我为什么认为Julia是数据科学的未来?

Julia 是一种高级的通用语言,可以用来编写执行速度快、易于实现科学计算的代码。该语言旨在满足科学研究人员和数据科学家的所有需求,以优化实验和设计的实施。
“Julia 是为科学计算、机器学习、数据挖掘、大规模线性代数、分布式和并行计算而建立的"——Julia 语言的开发者。
Python 在数据科学爱好者中仍然很有名,因为它具有可加载库所构成的生态系统,适合于完成数据科学方面的工作。但是 Python 不够快,也不够方便,而且它的大多数类库都是用 JavaScript、Java、C 和 C++ 等其他语言构建的,这导致了它在安全方面的差异性。
Julia 的快速执行和便捷开发使它在数据科学界中颇具吸引力,而且大多数库都是直接用 Julia 编写的,以提供额外的安全层。
数据科学家的在线社区Kaggle总裁兼首席科学家Jeremy Howard曾在访谈中谈到,当涉及运行机器学习模型时,Python 令人沮丧,因为你必须使用其他语言的类库,如 CUDA,如运行并行计算时,这使得 Python 极具挑战。Jeremy 还建议,如果你想成为面向未来的人,那么就开始学习 Julia,因为它将在几年内取代 Python。
与 Python 相比,Julia 在多个领域都处于领先地位,如下所述。
Julia 的速度快
Python 的速度可以通过使用外部库和工具进行优化,但是因为带有 JIT 编译和类型声明,Julia 其默认的速度更快。
对数学友好的语法
Julia 为数学操作提供了简单的语法,这些语法与 non-computing 世界相似,从而吸引了非程序员科学家。
自动内存管理
在内存分配方面,Julia 比 Python 更好,它提供了更大的自由以支持手动控制垃圾收集。而在 Python 中,你要不断地释放内存并收集关于内存使用的信息,在某些情况下,这让人气馁。
卓越的并行性
在运行科学算法时,有必要使用所有可用的资源,如运行在多核处理器的并行计算。对于 Python,你需要使用外部包进行并行计算,或者在线程之间进行序列化和反序列化操作,这种方式,用起来难度很大。而对于 Julia 来说,在实现上要简单得多,因为它本身就带有并行性。
原生机器学习库
Flux 是 Julia 的一个机器学习库,还有其它正在开发的、完全用 Julia 编写的深度学习框架,用户可以根据需要进行修改。这些库都带有 GPU 加速功能,所以你不需要担心深度学习模型训练会很慢。
在这篇文章中,我将讨论 Julia 语言的优势,展示如何轻松使用 DataFrame.jl,就像在 python 中使用 pandas 一样。我将使用简单的例子和几行代码来演示数据操作和数据可视化。我们将使用著名的 心脏病 UCI | Kaggle 数据集,它是一个基于多种因素的心脏病二分类数据集。
探索心脏疾病数据集
首先我们来设置你的 Julia repl,可以使用 JuliaPro,或者设置你的 VS Code 支持 Julia,如果你像我一样正在使用云端笔记本(cloud notebook),我建议你将下面的代码添加到你的 docker 文件中并构建它。
下面的 Docker 代码只适用于 Deepnote 环境。
FROM gcr.io/deepnote-200602/templates/deepnote
RUN wget https://julialang-s3.julialang.org/bin/linux/x64/1.6/julia-1.6.2-linux-x86_64.tar.gz &&
tar -xvzf julia-1.6.2-linux-x86_64.tar.gz &&
sudo mv julia-1.6.2 /usr/lib/ &&
sudo ln -s /usr/lib/julia-1.6.2/bin/julia /usr/bin/julia &&
rm julia-1.6.2-linux-x86_64.tar.gz &&
julia -e "using Pkg;pkg"add IJulia LinearAlgebra SparseArrays Images MAT""
ENV DEFAULT_KERNEL_NAME "julia-1.6.2"
安装 Julia 软件包
下面的方法将帮助你一次性下载和安装所需要的多个类库。
import Pkg; Pkg.add(["CSV","CategoricalArrays",
"Chain", "DataFrames", "GLM", "Plots", "Random", "StatsPlots",
"Statistics","Interact", "Blink"])导入软件包
我们将更多地关注于加载数据操作和可视化。
using CSV
using CategoricalArrays
using Chain
using DataFrames
using GLM
using Plots
using Random
using StatsPlots
using Statistics
ENV["LINES"] = 20 # to limit nuber of rows.
ENV["COLUMNS"] = 20 # to limit number of columns加载数据
我们使用著名的 UCI | Kaggle 心脏疾病数据集进行初级的数据分析。
特征 / 列:
age
sex
chest pain type (4 values)
resting blood pressure
serum cholesterol in mg/dl
fasting blood sugar > 120 mg/dl
resting electrocardiographic results (values 0,1,2)
maximum heart rate achieved
exercise-induced angina
oldpeak
the slope of the peak exercise ST segment
number of major vessels
thal: 3 to 7 where 5 is normal.简单地使用 CSV.read(),就像 pandas pd.read_csv() 一样,你的数据将被加载为 data frame。
df_raw = CSV.read("/work/Data/Heart Disease Dataset.csv", DataFrame)
df_raw = CSV.read("/work/Data/Heart Disease Dataset.csv", DataFrame)
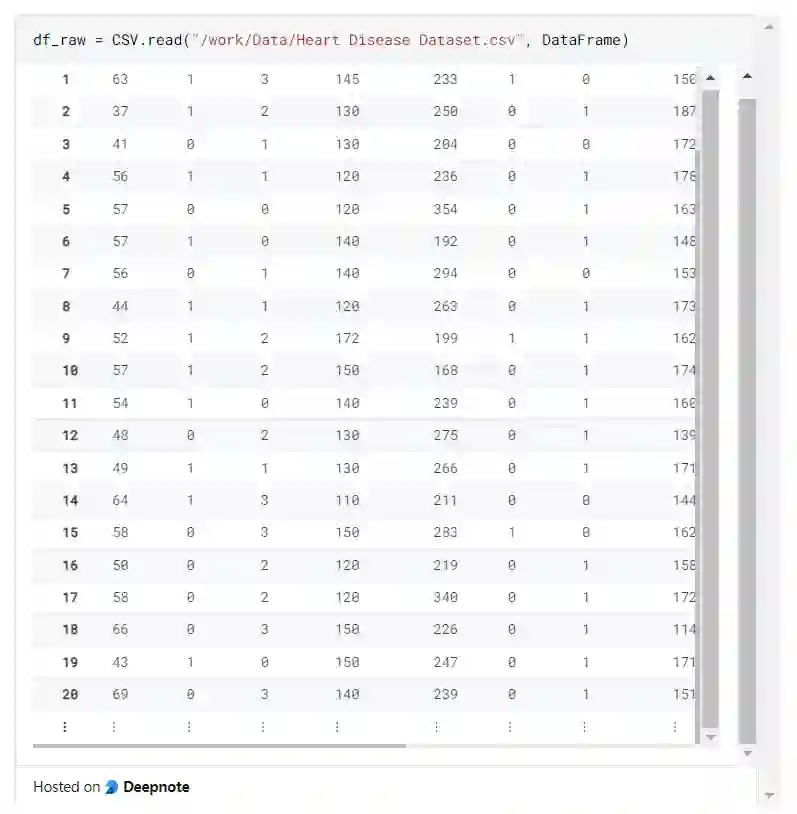
关于Python/R/Stata对比的更多信息,请访问:https://dataframes.juliadata.org/stable/man/comparisons/
size(df_raw)
(303, 14)
托管于 Deepnote检查多列分布:我们可以使用 describe() 来一次性观察平均值、最小值、最大值和缺失值。
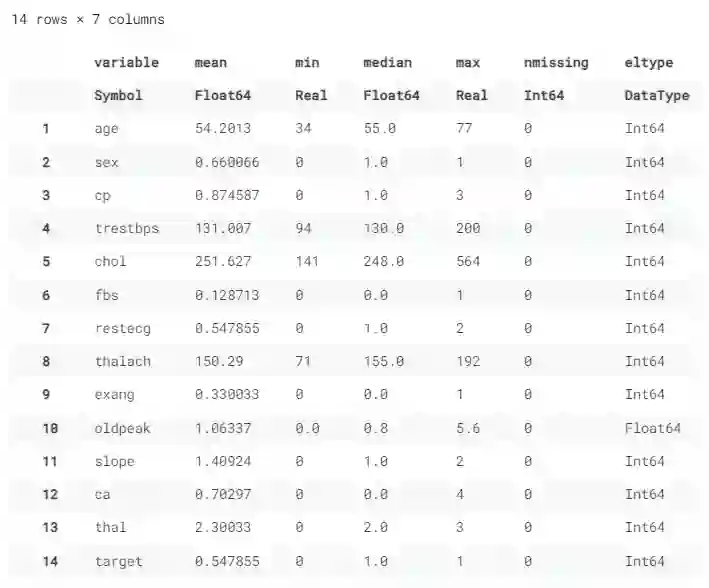
数据选择
通过使用:fbs => categorical => :fbs 将列转换为分类类型,我们使用 Between 一次选择多个列。select 函数很简单,用于选择列和操作类型。
df = select(df_raw,:age,:sex => categorical => :sex,
Between(:cp, :chol),
:fbs => categorical => :fbs,:restecg,:thalach,
:exang => categorical => :exang,
Between(:oldpeak,:thal),
:target => categorical => :target
)
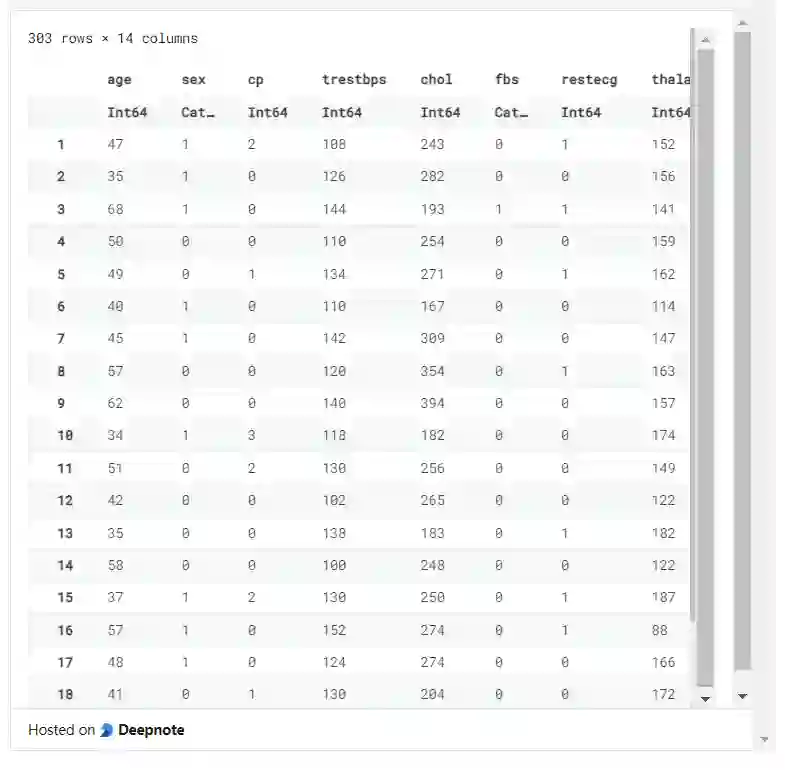
使用 Chian
如果你想在你的数据集上一次应用多个操作,我建议你使用 @chain 功能,它相当于 R 中的 %>%。
dropmissing 将从数据库中删除缺失值行。我们的数据集中没有任何缺失值,所以在此只是为了展示一下。
groupby 函数在给定的列上对数据框进行分组。
combine 函数通过聚合函数将 data frame 的行合并。
更多操作请访问:https://github.com/jkrumbiegel/Chain.jl。我们将 data frame 按目标分组,然后合并五列,以得到他们的平均值。
@chain df_raw begin
dropmissing
groupby(:target)
combine([:age, :sex, :chol, :restecg, :slope] .=> mean)
end
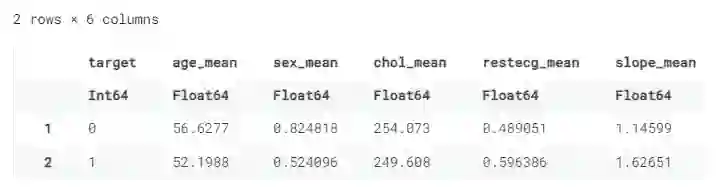
另一种使用 groupby 和组合的方法是使用 names(df, Real),它返回所有具有实型值的列。
@chain df_raw begin
groupby(:target)
combine(names(df, Real) .=> mean)
end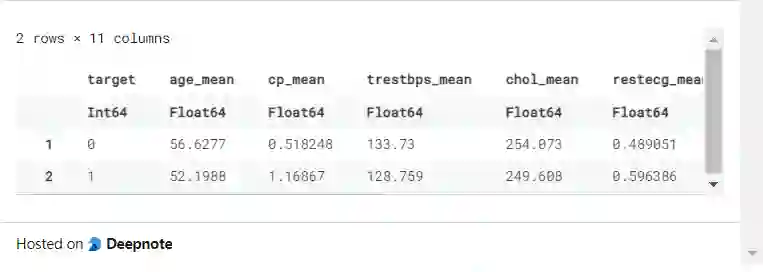
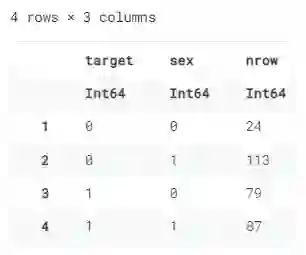
我们还可以使用 groupby 添加多列,并通过 nrows 组合,这将为每个 sub-group 显示若干行。
@chain df_raw begin
groupby([:target, :sex])
combine(nrow)
end
我们也可以把它结合(combine)起来,然后解开堆叠(unstack),如下图所示。这样,一个类别变成了一个索引,另一个就变成了一个列。
@chain df_raw begin
groupby([:target, :sex])
combine(nrow)
unstack(:target, :sex, :nrow)
end
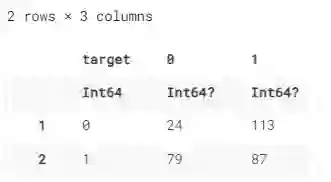
Groupby
简单的 groupby 功能会同时显示所有的组,如果要访问特定的组,你需要使用 Julia hacks。
gd = groupby(df_raw, :target)
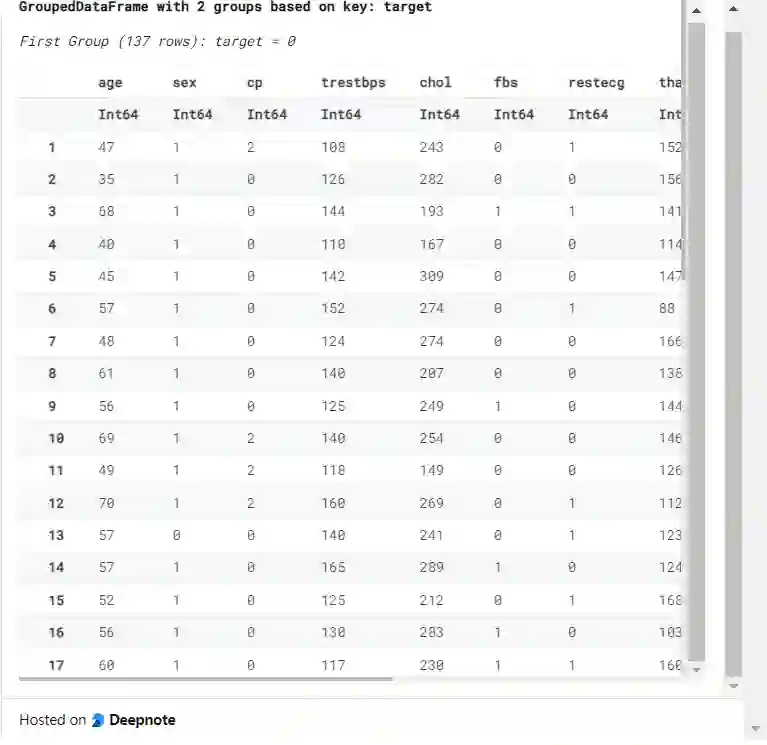
我们可以用如下命令来获得我们关注的特定组,这在我们处理多个类别时会有所帮助。
gd[(target=0,)] | gd[Dict(:target => 0)] | gd[(0,)]gd[1] 将显示 target =0 的第一组,如下所示:
gd[1]
密度图(Density Plot)
我们将使用 StatsPlots.jl 包来绘制图形和图表。这个包包含了扩展 Plots.jl 功能的统计 recipes。就像 seaborn 一样,通过简单的代码,我们可以画出对应的密度图,不同的组是对应不同的颜色。
我们将按 target 列分组,并显示 cholesterol ,下图显示了 cholesterol 的分布。
组直方图(Group Histogram)
与密度图类似,我们可以用 grouphist 为不同的 target 类别绘制直方图。
@df df_raw groupedhist(:chol, group = :target, bar_position = :dodge)
多视图(Multiple Plots)
你可以通过在功能的末尾使用!,实现在同一个图片中绘制多个视图,例如 boxplot!()。
下面示例显示了 cholesterol 的小提琴(violin plot)图、盒图(box plot)和点图(dot plot)的复合视图,它是用 target 分组的。
@df df_raw violin(string.(:target), :chol, linewidth=0,label = "voilin")
@df df_raw boxplot!(string.(:target), :chol, fillalpha=0.75, linewidth=2,label = "boxplot")
@df df_raw dotplot!(string.(:target), :chol, marker=(:black, stroke(0)),label = "dotplot")
预测模型
我们将像在 R 中用 y-x 训练模型那样使用 GLM 模型。
下面示例中 x= trestbps, age, chol, thalach, oldpeak, slope, ca,y= target 是二分布的。我们将在二项分布上训练我们的广义线性模型来预测心脏病。可以看到,我们的模型已经训练好了,但仍需要一些调整以获得更好的性能。
probit = glm(@formula(target ~ trestbps + age + chol + thalach + oldpeak + slope + ca),
df_raw, Binomial(), ProbitLink())
StatsModels.TableRegressionModel{GeneralizedLinearModel{GLM.GlmResp{Vector{Float64}, Binomial{Float64}, ProbitLink}, GLM.DensePredChol{Float64, LinearAlgebra.Cholesky{Float64, Matrix{Float64}}}}, Matrix{Float64}}
target ~ 1 + trestbps + age + chol + thalach + oldpeak + slope + ca
Coefficients:
───────────────────────────────────────────────────────────────────────────────
Coef. Std. Error z Pr(>|z|) Lower 95% Upper 95%
───────────────────────────────────────────────────────────────────────────────
(Intercept) -1.64186 1.18724 -1.38 0.1667 -3.9688 0.685081
trestbps -0.00613815 0.00584914 -1.05 0.2940 -0.0176022 0.00532595
age 0.00630188 0.0122988 0.51 0.6084 -0.0178034 0.0304071
chol -0.00082276 0.00176583 -0.47 0.6413 -0.00428373 0.00263821
thalach 0.018028 0.00457232 3.94 <1e-04 0.00906645 0.0269896
oldpeak -0.421474 0.102024 -4.13 <1e-04 -0.621438 -0.221511
slope 0.37985 0.166509 2.28 0.0225 0.0534989 0.706202
ca -0.543177 0.110141 -4.93 <1e-06 -0.759049 -0.327304
───────────────────────────────────────────────────────────────────────────────
总 结
我们展示了编写 Julia 代码是多么简单,以及它在科学计算方面多么强大。我们发现,这种语言有可能超越 Python,因为它的语法简单,性能更高。Julia 对于数据科学来说还是个新事物,但我确信它是机器学习和人工智能的未来。
说实话,我每天都在学习关于 Julia 的新东西,如果你想了解更多关于使用 GPU 的并行计算和深度学习或一般的机器学习,请关注我未来的其他文章。我没有对预测模型做更多的探索,因为这是一篇带有一般示例的介绍性文章。
原文链接:
https://towardsdatascience.com/julia-for-data-science-a-new-age-data-science-bf0747a94851

你也「在看」吗?👇




