2D转3D,在《流浪地球》中感受太空漂浮,爱奇艺推出「会动的海报」
机器之心报道
参与:蛋酱
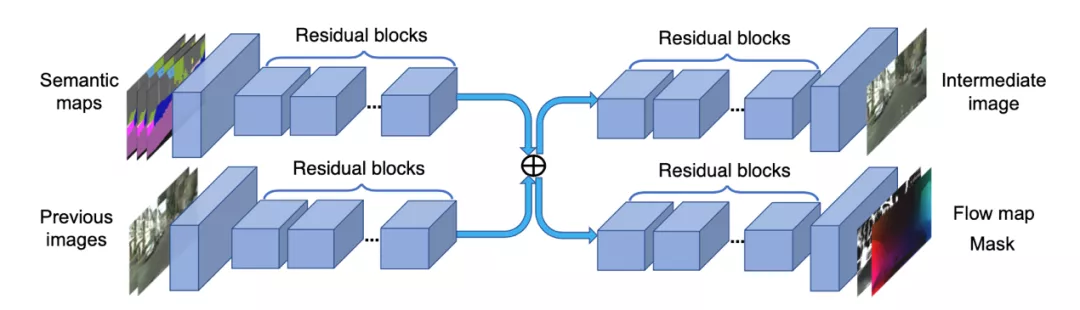
在深度学习技术的加持下,每一张平面图像都能转换为效果惊艳的3D图像?我突然有一个大胆的想法……



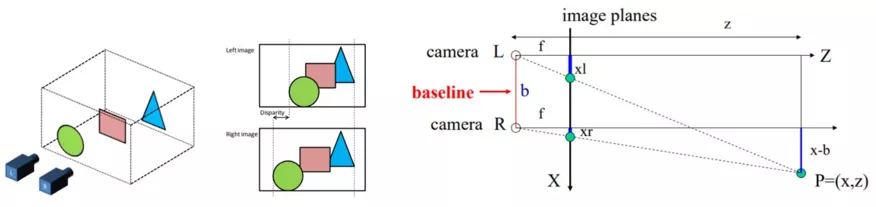
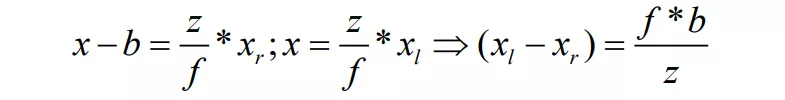
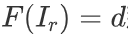
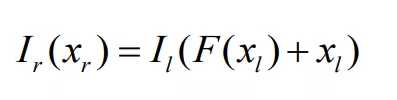
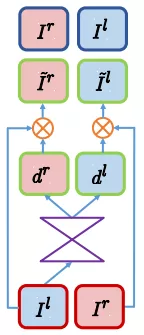
Junyuan Xie 等人提出的 Deep3D 虽然通过视差概率估计实现 2D 到 3D 介质的转换,但固定视差的设定,难以适应不同分辨率 2D 介质输入;
Ravi Garg 等人 2016 年提出的方法没有充分利用双目信息作指导,景深不够细;
Clement Godard 等人提出的 monodepth 在 Ravi Garg 等人的方法基础上,充分利用了双目信息进行对抗指导,学习到更多深度细节;
Tinghui Zhou 等人提出的 SfmLearner 方法引入帧间时序信息,结构较复杂,运行速度慢。




登录查看更多
相关内容

Arxiv
4+阅读 · 2018年1月23日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月23日