利用 TFX 实现分布式 PCA
特邀作者 / 来自 maiot 的 Hamza Tahir
与 TFX 团队 Robert Crowe 和 Tris Warkentin

简介
主成分分析 (Principal Component Analysis,PCA) 是一种降维方法,适用于不同机器学习的许多场景。就其本质而言,PCA 可在保留数据集中最大方差的前提下降低输入向量的维度。降低模型输入的维度不但有助于提升模型的性能,并缩减训练所需的数据量和资源,同时还能降低非随机噪声。
TensorFlow Extended (TFX) 是一个免费的开源平台,用于创建预生产端到端机器学习流水线。在 maiot,TFX 是我们 Core Engine 的一个重要组成部分。Core Engine 最初是基于资产优化平台的基础构建而成,现在开发者可单独使用此工具来管理自己的深度学习工作负载。
在 Core Engine 中,我们为数据预处理提供了多种机制,其中包括对输入的海量数据应用 PCA 以实现可视化和学习。有鉴于此,我们准备了这篇文章,向大家展示如何使用 TFX 来对数据集进行分布式 PCA。
TensorFlow Transform
TFX 流水线由多个组件构成,同时这些组件又会利用各类 TensorFlow 库。在这些库中,TensorFlow Transform 是一个功能强大的用于预处理 TensorFlow 输入数据的库。TensorFlow Transform 的输出为 TensorFlow 图,供训练和上线时使用。由于这两个阶段中应用的转换相同,因此可防止出现偏差。
如同 TFX 的许多库和组件一样,TensorFlow Transform 使用 Apache Beam 进行处理,这样能在计算集群上分配工作负载。这种方式使得 Transform 能够处理海量数据集,并高效利用资源。Apache Beam 作为广泛使用的分布式计算框架上的抽象层运行,这些框架包括 Apache Spark、Apache Flink 和 Google Cloud Dataflow。在 maiot,我们通过 Google Cloud 中的托管和无服务式 Cloud Dataflow 服务,运行 Apache Beam。
借助 TensorFlow Transform,我们可以在 TFX 流水线中使用 PCA。使用 PCA 时,通常是在单个计算节点上运行。鉴于 TFX 的分布式特性,现在使用分布式 PCA 算法来对海量数据集进行可扩展处理要比以往任何时候都更容易。
示例展示 - 利用 TFX 实现 PCA
此 Colab Notebook 包含在运行 TFX 流水线时实现 PCA 的完整示例。该示例利用 TFX Interactive Notebook 环境 来创建 TFX 流水线,由此输出广泛使用的 Iris 数据集的主成分投影。
所有神奇过程均在 preprocessing_fn 函数中完成,之后该函数的结果将输出至 TFX 流水线中的 Transform 组件。此函数接受一个特征张量的字典,并会输出已应用相关转换后的特征的字典。您可以使用此处的常规 TensorFlow 代码,不过 TensorFlow Transform 中已经内置许多基本转换(如标准化、分桶、计算词汇量等)。您可在此处查找现成转换的完整列表。
其中一个内置转换是 tft.pca 转换,我们将使用此转换来计算数据集的 PCA。下方展示了在 preprocessing_fn 函数中使用此转换的方法。
def preprocessing_fn(inputs):
features = []
outputs = {}
for feature_tensor in inputs.values():
# standard scaler pre-req for PCA
features.append(tft.scale_to_z_score(feature_tensor))
# concat to make feature matrix for PCA to run over
feature_matrix = tf.concat(features, axis=1)
# get orthonormal vector matrix
orthonormal_vectors = tft.pca(feature_matrix, output_dim=2, dtype=tf.float32)
# multiply matrix by feature matrix to get projected transformation
pca_examples = tf.linalg.matmul(feature_matrix, orthonormal_vectors)
# unstack and add to output dict
pca_examples = tf.unstack(pca_examples, axis=1)
outputs['Principal Component 1'] = pca_examples[0]
outputs['Principal Component 2'] = pca_examples[1]
return outputs
注:本示例中,我们假定所有输入特征都为数值,且均会输出给 PCA 转换。如果需要,可以仅使用输入特征的一个子集。
以上片段中包含了大量内容,我们来仔细看一下。
首先,我们对所有输入张量应用标准化转换。这一步很重要,因为 PCA 算法要求输入向量成分均已转化为类似的度量单元。
其次,我们将输入的张量串联,以创建特征矩阵。我们在此处应用 tft.pca 函数。这样就能计算出数据的正交向量矩阵。如 tft.pca 文档中所述,该矩阵可用于计算数据的最终投影。我们通过将此矩阵与特征矩阵相乘来进行计算。最后一步是“分解”投影矩阵,以将各主要成分分开。然后,我们再将分解后的结果返回至输出字典。
在实际通过上述 preprocessing_fn 执行 Transform 组件时,抽象化的表层下隐藏着大量复杂过程。为了对计算集群执行分布式处理,TFX 创建了一个分布式 Apache Beam 流水线,用于计算相关的协方差和正交向量矩阵。TFX 还创建了已嵌入此转换的常规 TensorFlow 图,此图将会添加至您训练后的模型,以便您在部署时使用 PCA 转换。PCA 的最终结果是一个低维度的全新向量空间。在上线时,新数据将从最初的较高维度空间投影到这一维度较低的空间。
在成功运行 TFX 流水线后,您可以轻松使用 Transform 组件的输出来提取转换后的数据,以便实现可视化。在随附的 colab 中,以下正是最终显示结果:
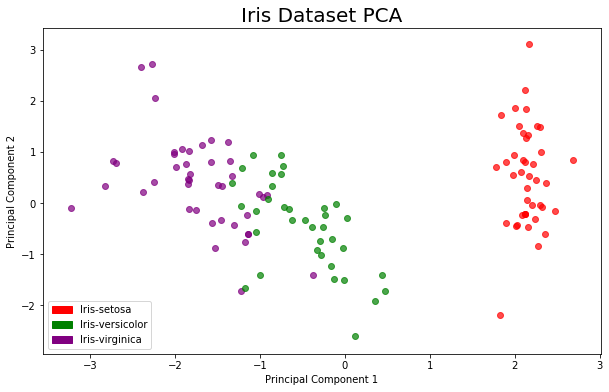
如您所见,在维度降低后的空间内,三种类别之间的分隔清晰可见。
结论
通过特征工程提升机器学习模型性能的数据转换方法数不胜数,PCA 仅仅是其中一种。如 PCA 一样,许多转换都需要超强的处理能力,在处理海量数据集时更是如此。
本文中,我们展示了 TensorFlow Transform 如何支持开发者利用计算集群中提供的资源,以可扩展的方式应用 PCA 等复杂转换。同时我们还展示了如何在 TFX 流水线中添加转换处理,以及在您训练后的模型中加入这些特征工程转换,以便在模型进行预测时执行完全一致的转换。
更多信息
要了解有关 TFX 的更多信息,请查看 TFX 网站,加入 TFX 论坛,深入了解公众号中关于 TFX 的其他内容,或并订阅 YT 中的 TensorFlow 频道。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
maiot
https://maiot.io/core?utm_source=core-engine-tensorflow-blog&utm_medium=blog&utm_campaign=core-engine-launchCore Engine
https://maiot.io/coreTensorFlow 库
https://tensorflow.google.cn/tfx/TensorFlow Transform
https://tensorflow.google.cn/tfx/transform/get_startedApache Beam
https://beam.apache.org/Apache Spark
https://spark.apache.org/Apache Flink
https://flink.apache.org/Google Cloud Dataflow
https://cloud.google.com/dataflow/
Colab Notebook
https://colab.sandbox.google.com/github/tensorflow/workshops/blob/master/blog/DistributedPCA.ipynbTFX Interactive Notebook 环境
https://blog.tensorflow.org/2019/11/introducing-tfx-interactive-notebook.html此处
https://tensorflow.google.cn/tfx/transform/api_docs/python/tfttft.pca / 文档
https://tensorflow.google.cn/tfx/transform/api_docs/python/tft/pcaApache Beam 流水线
https://beam.apache.org/计算相关的协方差和正交向量矩阵
https://github.com/tensorflow/transform/blob/7fccd88876c56496d252b713cd315f006c248084/tensorflow_transform/analyzers.py#L1847TFX 网站
https://tensorflow.google.cn/tfxTFX 论坛
https://groups.google.com/a/tensorflow.org/forum/#!forum/tfx订阅
https://goo.gle/2WtM7Ak








