魔镜炼成记:Google位姿估计应用Move Mirror架构与实现
Google刚刚发布了一个有趣的AI应用,Move Mirror。Move Mirror使用摄像头捕捉你的动作,并实时地在8万张图像中匹配和你的动作相近的图像。
在发布Move Mirror的同时,Google Creative Lab的Jane Friedhoff和Irene Alvarado发表长文,分享了打造Move Mirror的经验。
PoseNet
几个月前,Google Creative Lab有了制作Move Mirror的想法。显然,这个应用的核心是位姿估计(pose estimation)模型。
Google自家就在CVPR 2017上提交了PoseNet的论文。PoseNet可以检测多人的2D位姿,并在COCO数据集的关键任务上达到了当前最优表现。

表现出色,又是自家出品,所以Move Mirror团队顺理成章地选择了PoseNet作为应用背后的模型。在原型开发阶段,团队通过简单的web API访问PoseNet模型,这极大地简化了原型开发流程。只需向内部的PoseNet API接口发送一个HTTP POST请求,提交base64编码的图像,API就会传回位姿数据(基本无延迟)。若干行JavaScript代码,一份API密钥,搞定!
不过,考虑到不是所有人乐意把自己的图像发送到一个中央服务器,顺便也为了减少对后端服务器的依赖,团队决定把PoseNet移植到TensorFlow.js上。TensorFlow.js让用户可以在他们自己的浏览器中运行机器学习模型——无需服务器。
在Google Brain的TensorFlow.js团队成员Nikhil Thorat、Daniel Smilkov,以及Google研究员George Papandreou、Tyler Zhu、Dan Oved(Papandreou和Zhu是PoseNet的作者)的帮助下,移植工作顺利完成了。
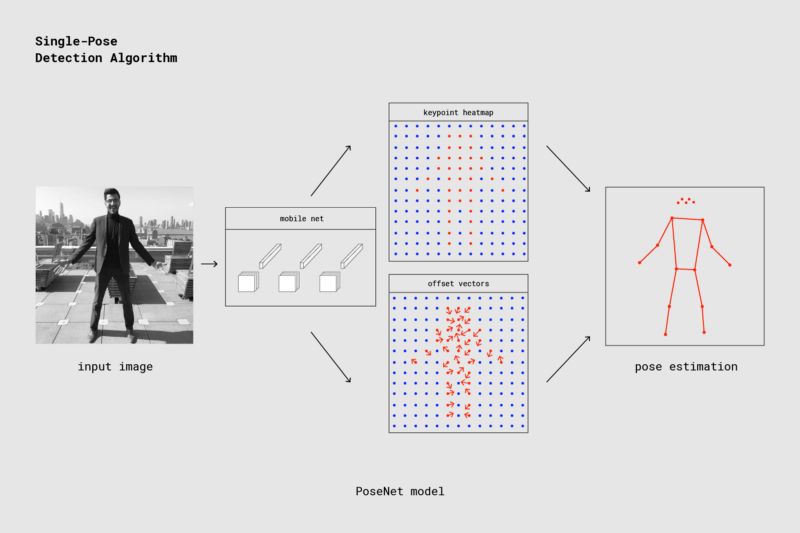
PoseNet单人位姿检测过程
我们将根据上面的示意图简单介绍PoseNet的位姿检测算法。我们看到,图中标明了网络架构是MobileNet。实际上,在PoseNet的论文中,研究人员同时训练了ResNet和MobileNet网络。尽管基于ResNet的模型精确度更高,但对实时应用来说,较大的尺寸和较多的网络层会是页面加载时间和推理时间不够理想。因此,TensorFlow.js上的PoseNet使用了MobileNet模型。
网络输出关键点热图和偏移向量。关键点热图用于估计关键点的位置,而偏移向量则用来在热图的基础上进一步预测关键点的精确位置。
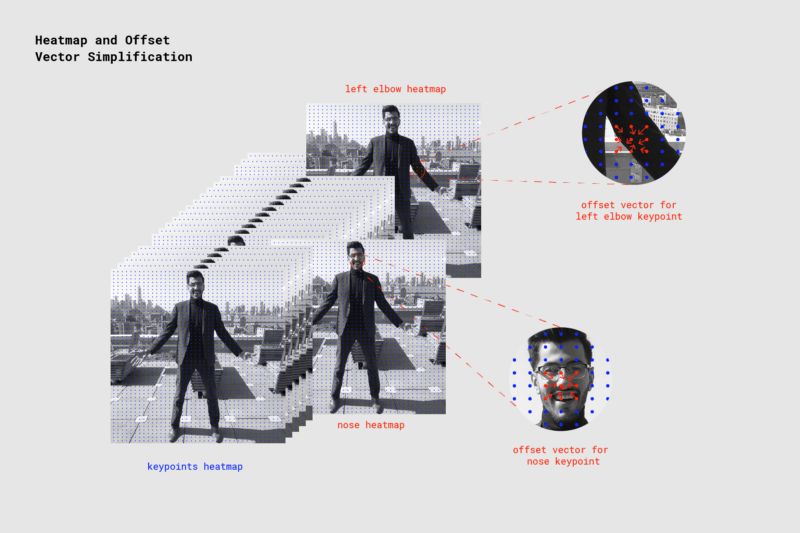
限于篇幅,我们这里不介绍多人位姿估计算法的细节。和单人位姿估计算法相比,多人位姿估计算法的主要差别在于使用了贪婪方法分组关键点,具体而言,使用了Google在2018年发表的PersonLab论文中的高速贪婪解码算法。
构建数据集
巧妇难为无米之炊。虽然PoseNet已经解决了位姿估计问题,但为了根据用户的位姿查找匹配的图像,首先要有图像。图像要符合以下两个要求:
多样性 为了更好地匹配用户做出的各种各样的动作,图像的位姿需要尽可能多样化。
全身像 从用户体验的一致性出发,决定只使用全身像。
最终,团队选择了包含多种动作,不同体型、肤色、文化的一组视频,将其切分为8万张静止图像。使用PoseNet处理这些图像,并储存相应的位姿数据。
你可能注意到,不是所有的图像都能正确解析位姿,所以丢弃了一些图像
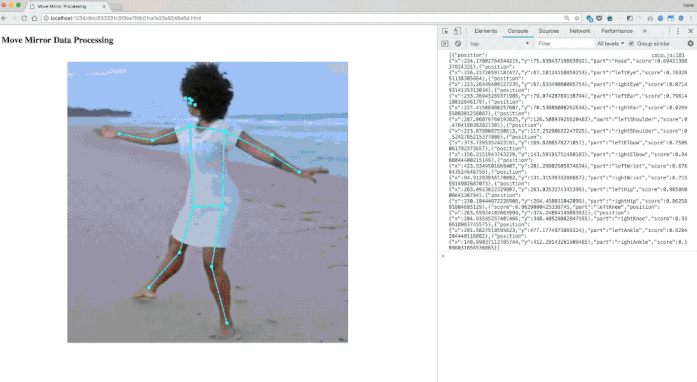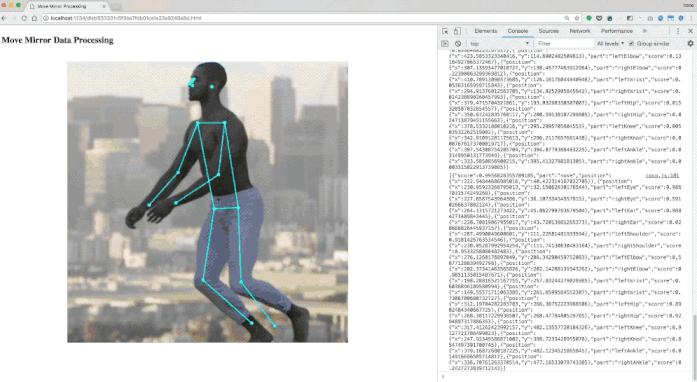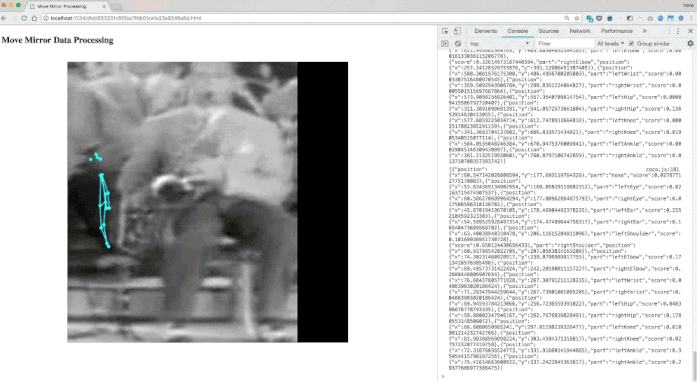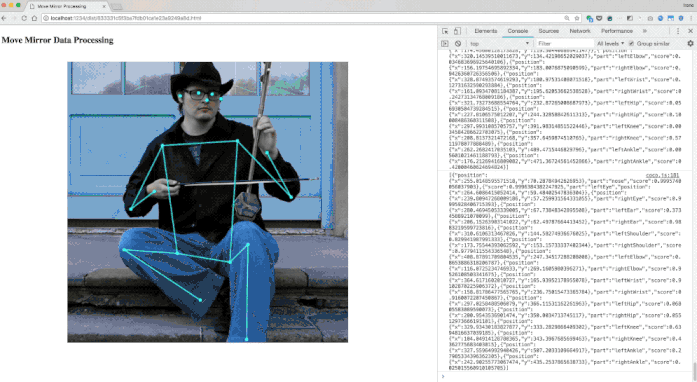
位姿匹配
PoseNet的位姿数据包括17个关键点的坐标,以及相应的置信度。
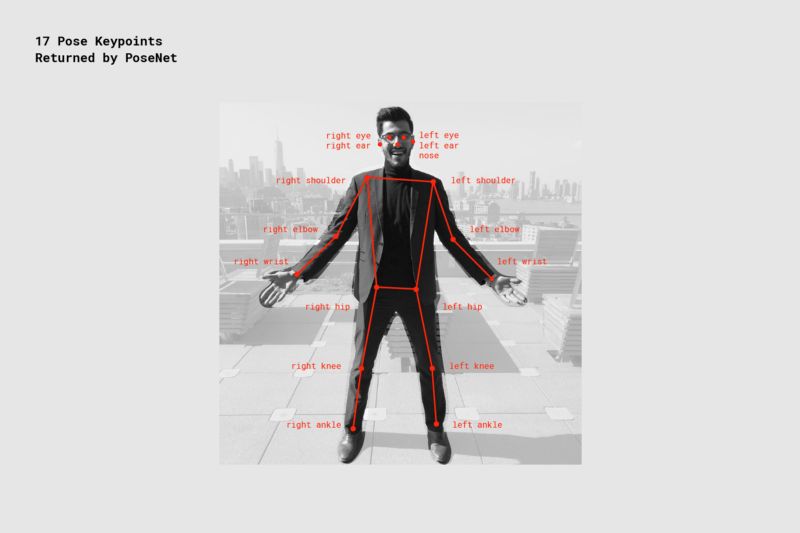
为了匹配关键点的相似度,很自然的一个想法是将17个关键点转换为向量,那么位姿匹配问题就转换为了高维空间中的向量相似性问题。这一问题有现成的余弦距离方案可用。

将JSON格式的关键点数据转换为向量
余弦相似度
如果你不熟悉余弦相似度,这里我们简单温习下这一概念。余弦相似度测量两个向量的相似程度:基本上,它测量两个向量之间的夹角,如果两个向量方向正好相反,则返回-1,如果两个向量方向一致,则返回1。重要的是,它只测量向量的方向,而不考虑长度。

图片来源:Christian Perone
尽管我们谈论的是向量和角度,余弦相似度并不限于直线和图。例如,余弦相似度可以得到两个字符串的相似度数值。(如果你曾经使用过Word2Vec,你可能已经间接地使用过余弦相似度。)事实上,余弦相似度是一个极其有效的将高维向量的关系约减至单个数字的方法。
温习了余弦相似度的概念之后,让我们回到之前的话题。理论上,直接将关键点数据转为向量后,就可以比较其余弦相似度了。实际上,还需要处理一些细节,这是因为数据集中的图像尺寸大小不同,不同的人也可能出现在图像的不同局部。
具体而言,进行了如下两项额外处理,以便保持比较的一致性:
缩放 根据每个人的包围盒裁剪图片,然后缩放至固定大小。
标准化 L2正则化向量(使分量的平方和等于1)。
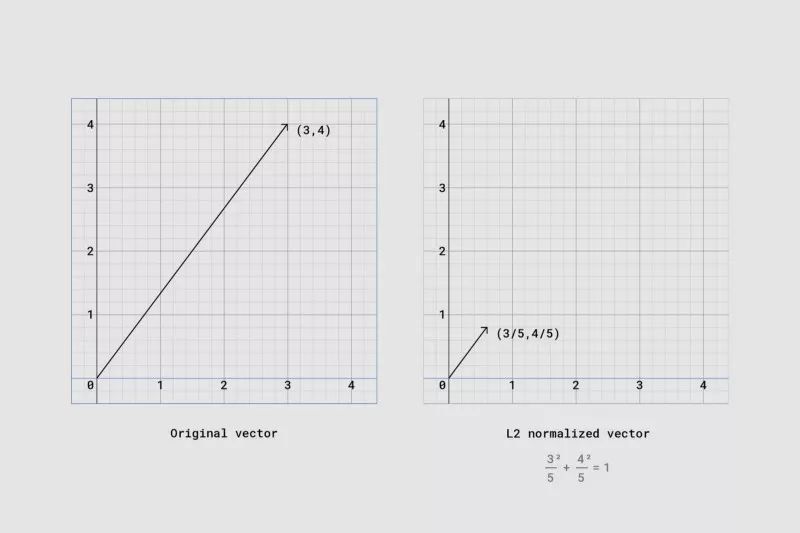
L2正则化向量
可视化以上两个处理步骤:
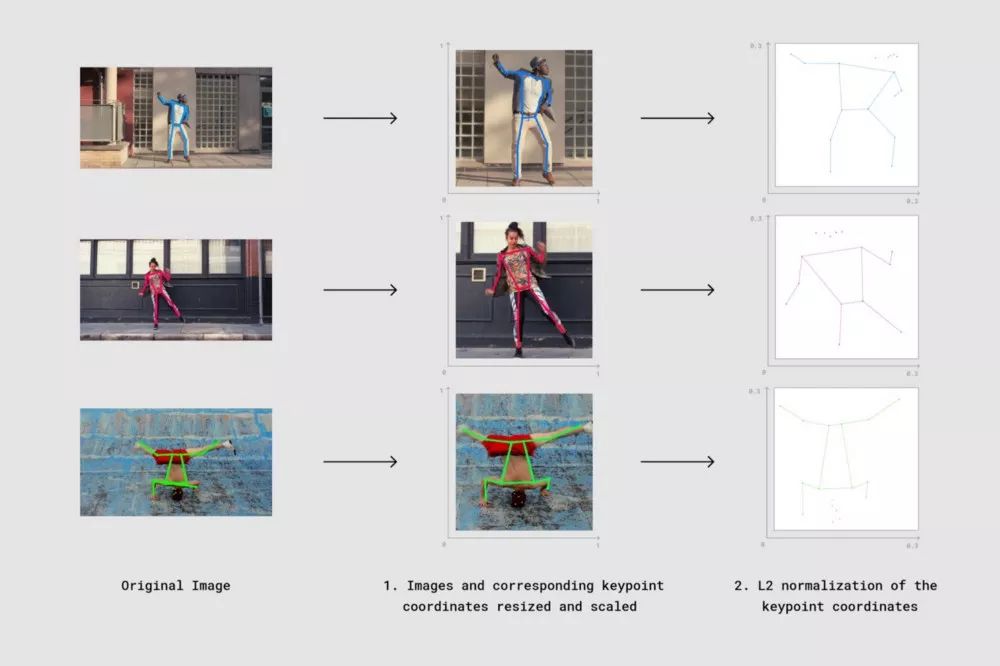
最终,根据下式计算向量间的距离:
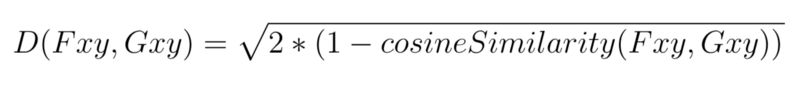
加权匹配
上面的匹配算法好像缺了点什么?还记得我们之前提到的吗?
PoseNet的位姿数据包括17个关键点的坐标,以及相应的置信度。

左肘在画面中清晰可见,置信度较高;右肩在画面中不可见,置信度较低
上面的匹配算法根本没有考虑置信度呀。显然,置信度是很重要的信息。为了得到更准确的结果,我们应该给置信度高的关键点较高的权重,给置信度低的关键点较低的权重。换句话说,增强置信度高的关键点对相似度的影响,削弱置信度低的关键点对相似度的影响。
Google研究员George Papandreou和Tyler Zhu给出了将置信度纳入考量后的距离公式:
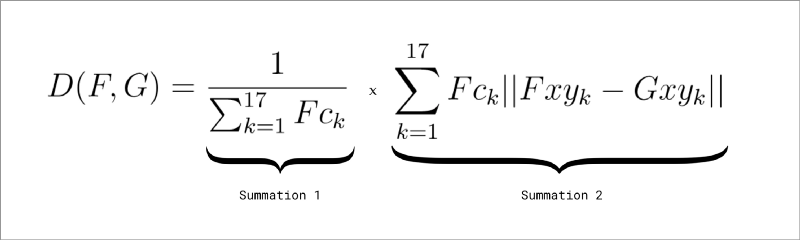
上式中,Ck为第k个关键点的置信度,xyk为第k个关键点的x、y坐标(经过缩放、标准化等处理)。
加权匹配提供更精确的结果。即使身体的部分被遮挡或位于画面之外,仍然能够匹配。

优化匹配速度
还记得吗?总共有8万张图像!如果采用暴力搜索法,每次匹配需要计算8万次距离。这对于实时应用来说不可接受。
为了优化匹配速度,需要将8万个位姿数据以某种有序的数据结构存储,这样,匹配的时候就可以跳过那些明显距离很远的位姿数据,从而大大加速匹配进程。
Move Mirror选用的数据结构是制高点树(vantage-point tree,简称VP树)。
制高点树
简单温习下制高点树这一数据结构。

图片来源:Data Structures for Spatial Data Mining
我们在数据点中选取一点(可以随机选取)作为根节点(上图中为5)。我们绕着5画一个圈,将空间分割成圈内和圈外两部分。接着我们在圈内、圈外各选一点作为制高点(上图中为7和1)。接着,绕着每个制高点各画一个圈,同样在圈内、圈外各选一点……以此类推。这里的关键在于,如果我们从点5开始,然后发现7比1更接近目标,那么我们就可以跳过1的所有子节点。
关于制高点树的更多细节,可以参阅fribbels.github.io/vptree/writeup 使用了制高点树(javascript库vptree.js)之后,匹配得以在大约15ms内完成,对实时应用而言,这一数字很理想。
Move Mirror仅仅返回最匹配用户位姿的图像。不过,通过遍历制高点树,不难返回更多结果,比如最接近的10张或20张图像。这可以用来制作调试工具,发现数据集的问题。

Move Mirror调试工具
结语
Move Mirror团队期待能看到更多类似的有趣应用,比如匹配舞蹈动作,匹配经典电影片段。或者反向操作,基于位姿估计帮助人们在家中练习瑜伽或者进行理疗。
如果你想亲自尝试Move Mirror效果:g.co/movemirror
如果你也想基于TensorFlow.js上的PoseNet制作应用:tensorflow/tfjs-models/posenet




