【牛津大学BoYang博士论文】学习重建和分割三维物体,143页pdf

赋予机器以感知三维世界的能力,就像我们人类一样,是人工智能领域一个基本且长期存在的主题。给定不同类型的视觉输入,如二维/三维传感器获取的图像或点云,一个重要的目标是理解三维环境的几何结构和语义。传统的方法通常利用手工特征来估计物体或场景的形状和语义。然而,他们很难推广到新的对象和场景,并努力克服关键问题造成的视觉遮挡。相比之下,我们的目标是理解场景和其中的对象,通过学习一般和鲁棒的表示使用深度神经网络,训练在大规模的真实世界3D数据。为了实现这些目标,本文从单视图或多视图的物体级三维形状估计到场景级语义理解三个方面做出了核心贡献。
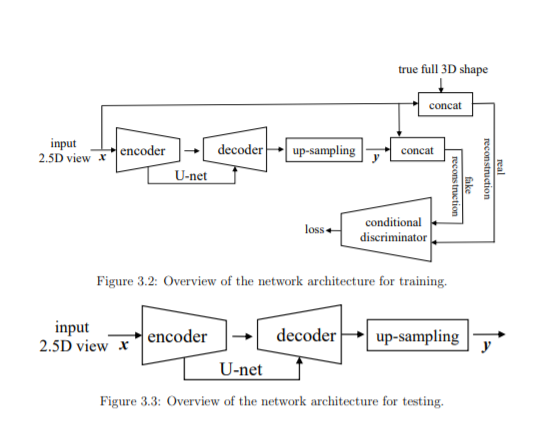
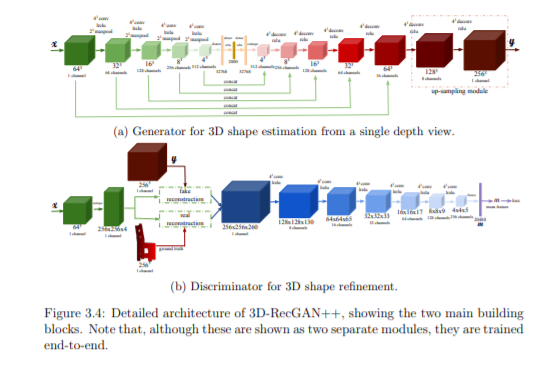
在第3章中,我们从一张图像开始估计一个物体的完整三维形状。利用几何细节恢复密集的三维图形,提出一种强大的编码器解码器结构,并结合对抗式学习,从大型三维对象库中学习可行的几何先验。在第4章中,我们建立了一个更通用的框架来从任意数量的图像中精确地估计物体的三维形状。通过引入一种新的基于注意力的聚合模块和两阶段的训练算法,我们的框架能够集成可变数量的输入视图,预测稳健且一致的物体三维形状。在第5章中,我们将我们的研究扩展到三维场景,这通常是一个复杂的个体对象的集合。现实世界的3D场景,例如点云,通常是杂乱的,无结构的,闭塞的和不完整的。在借鉴以往基于点的网络工作的基础上,我们引入了一种全新的端到端管道来同时识别、检测和分割三维点云中的所有对象。
总的来说,本文开发了一系列新颖的数据驱动算法,让机器感知我们真实的3D环境,可以说是在推动人工智能和机器理解的边界。
https://ora.ox.ac.uk/objects/uuid:5f9cd30d-0ee7-412d-ba49-44f5fd76bf28



专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RS3D” 可以获取《【牛津大学BoYang博士论文】学习重建和分割三维物体,143页pdf》专知下载链接索引





