和测试数据集提供了 300 像素分辨率的图像和基于 Resnet-50 的图像嵌入向量。除 WIT 数据集以外,Kaggle 还将托管所有图像数据,并提供 Colab notebooks。此外,参赛者届时可访问 Kaggle 论坛,以便分享代码和开展协作。任何对多模态感兴趣的人都可以借此轻松开始并运行实验。我们很高兴并且期待各位参赛者可以在 Kaggle 平台,通过 WIT 数据集和维基百科图像为我们带来精彩表现。
我们相信 WIT 数据集将帮助研究人员构建更好的多模态多语言模型,并识别更好的学习和表征技术,最终借助视觉语言数据在现实世界任务中优化机器学习模型。如有任何问题,请联系 wit-dataset@google.com。我们非常愿意倾听您如何使用 WIT 数据集。
我们想要感谢 Google Research 的共同作者:Jiecao Chen、Michael Bendersky 以及 Marc Najork。我们感谢 Beer Changpinyo、Corinna Cortes、Joshua Gang、Chao Jia、Ashwin Kakarla、Mike Lee、Zhen Li、Piyush Sharma、Radu Soricut、Ashish Vaswani、Yinfei Yang 以及审核者提供富有洞察力的反馈和评论。
我们感谢来自 Wikimedia Research 的 Miriam Redi 和 Leila Zia 与我们合作开展竞赛,并提供图像像素和图像嵌入向量数据。我们感谢 Addison Howard 和 Walter Reade 帮助我们在 Kaggle 举办这次竞赛。我们还要感谢 Diane Larlus (Naver Labs Europe (NLE))、Yannis Kalantidis (NLE)、Stéphane Clinchant (NLE)、EPFL 的博士生 Tiziano Piccardi、南安普敦大学的博士生 Lucie-Aimée Kaffee 以及 Yacine Jernite (Hugging Face) 对竞赛的重要贡献。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看