阿里达摩院SIGIR 2019:AI判案1秒钟,人工2小时 | 技术头条

作者 | Xin Zhou、Yating Zhang、Xiaozhong Liu、Changlong Sun, Luo Si
译者 | 王煜晨
责编 | Jane
出品 | AI科技大本营(id:rgznai100)
【导读】分析了上万个交易纠纷类案件,学习了近千条交易领域的法律条款,阿里 AI 针对每种案由,整理成计算机能理解的模型,同时,针对案件的每一个要素,阿里 AI 自动提供相关法条等判决依据,从而建立了一整套审判知识图谱,深刻刻画了交易人、交易行为与法律事实的关联性,并且把这种关联性融入到了 AI 中。当法官遇到类似案件时,阿里AI就能够针对纠纷争议点迅速开启“大脑”进行分析和判断,并向法官给出调解和判案建议。这一研究成果发表在信息检索领域的顶级学术会议 SIGIR 官网。SIGIR 组委会认为,阿里巴巴的这项技术是司法智能领域的一项开创性成果。目前,该技术已在杭州互联网法院试点应用。
前言
2018年4月,杭州西湖区人民法院出现了令人惊奇的一幕:在一次审判中,原告在家中,被告在1200多公里开外的律师事务所,靠智能法院在线面对面,现场的书记员也是个“机器人”,整个庭审现场仅法官一人。这场独特的“一个人的法庭”打开了社会对“智能司法”的想象空间,其背后正是阿里AI技术。
如果说“一个人的法庭”还属于审判流程的数字化、在线化的1.0阶段。那么,阿里的最新研究成果标志着智能司法2.0阶段到来。AI不再只是停留在完成庭审记录和证据链条的数字化工作,而是进入到真实诉讼环节,开始具备自主判案能力,真正成为一名“助理法官”。

以下为研究论文解读:
摘要
随着信息技术的飞速发展,电子经济获得了快速增长,并成为世界上动态性最强的经济活动之一。截至2018年,世界上主要的电商平台(如亚马逊、eBay、阿里巴巴)等都获得了巨大成功,并占领了全球零售市场的11.9%。但与此同时,新型法律纠纷也随着信息技术的发展不断出现。高效处理问题纠纷无论对商家还是用户都是一件好事,基于此背景下,阿里巴巴进行了相关研究,无论是研究成果还是未来在场景中的应用,都值得关注。
在传统诉讼流程中,法官判定一个交易纠纷案件的调解与审判方向,需要经过读案卷、查询交易对话记录、提炼争议焦点、查找相关法律条款等步骤,大约需要2小时,而通过上述精准识别模型,阿里AI只需要1秒左右时间,就可得出调解与审判方向并给出建议。这将大大节省法官的重复劳动时间,从而大幅提高司法效率。
在已有的相关研究中,学者们指出,无论是 ODR(online dispute resolution, ODR)还是正式的判决系统,通过使用多渠道的更好且易用的信息,并去除诉讼当事人的外表信息(如种族、性别、体重等),都能够有效降低判决过程中的主观偏见性。本文作者依据这一结论,决定使用多视图表示学习和多任务学习( ODR 和审判预测)来解决电子经济领域的法律智能化问题。在这一联合学习过程中,本文作者使用了包括法律知识图谱、消费者/售卖方信息、交易信息等多种类数据,以在对纠纷表示进行微调对过程中对可能的判决结果进行正则化。
本文是第一篇针对网络交易纠纷案件的智能化审判的研究论文,该论文对于维护法律公平性、保护网络交易中双方利益具有重要意义。不同于之前的分类和推荐类模型和方法,本文提出了一个端到端的多任务学习模型,该模型对法律判决模型和纠纷解决模型进行了联合训练。另外, ODR 任务在联合学习过程中提供了重要的法律数据,因此本文提出对模型能够有效解决法律数据稀疏对问题。
总体而言,本文的贡献如下:
(1)提出了一个全新的法律智能化问题;
(2)提出了通过多视图纠纷表示以量化法律案例对有效方法;
(3)论文模型能够有效挖掘法律案例背后的判决逻辑,并解释判例和判决结果之间的因果关系;
(4)使用超过百万级纠纷数据对模型进行了训练,并使用超过6858个判例对模型进行了评估。实验结果显示,本模型有效提高了诉讼结果预测的 Micro_F1 和 Micro_F2 分数。
(5)在移除敏感信息后,论文作者还公开了数据集
模型架构
在本文中,作者提出了一个使用多任务学习的方法,能够通过 ODR 和法律智能化的方式对 4 种不同类型对分类任务进行联合学习。在实际操作中,首先要对纠纷对产生原因进行分类,然后对可能对纠纷调解结果进行分类。当这一纠纷可能成为诉讼时,模型首先对其进行分类,然后基于前述阶段产生对诉讼事实对诉讼判决结果进行预测。在本文中,作者通过对其背后对逻辑体系进行思考,对上述对四个任务进行了序列性的处理(见图1),并假设纠纷的原因对其判决结果具有较高的重要性。纠纷原因也反映了诉讼的事实,该事实对判决结果会产生极大影响。
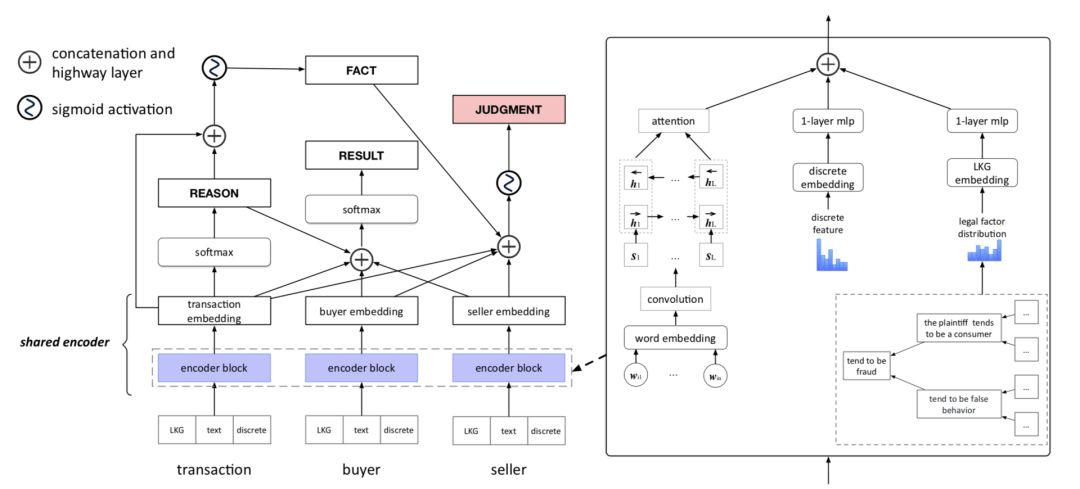
图1:本文提出的 LDJ 模型的网络结构
主要任务:法律判决预测
从法律视角而言,判决是对原告陈述对回应。本文将此过程定义为一个多标签分类任务,该任务是一个函数优化问题,该函数对给定案例表示的标签的实际价值进行预测。在函数中, x 为给定案例的表示,y 为判例标签, M 是分类的总数量。考虑到这一任务的训练数据可能较为稀疏,模型使用了多任务和多视图表示学习,通过子任务的信息对预测结果进行优化。
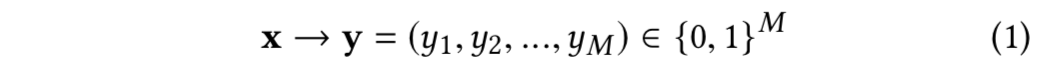
子任务 1:纠纷原因预测
纠纷原因预测是 ODR 的一部分,是一个单标签多任务分类任务,在这一任务中,每一个纠纷都对应一个纠纷原因,该原因由用户基于一个列表进行选择产生。这一任务和主任务的不同之处在于, ODR 数据库为该任务提供了充足的训练数据。该任务尝试学习一个映射函数,该函数将纠纷表示映射到类别标签中。在函数中, 向量 x 为纠纷的表示, k 为类别标签,k ∈ RK ,K 为种类的总数量。
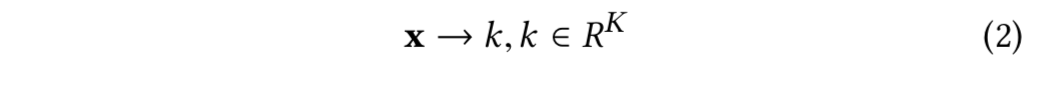
子任务 2:纠纷结果预测
通过使用案件信息和用户选择的纠纷原因,网络交易平台能够对纠纷调解结果进行判断,例如仅退款,退货并退款,或拒绝。和上一任务类似,这也是一个 ODR 单标签多类别分类任务。
子任务 3:诉讼事实预测
在实际案例中,如果顾客决定提交一个诉讼,法官会对通过查看所有证据了解诉讼事实情况,证据包括交易数据,协商结果等,以及案件被告。由于数据获取的困难性,在本文中,作者仅使用了纠纷数据,该数据可以从电商平台获得。
多视图纠纷表示
在网络交易系统中,一个纠纷案例往往包含三种类型的信息,即买卖双方与交易。从法律角度来看,每个案例都可以表示为法律知识图谱(legal knwoledge graph, LKG)的节点和边。模型需要使用元数据和问题数据进行这一表示。下表描述了本文对三个角度的信息进行表示时采用的特征。另外,对于法律表示,本文也适用了法律专家的知识,并同样将其表示为一个知识图谱。图2展示了这一知识图谱的一部分。
对于每个案例,本文都进行了三种表示:离散、文字、法律知识图谱,并在最后将三种表示结合,作为特征进行输入。
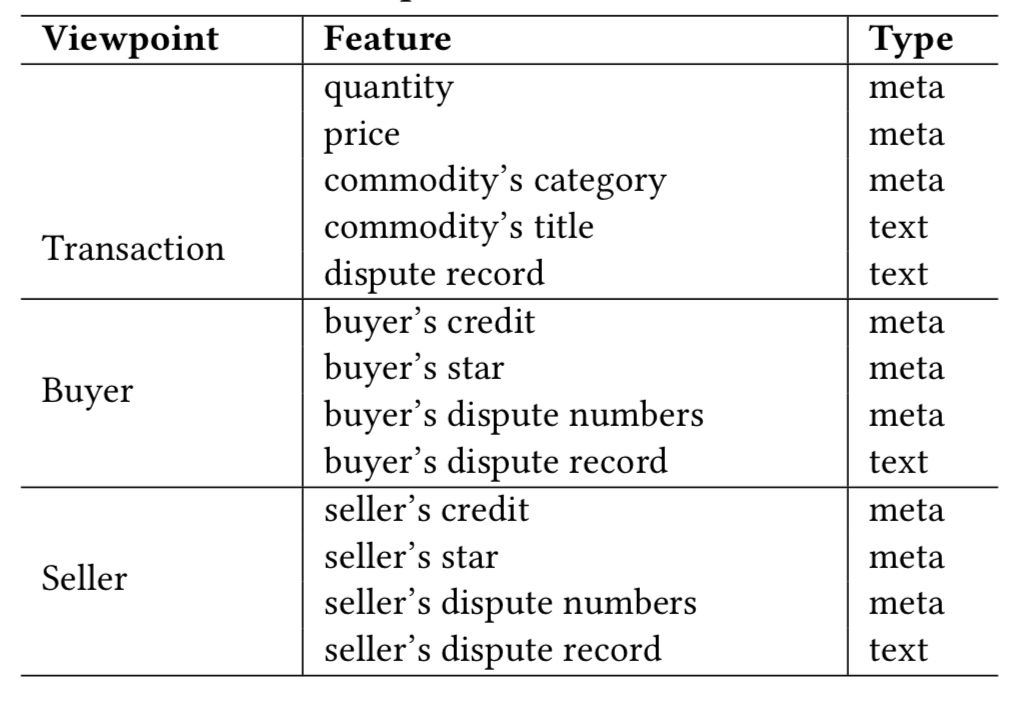
表1:使用的特征
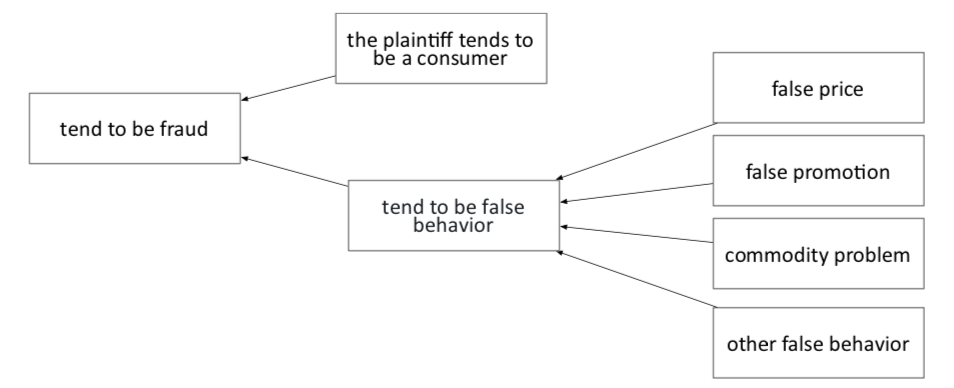
图2:法律知识图谱的部分示例
交易数据可以通过商品的数据和价格显示购买行为的状态。其中,商品信息包括反映了商品质量的负面评价,物流信息显示了商品的所属情况,线上纠纷记录展示了当前交易涉及的买家、卖家和平台管理者关于纠纷的对话记录。从买家角度,本文作者假设,买家的历史购买和纠纷记录能够展示其是一个普通消费者还是专业的欺诈者。与此类似,卖家的信用、评价和纠纷则能够表示其信用水平和商品质量。
从理论上来看,交易数据能够展示顾客提出纠纷的原因,并且在诉讼中,这一数据也是支持判决的重要证据。同时,对买家和卖家双方进行用户画像也是给出纠纷结果的基础步骤。
本文使用的法律知识图谱(Legal Knowledge Graph, LKG)是一个有向无环图(directed acyclic graph, DAG),LDK 和本体较为相似,其表示了不同场景下常见 OTD 的判决要求。图2展示了一个示例,在该示例中,电子经济欺诈案例可能会在多种情况下出现:虚假价格,虚假促销,商品问题等。每一场景都可能包含多个子场景。另外,若要将一个案例判决为欺诈,必须确认原告(或买家)是一个真实的消费者,而不是一个专业的欺诈者。在本论文中,作者利用 LKG 对每个案例进行了表示,并将其作为预测任务的输入。
法律纠纷判决模型
这一部分介绍本文提出的法律纠纷判决模型(Legal Dispute Judgment, LDJ)的推理步骤。多任务框架包含 3 个主要的部分:嵌入模块,共享编码器,以及基于任务的解码器;嵌入部分包括离散、文字和 LKG 三种类型的嵌入,用于表示法律条款之间的离散特征、文字特征的语义含义和语义连接。
输入:文字输入 xt 以文档形式展示,其中,xt = {s1, s2, ..., sL} 是一个包含 L 个句子的序列,其中每个句子 sj = {wi1, wi2,...wiT},语句包含 T 个词语,词语用词嵌入表示。离散输入 sd = {v1, v2, ..., vK} ,者是一个长度固定为 K 的值集合。 LKG 输入 xg = {a1, a2, ..., aN} 是一个概率分布,维度 N 表示 LKG 中的结点个数。
编码器:对文字输入进行编码,本文使用了一个具有等级结构的网络来提取文档结构,该网络首先建立对句子对表示,之后将其拼合为对文档对表示。
句子表示,本文使用卷积神经网络(convolutional neural network, CNN)来计算句子对连续表示。考虑到在本文处理的数据,消费者常倾向于使用长句子来表达案例情况, CNN 对本文情景更加适合。本文采用的 CNN 网络采用了多个具有不同宽度的卷积核来产生句子的表示。这种网络结构能够更好地学习多种粒度的 n-gram 结构的语义信息,这有利于句子分类任务的进行。
文档表示,本文采用一个双向 GRU 结构提取句子间的依赖信息,并对文档进行表示。相较于双向 LSTM ,这一结构能够对相邻句子对信息进行更有效对总结。
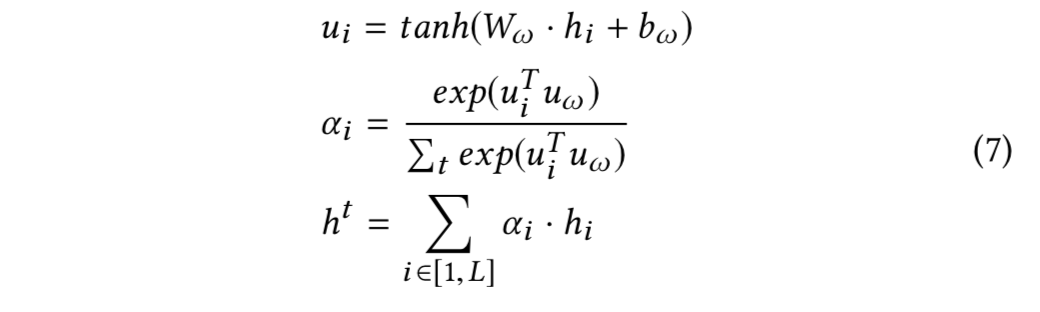
LKG & 离散表示,为了对 LKG 和离散输入进行编码,本文使用一个单层全连接神经网络进行了计算,该网络包含一个 logistic sigmoid 激活函数。 hg 和 hd 是 LKG 和离散输入的隐藏表示:
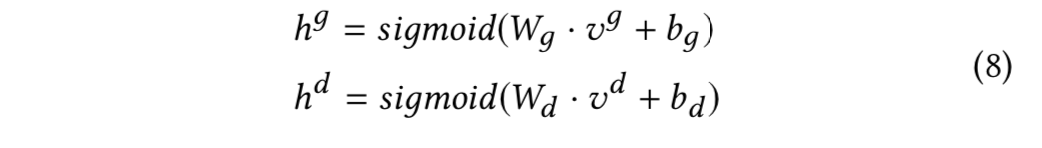
最后,论文将三种类型的表示进行拼接,得到编码器的最终输出:
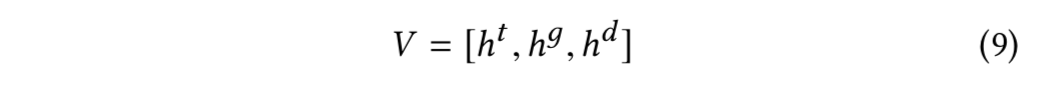
解码器:本部分,作者介绍了论文的各个子任务,以及主任务的实现方式。
子任务 1:纠纷原因预测
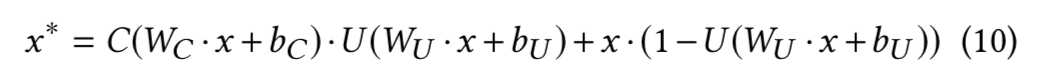
为预测纠纷的调解方案,本文使用了交易层的输出作为输入,并采用一个 Highway Network 来解决参数增长带来的训练困难问题。
子任务 2:纠纷结果预测
纠纷结果预测在推理层的最上层进行。考虑到使用历史交易和纠纷记录有助于达成更好的调解结果,本文将交易层、买家层和卖家层的输出以及推理层的输出进行了拼接,作为结果层的共同输入,这一步骤使用 Highway Network 进行了处理。带权重的原因标签嵌入表示如下:
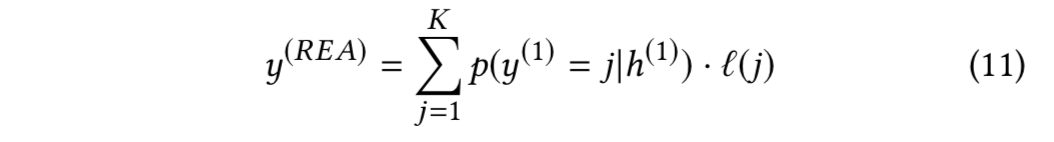
子任务 3:诉讼事实预测
这一部分的任务是预测法官会采用的法律事实,考虑到一些纠纷原因和测定的法律事实存在关联,该内容涉及纠纷原因预测过程。本文将交易层和原因层的拼接作为输入,并使用 Highway Network 进行处理。之后,模型将结果输入了一个包含 sigmoid 函数的全连接神经网络。和纠纷层的任务的不同之处在于,作者在这一部分对 sigmoid 激活使用了二元交叉熵,相较于 softmax 激活函数,这一方法对多标签分类任务更加有效。
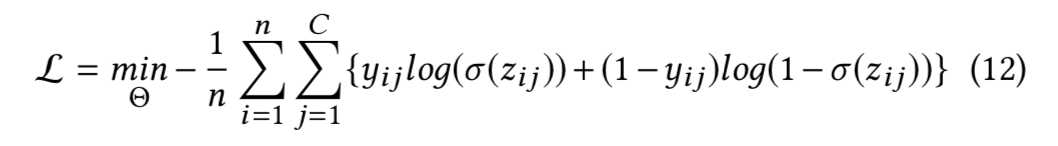
主任务:诉讼判决预测
这一部分,作者结合了交易信息、诉讼当事人对历史信息以及诉讼事实,并将四个部分的输出拼接为这一部分模型的输入。为了直接使用事实层的输出,作者对结果进行了标签嵌入。最后的结果同样适用 Highway Network 进行拼接,并输入到判决分类器。该分类器是一个包含 sigmoid 函数的全连接神经层,和事实分类器类似。这一部分,作者同样使用了二元交叉熵。
训练过程包含两部分。作者首先使用所有的离散数据训练原因层和结果层,并在这一步中关闭了事实层和判决层,以使用大量的数据对离散表示进行优化。之后,作者启动了四个任务层,并使用诉讼数据来微调参数。作者将主任务和子任务的损失权重设定为0.6, 0.2, 0.1, 0.1,并加和得到最总的损失函数值。
实验分析
(1)数据集:作者在两个数据集上进行了实验:淘宝历史纠纷数据,以及最高法院提供的诉讼数据。尽管数据集均为中国的电商数据和诉讼数据,但模型可用于世界各国的应用。
纠纷数据集(ODR):论文收集了40万条历史纠纷记录,记录包含 46 种纠纷原因和 3 种调解结果。最常见的纠纷原因为质量问题,错误订单,退换货和错误商品信息。调解结果包括退款并退货,拒绝和仅退款。
诉讼数据集:该数据集从中国在线判例网站爬取,判决文件由最高法院提供,可在线上公开获取。本文通过关键词检索,将判例限制在和淘宝相关的内容中。本文共收集了6858个案例。
本文使用 Word2Vec 对文本嵌入进行了预训练,使用百万级的纠纷记录进行了训练。使用的 CNN 网络包含的卷积核宽度为{1, 2, 3, 4, 5},输出维度为{32,32,64,128,256}。GRU维度为100。
(2)评价指标:本文使用了 Micro_F1 和 Micro_F2 作为主要的的评级指标。Macro-average)能够对每个类别的每个矩阵进行单独评估,并取平均值作为最终的分数。这一指标对于多标签多分类任务较为有效。
(3)基线:由于没有已有的针对法律判决任务的多任务学习的研究,本文通过比较多个最新的单任务判决预测模型效果对模型进行了评估,涉及方法包括传统机器学习模型(BSVM),深度学习模型两种,结果如下表。
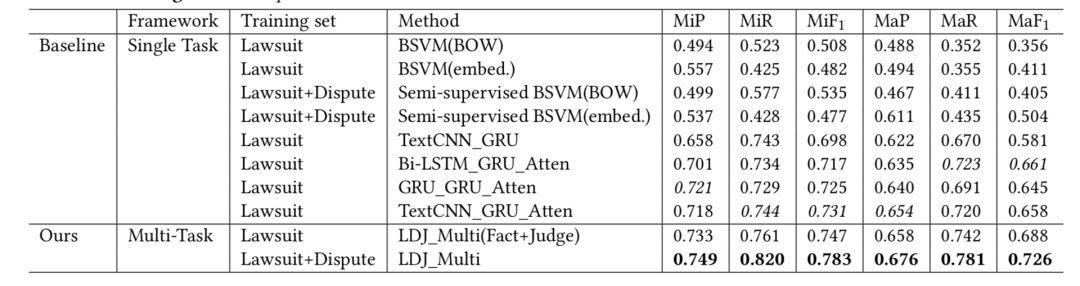
(4)模型表现:论文从以下四个角度展示了模型对评估结果:(a)和基线的比较;(b)使用多任务框架进行训练的优势;(c)使用多视角的有效性;(d)使用电商经济纠纷数据的影响。
从基线比较来看,LDJ_Multi 的效果超越了最好的模型表现。作者对最优模型和最优基线模型分别进行了消融实验,结果如表3。

表3:多视角消融实验
从使用电商纠纷数据对影响来看,作者展示了在诉讼判决预测上使用纠纷数据带带来的模型效果提升,如图3。
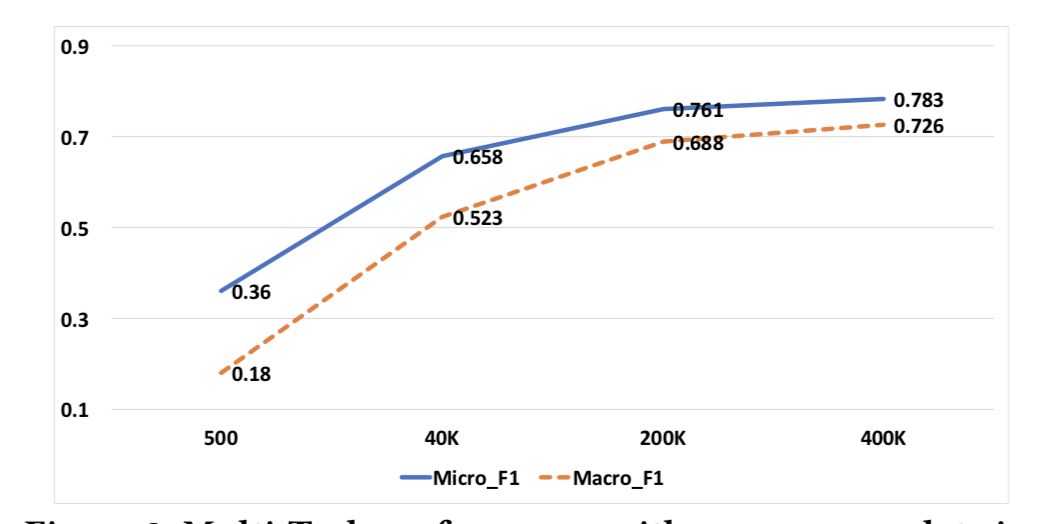
图3:电商纠纷数据带来的多任务效果提升
结论
作为一个交叉学科研究,进行法律纠纷预测能够将两个不相关的领域较好地连接在一起。在本文中,作者介绍了一个多视角纠纷表示技术,并提供了一个针对诉讼判决预测的端到端解决方法,该方法采用了包含三个子任务的联合学习。实验数据表明,联合学习能够有效提升现有模型的效果。另外,电商平台纠纷数据的使用也能够有效提升判决预测的效果。通过评估结果和错误分析,本文展示了纠纷表示的各个分面,并为未来工作进行了铺垫。
(*本文为 AI科技大本营原创文章,转载请微信联系 1092722531)
◆
公开课推荐
◆
想跟NVIDIA专业讲师学习TensorRT吗?扫码进群,获取报名地址,群内优秀提问者可获得限量奖品(定制T恤或者技术图书,包邮哦~)
NVIDIA TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习推理应用程序提供低延时和高吞吐量。通过TensorRT,开发者可以优化神经网络模型,以高精度校对低精度,最后将模型部署到超大规模数据中心、嵌入式平台或者汽车产品平台中。


推荐阅读:
新技术“红”不过十年,半监督学习为什么是个例外?
苹果宣布加入CNCF;华为要求美国运营商支付专利费;微软删除最大的公开人脸识别数据集
独家对话V神! 质疑之下的以太坊路在何方?
那些去德国的程序员后来怎么样了?
Python 分析在德的中国程序员,告别 996 ?





