裴健:搜索皆智能,智能皆搜索

编辑 | 丛 末


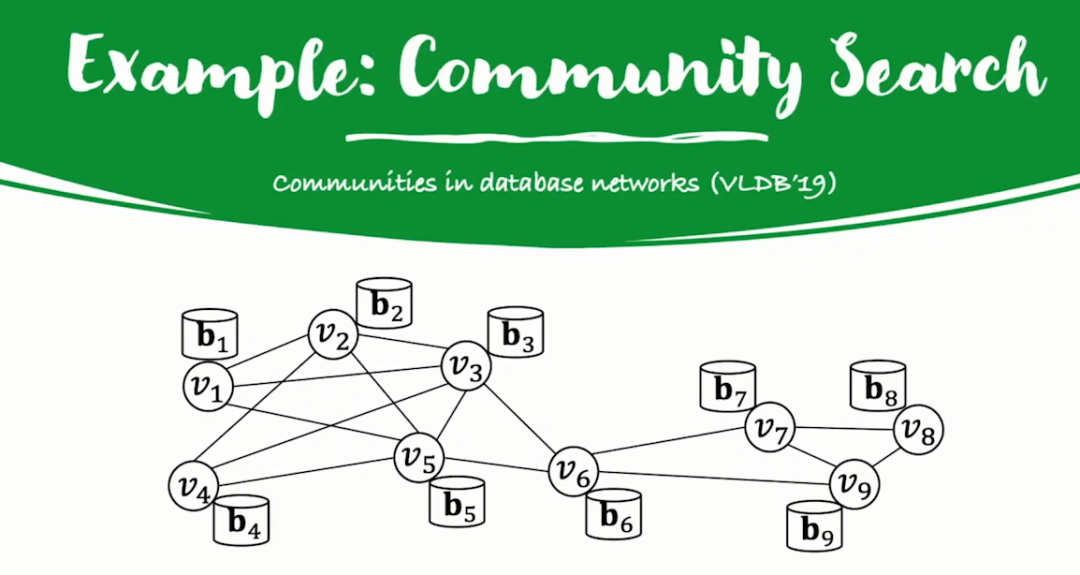
搜索皆智能


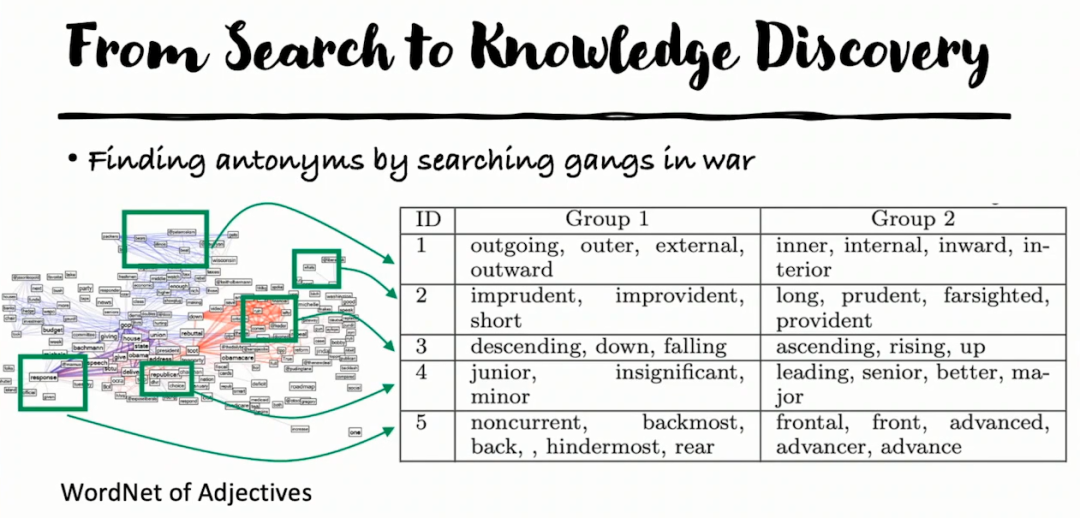
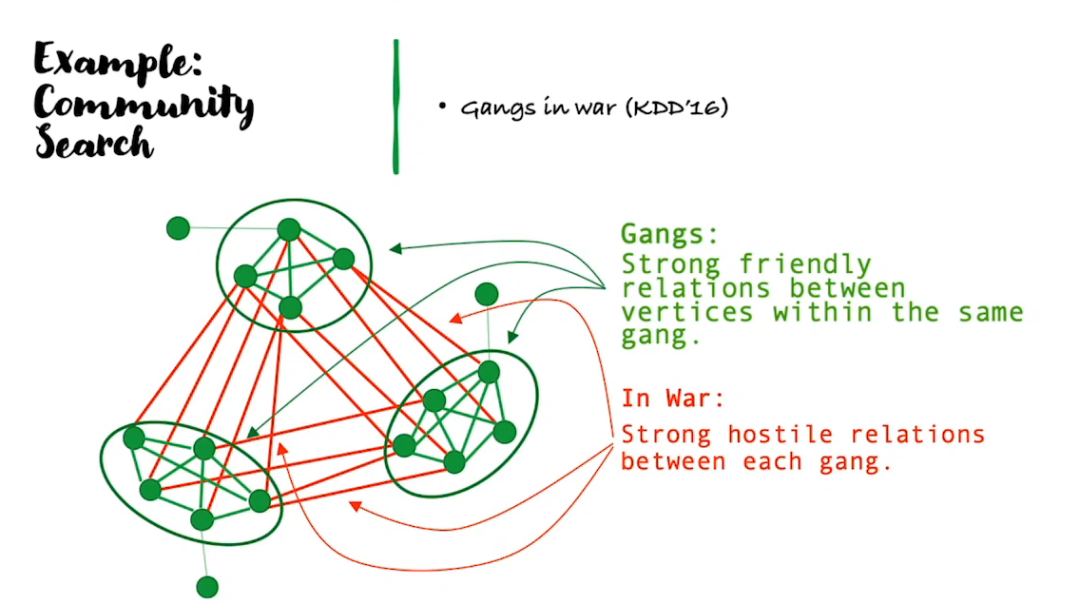
智能皆搜索





智能搜索,与人相关
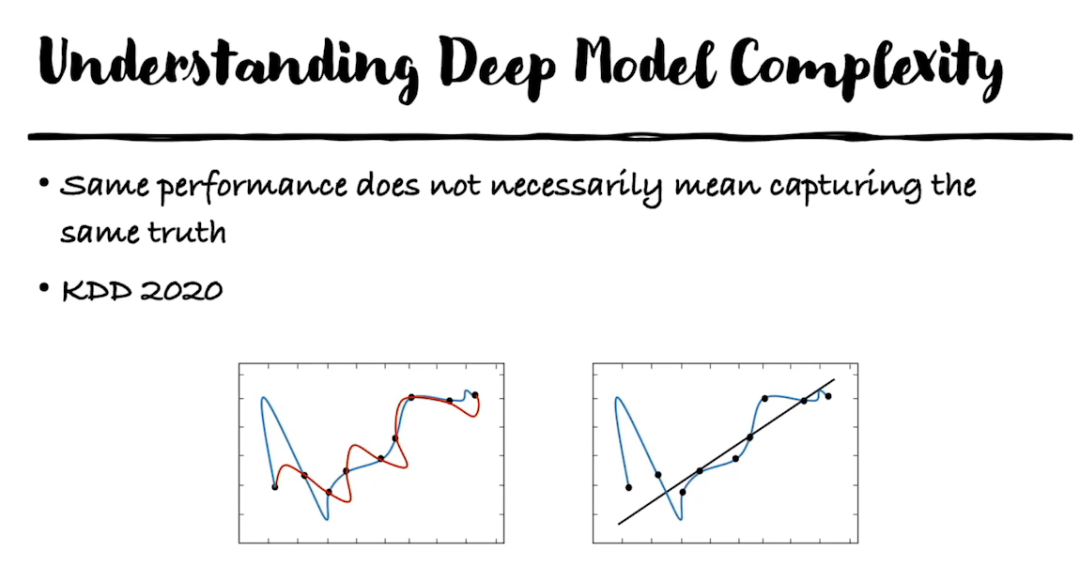

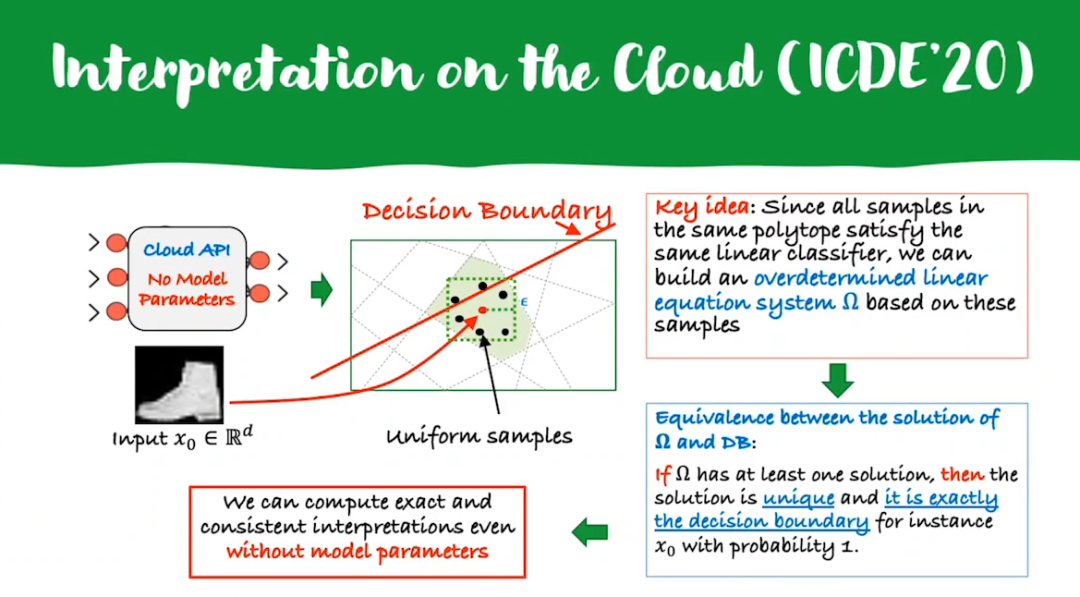





登录查看更多
相关内容

Arxiv
7+阅读 · 2018年10月31日




相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2018年10月31日