动态 | 搜狗携手自动化所提出新的开放领域问答机器阅读算法

AI 科技评论按:近年来,随着机器阅读理解技术的发展,越来越多的开放域问答方法采用了机器阅读理解技术生成答案。然而,传统基于机器阅读理解的开放域问答技术存在数据噪声大、答案概率偏置等问题,使得最后产生的答案效果欠佳。
搜狗公司 & 中科院自动化所在信息检索领域顶级会议 SIGIR 2019 (CCF A 类会议)中联合提出了一个基于文档门控机制的阅读算法,并将其用在开放域问答中,在很多开放域问答应用中取得了最好的效果。搜狗公司为这篇论文《Document Gated Reader for Open-Domain Question Answering》撰写了中文解读文章如下。
基于机器阅读理解的开放域问答
开放域问答(open-domain question answering)技术旨在给定任意类型的问题后,从任意资源中取得答案。传统的开放域问答大多采用 pipeline 的方式,即先通过检索系统找到跟问题相关的文档,再通过问答技术从文档中产生答案。最近几年,随着机器阅读理解技术的发展,越来越多开放域问答的方法引入机器阅读理解技术来抽取答案。例如,在 ACL2017 上斯坦福大学提出了一种神经开放域问答框架,如下图:
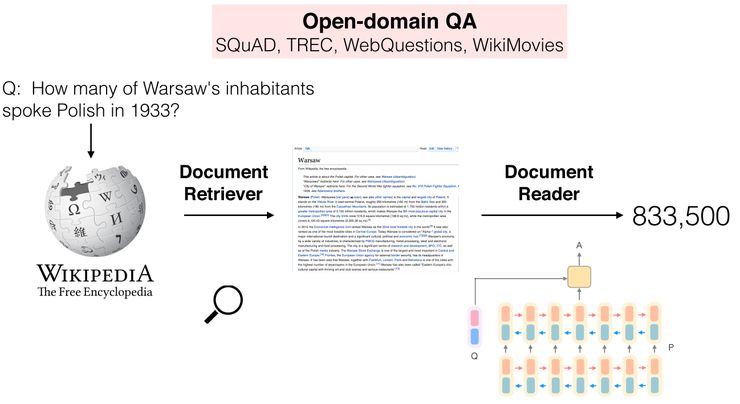
图一:基于机器阅读理解技术的开放域问答框架
以往的基于机器阅读理解的技术往往存在两个问题:首先,以往的方法大多是弱监督地根据问题找到的相关文档,然后将包含有正确答案的文档当做真正的文档来训练,而通过这种弱监督获取到的数据往往包含有错误的文档(false positive),例如下面这个例子:

图二:弱监督获取文档中包含的噪声
其中文档一包含了正确答案(Lebron James),但是却和问题不相关。文档二虽然包含了多个正确答案的,但是其中很多都不能用来回答问题。
其次,很多以前的方法都没有考虑到答案概率的归一化:每一篇文档单独抽出来一个答案,以及这个答案的概率,最后各个文章的中的答案直接比较概率得到最终的答案,然而,这种过程会存在严重的答案概率偏置问题,如下面这个例子:

图三:文档答案概率偏置问题
这两篇文章中,虽然文档 1 是真正可以回答问题的。而且,文档选择模型给出的文档 1 的概率也大于文档 2 的概率(0.7>0.3)。但是,由于文档 1 相对较长,所以其中的最佳答案概率在经过文档归一化之后变得相对较低,而由于文档 2 比较短,并且其中的候选答案很少,所以答案 2 的概率在归一化后相对较高。这样,在经过了文档检索和阅读理解两个步骤之后,答案 2 的概率会大于答案 1 的概率。这种现象称为答案概率的偏置。
基于文档门控机制的阅读器
首先,针对答案概率偏置问题,本文设计了一种专门针对开放域问答对文档门控机制的阅读器。这个模型建立在传统机器阅读理解模型上,引入了文档控制器来控制最终答案的输出,整体模型如下图:
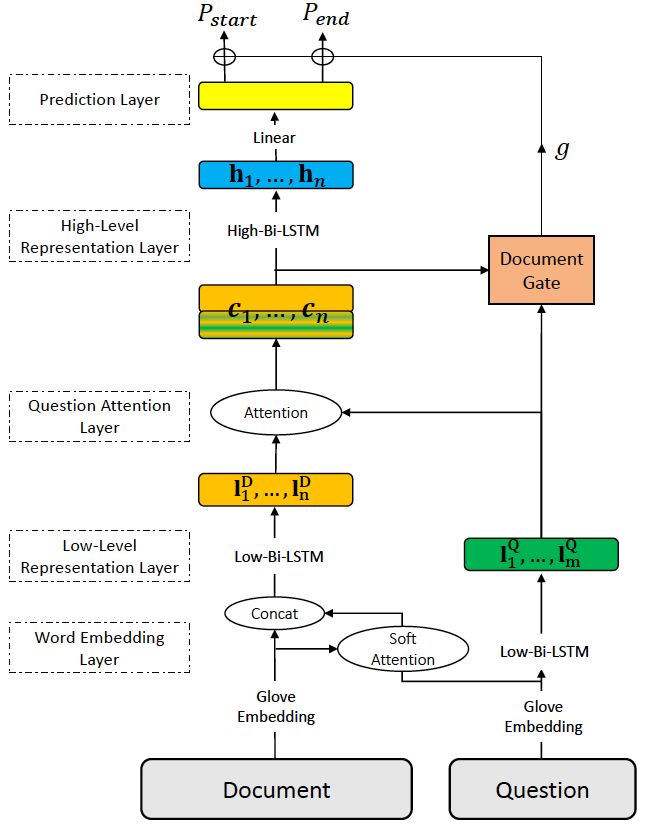
图四:基于文档门控机制的阅读器
其中,文档和问题的建模过程和传统的机器阅读理解模型类似,是基于注意力机制的双向 LSTM。包含有词表示层,低级表示层,问题关注层,高级表示层以及答案输出层。
和以往的模型不同,在表示的过程中, 我们加入了一个文档控制门(Document Gate),用以将文档选择信息引入到最终的结果中去。这个文档控制门会输出一个 0-1 的分数,用以影响最后生成的答案的概率。
其中的文档控制器作用在问题的低级表示和文档的高级表示之上,如下图:
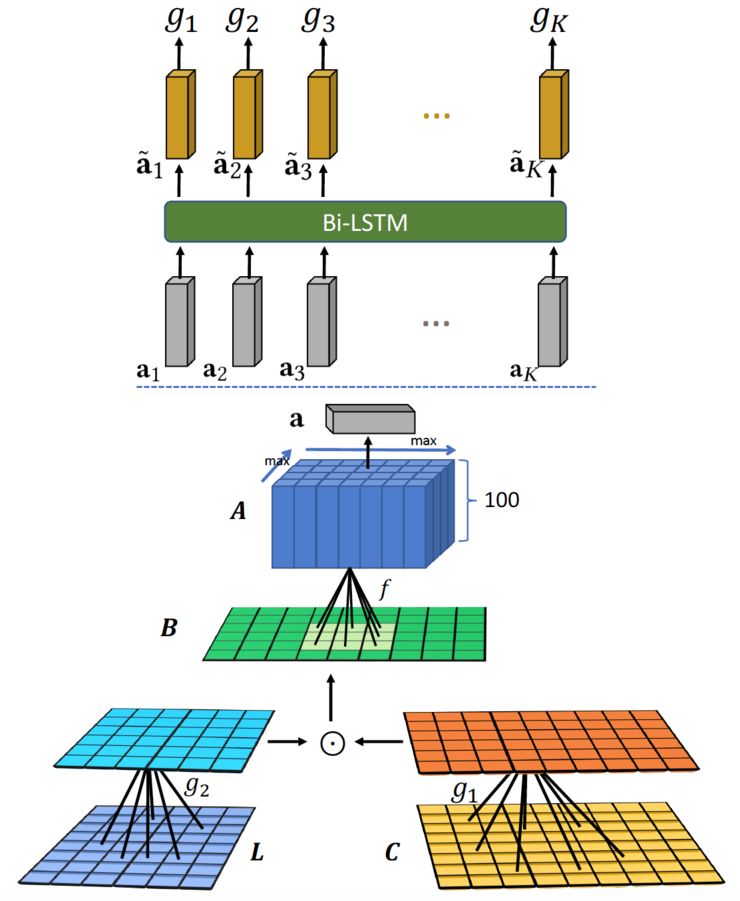
图五:文档控制器
其中K为候选文档的个数。可以看到,通过最上层的双向LSTM,各个文档之间的信息也联系了起来。最后的文档分数g是包含有上下文文档的得分,因而表示相关性能力更强。
最后,在训练的时候,为了避免答案概率的偏置问题,本文采用了一种全局归一化的目标函数:
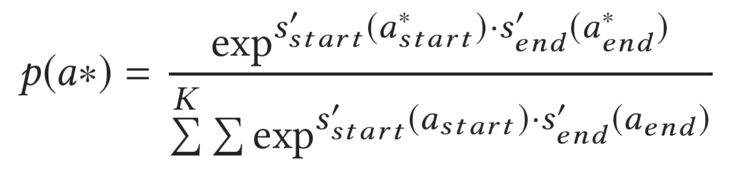
可以看到正确答案的得分和所有答案的得分进行了比较,所以这种优化目标会使最终正确答案的分数是全局最高的。
基于自举法的弱监督数据生成
为了解决传统弱监督数据中存在的噪声较大的问题,我们使用了一种基于自举法(bootstrapping)的数据生成方法。具体来说,我们首先根据一些置信度较高的数据当成种子数据,例如,在 SQuAD 中种子数据可以是提供的最佳答案,在一些其他类型数据中可以是经过检索模型打分最高的。然后,在这个种子模型中我们预训练我们的模型,然后依靠上述的文档控制器的得分可以从未标注的弱监督数据中选择出分数较高的文档,加入到训练集里面继续训练。整个过程如下:
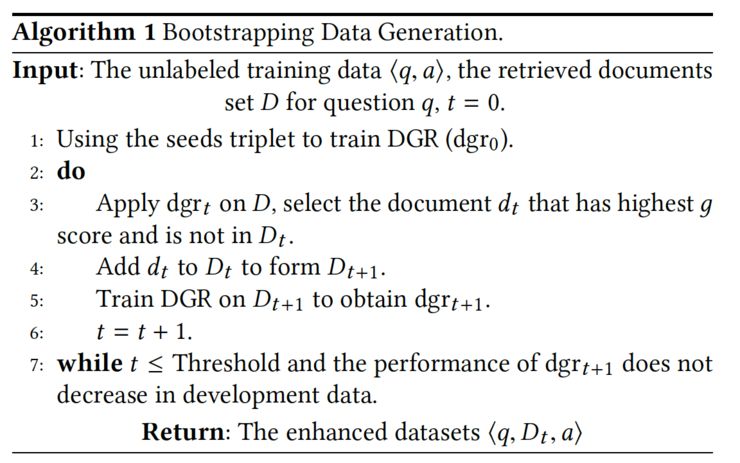
实验
本文采用了四个被经常使用的数据用以评估所提出的模型,分别是 SQuAD, SearchQA, WebQuestions, WikiMovies。关于这几个数据集的一些信息如下表:
本文提出的模型和以往的一些模型的效果对比如下图:
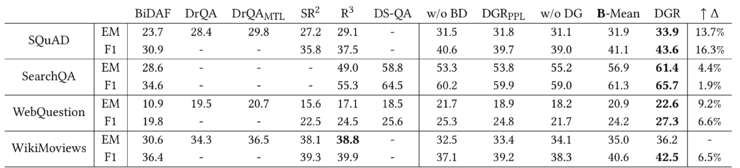
可以看出来,本文提出的模型的在所有数据上都取得了较以往模型显著的提升。
为了评估引入的文档控制门对文档选择的作用,我们在 SQuAD 数据上来评估我们模型的效果。通过两个指标可以判断出文档选择的效果:P@N:即通过文档选择的前 N 个文档中是否包含最佳文档。AR:在返回的文档中最佳文档的平均位置。各种模型的文档选择结果如下图:
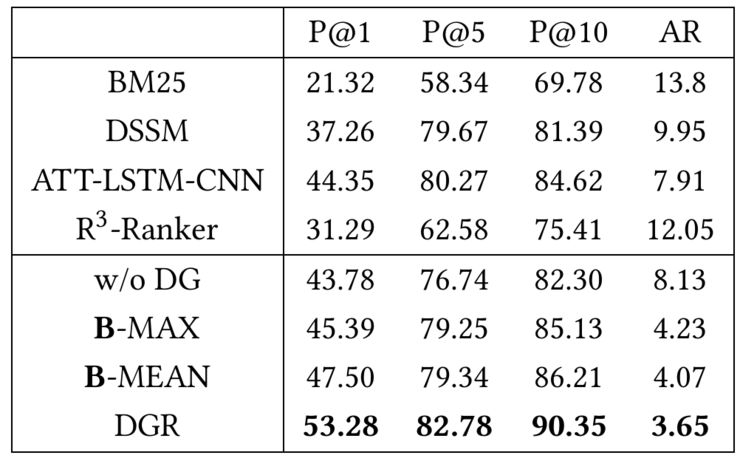
可以看到,对于文档选择来说,我们提出的文档控制器能够有效地选择出正确文档,选择的效果大大优于以往的方法。
本文的一个贡献是在训练目标中使用了全局归一化因子,因此,我们对这个全局归一化因子进行衡量,我们评估不同的模型在加入不同数目的噪声后的表现,其结果如下图:
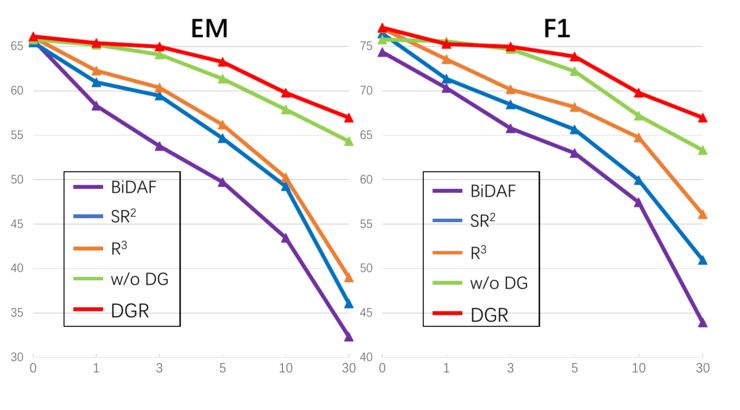
可以看到,不同的模型在加入噪声文档之后,没有用全局归一化的模型效果显著地降低,这个现象也被很多以前的多文档问答工作所证实。而由于我们使用了全局归一化进行训练,因此模型受噪声影响较小。
最后,为了评估本文所提出的自举法的数据效果,我们评估在自举法不断进行的过程中模型的表现,其结果如下图:
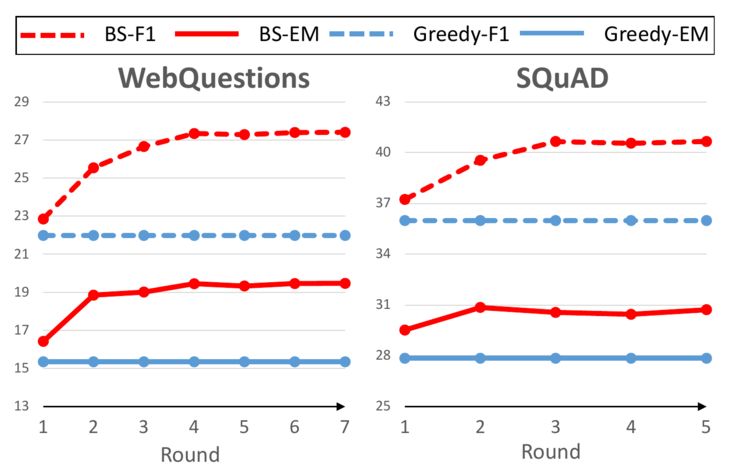
可以看到,在新数据不断加入之后,模型的效果不断提升,这也从另一方面说明了当模型效果很好的时候,基于模型选择出的数据包含有更丰富的模式,使在其上训练的模型表现更好。
总结
本文提出了一种基于文档门控选择的开放域问答模型。针对以往方法中存在的答案偏置问题本文提出了一种文档门控选择器用以确定文档分数,并且使用全局归一化目标进行优化。针对传统方法中存在弱监督数据噪声过多的问题,我们使用了一种基于自举法的数据增强方法用以改进扩展训练数据,在实验中我们发现本文提出的方法能够有效地选择出相应文档,并且对噪声文档的地抗能力更强,在很多开放域问答数据中本文提出的方法都取得了最好的效果。

点击阅读原文,查看 NLP 顶会讨论小组,讨论更多前沿学术成果


