7 papers|EMNLP 2019最佳论文;Facebook语言模型XLM-R取得SOTA结果;最优学习的85%规则
机器之心整理
参与:杜伟、一鸣
本周的论文既揭幕了 EMNLP 2019 最佳论文,也有 Facebook 在多个跨语言理解基准上取得 SOTA 结果的新模型以及登上 Nature Communications 的最优学习 85% 规则。
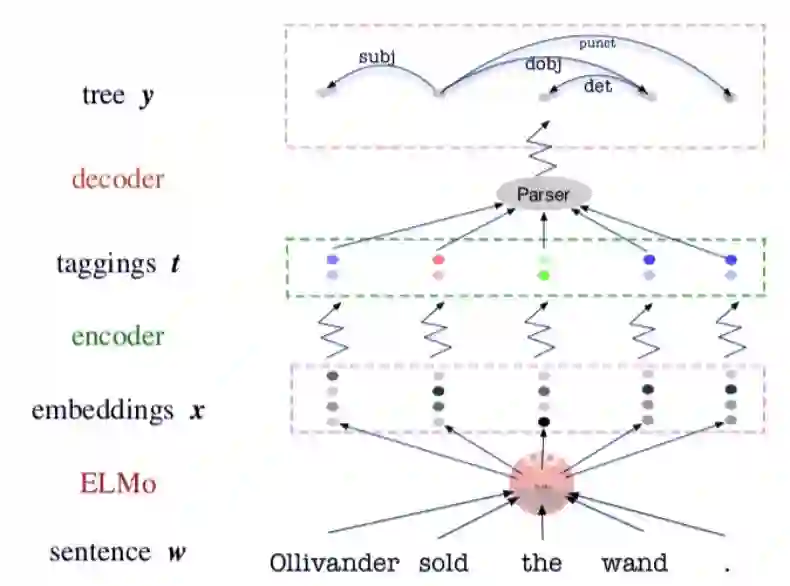
Specializing Word Embeddings(for Parsing)by Information Bottleneck
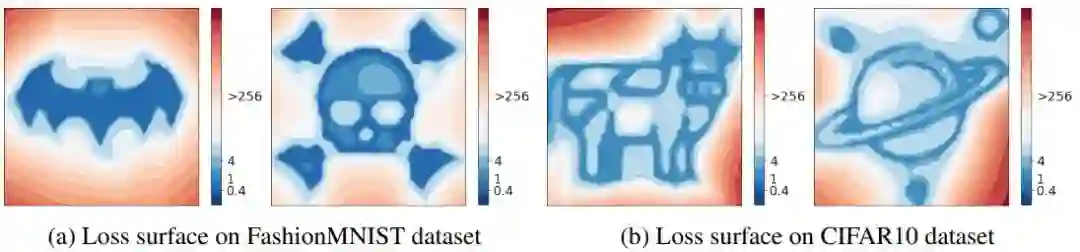
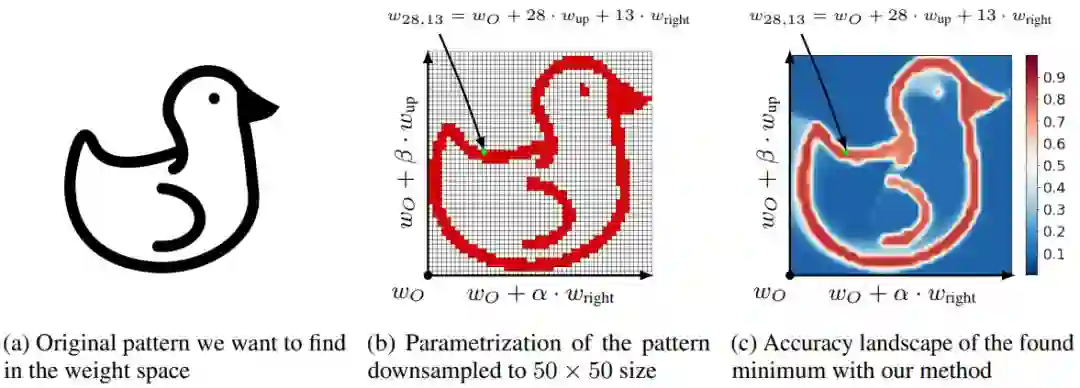
Loss Landscape Sightseeing with Multi-Point Optimization
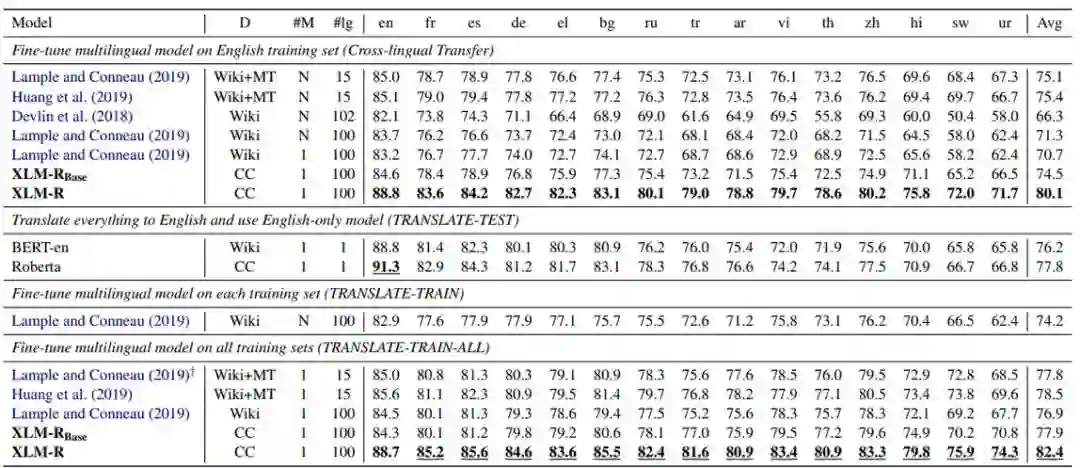
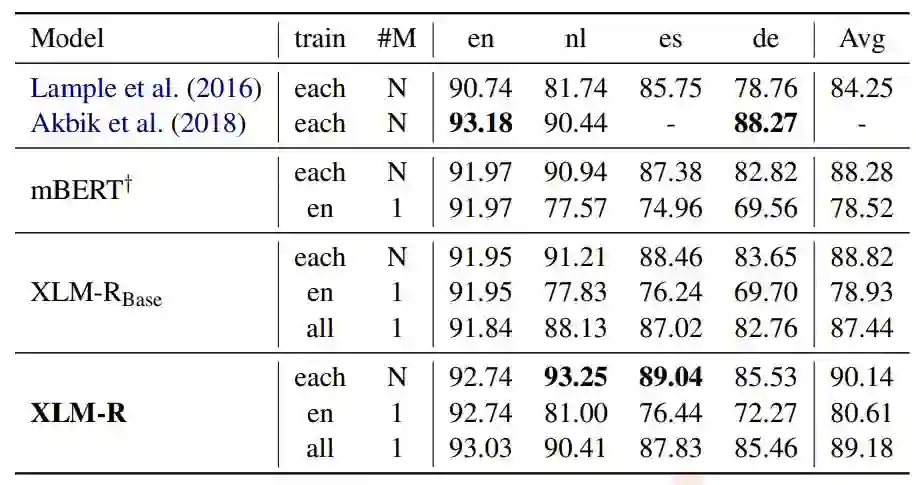
Unsupervised Cross-lingual Representation Learning at Scale
Understanding the Role of Momentum in Stochastic Gradient Methods
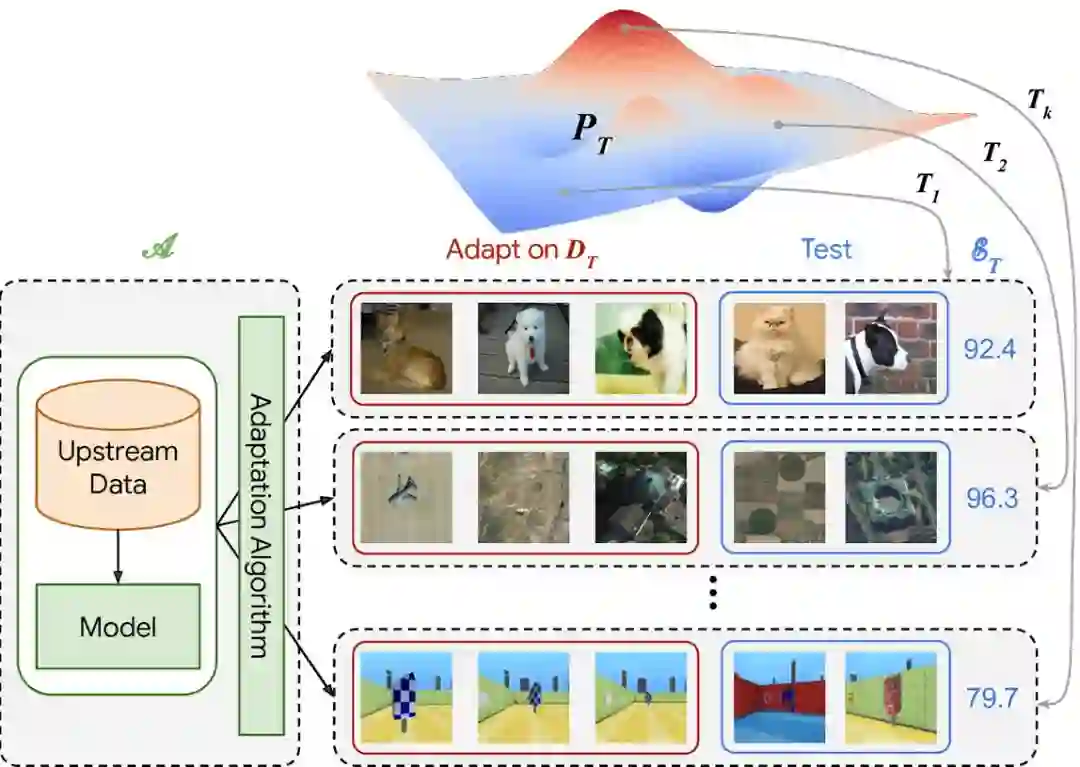
The Visual Task Adaptation Benchmark
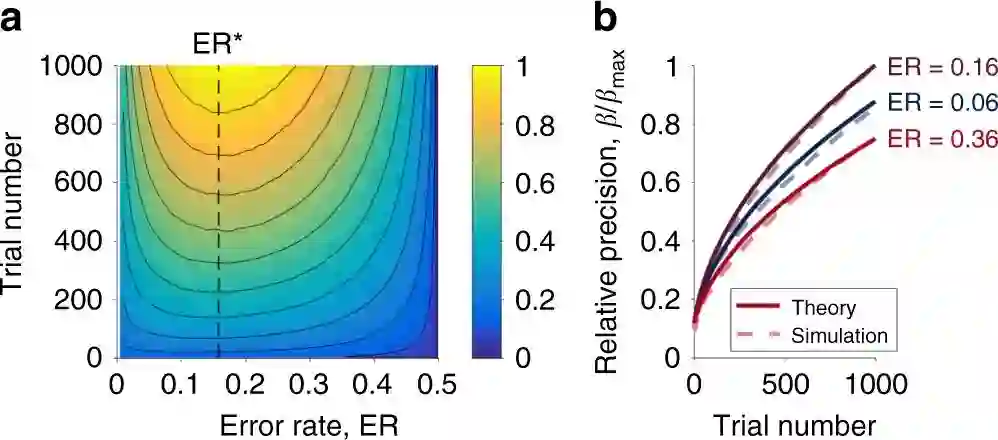
The Eighty Five Percent Rule for optimal learning
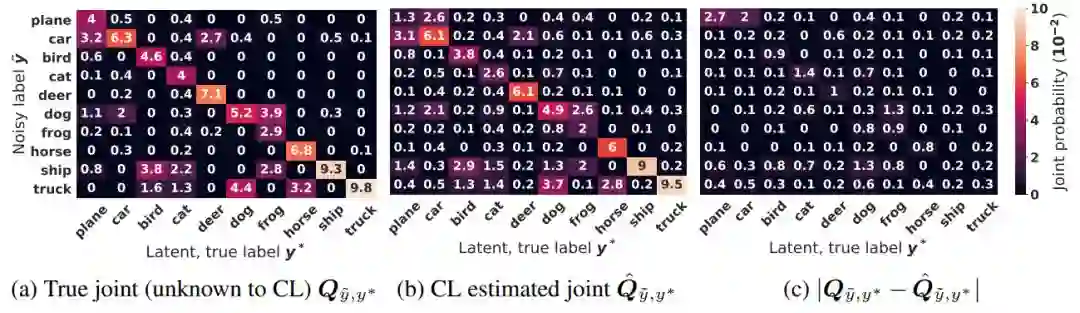
Confident Learning: Estimating Uncertainty in Dataset Labels
作者:Xiang Lisa Li、Jason Eisner
论文链接:http://cs.jhu.edu/~jason/papers/li+eisner.emnlp19.pdf
作者:Ivan Skorokhodov、Mikhail Burtsev
论文链接:https://arxiv.org/abs/1910.03867
项目地址:https://github.com/universome/loss-patterns
作者:Alexis Conneau、Kartikay Khandelwal、Naman Goyal、Vishrav Chaudhary、Guillaume Wenzek 等
论文链接:https://arxiv.org/abs/1911.02116
作者:Igor Gitman、Hunter Lang、Pengchuan Zhang、Lin Xiao
论文链接:https://arxiv.org/abs/1910.13962v1
作者:Xiaohua Zhai、Joan Puigcerver、Alexander Kolesnikov、Pierre Ruyssen 等
论文链接:https://arxiv.org/abs/1910.04867
作者:Robert C. Wilson、Amitai Shenhav、Mark Straccia、Jonathan D. Cohen
论文链接:https://www.nature.com/articles/s41467-019-12552-4
项目地址:https://github.com/bobUA/EightyFivePercentRule
作者:Curtis G. Northcutt、Lu Jiang、Isaac L. Chuang
论文链接:https://arxiv.org/abs/1911.00068
项目地址:https://pypi.org/project/cleanlab/
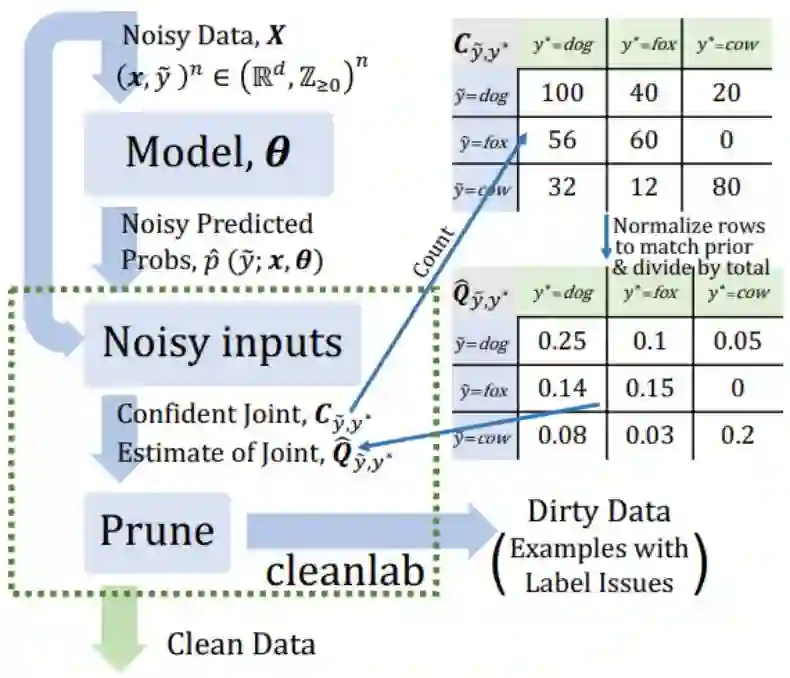
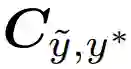 和估计联合分布
和估计联合分布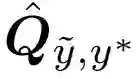 的示例。
的示例。