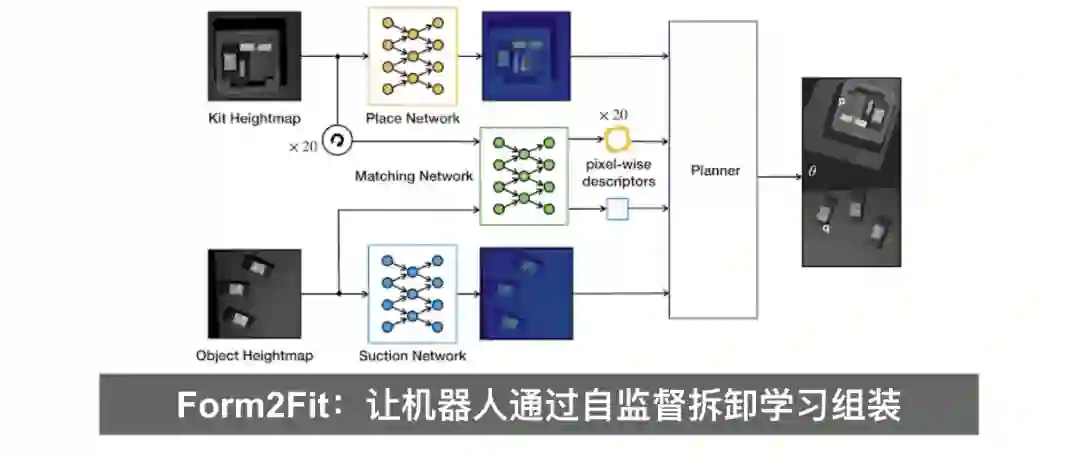
深度强化学习让机器人运动更灵活智能
文 / Yuxiang Yang 和 Deepali Jain,AI Residents,
Google 机器人团队

深度强化学习 (Deep Reinforcement Learning,DRL) 领域的最新进展让腿足式机器人能够通过自动化环境交互掌握许多灵活的技能。但是,样本学习效率仍然是许多算法面临的主要瓶颈,研究人员不得不依靠使用异策略数据、模仿动物行为或执行元学习来减少对现实世界经验的需求。此外,现有的此类机器人作品大多仅关注简单的低级技能,例如前进、后退和转弯。要想在现实世界中实现自主操作,机器人仍需要将这些技能结合起来,以产生更高级的行为。
模仿动物行为
https://ai.googleblog.com/2020/04/exploring-nature-inspired-robot-agility.html
今天,我们将介绍两个项目,目的是解决上述问题,并帮助闭合腿足式机器人的感知 - 驱动回路。
在《腿足式机器人的数据效率强化学习》(Data Efficient Reinforcement Learning for Legged Robots) 中,我们展示了一种高效学习低级运动控制策略的方法。通过将动力学模型拟合到机器人并实时规划动作,机器人可以利用不到 5 分钟的数据来学习多项运动技能。
腿足式机器人的数据效率强化学习
https://arxiv.org/abs/1907.03613
除了简单行为,我们还在《四足机器人的分层强化学习》(Hierarchical Reinforcement Learning for Quadruped Locomotion) 一文中探讨了自动路径导航。借助专为端到端训练设计的策略架构,机器人学会了将高级规划策略与低级运动控制器相结合,实现了弯曲路径上的自主导航。
四足机器人的分层强化学习
https://arxiv.org/pdf/1905.08926.pdf
腿足式机器人的数据效率强化学习
RL 中最大的拦路虎就是样本学习效率低下。即便是利用最先进 (SOTA) 的样本效率学习 (Sample-Efficient Learning) 算法,如 Soft Actor-Critic (SAC),仍需要超过一个小时的数据来学习合理的行走策略,而在现实中很难收集到这些数据。
我们一直使用与现实环境互动最少的方法来学习行走技能,在此过程中,我们提出了一种基于模型的方法,用来学习基本的行走技能。没有直接学习从环境状态映射到机器人动作的策略,而是从机器人的动力学模型入手,该模型会根据机器人当前的状态和动作来估测未来的状态。由于整个学习过程仅需要不到 5 分钟的数据,因此可以直接在真正的机器人上执行。
我们首先在机器人上执行随机动作,然后将模型拟合到所收集的数据。拟合模型后,我们通过模型预测控制 (Model Predictive Control,MPC) 规划器来控制机器人。我们在通过 MPC 收集更多数据与重新训练模型以更好地拟合环境动力学这两个过程之间进行迭代。
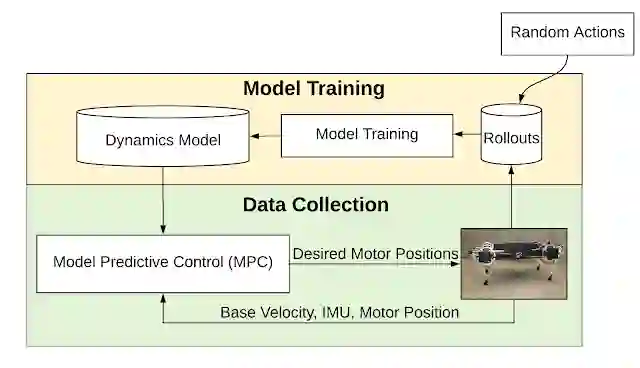
基于模型的机器学习流水线概述:系统交替进行拟合动力学模型和使用 MPC 收集轨迹这两个过程
在标准 MPC 中,控制器在每个时间步上规划一系列动作,并且仅执行规划的第一个动作。利用从机器人到控制器的定期反馈来执行在线重新规划,让控制器能够针对模型的不准确保持稳定性,但同时这也给动作规划器带来了挑战,因为必须要在控制回路的下一步骤之前完成学习(对于腿足式机器人,往往只有不到 10 毫秒的时间)。
为满足严格的时间限制,我们引入了多线程异步版 MPC,动作规划和执行在不同线程上完成。执行线程频繁地执行动作,而规划线程则随之对后台动作进行优化。此外,由于动作规划可能需要多个时间步,因此完成规划后机器人的状态可能已经发生变化。为了解决规划延迟问题,我们设计了一种新的补偿技术:首先会预测规划器预计完成计算时的未来状态,然后使用该未来状态为规划算法提供种子。
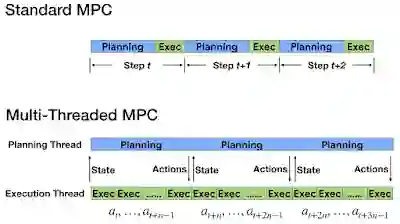
动作规划和执行分别在两个线程中独立完成
尽管 MPC 会频繁刷新动作规划,但规划器仍需要在更长的时间跨度中来关注长期目标,来避免出现缺乏远见的行为。为此,我们使用 多步骤损失 函数,这是对模型损失函数的重新定义,可通过预测一系列未来步骤中的损失,帮助减少长期的累积误差。
使用真实机器人学习时,安全是另一大问题。对于腿足式机器人来说,像踏错步这种小问题都可能造成灾难性故障,导致机器人摔倒或电机过热。为确保探索过程中的安全性,我们事先嵌入了一个原地踏步的稳定步态,由轨迹生成器进行调节。能够稳定行走之后,MPC 便可安全探索动作空间。
轨迹生成器
http://proceedings.mlr.press/v87/iscen18a.html

机器人仅用 4.5 分钟的数据就学会了行走

机器人使用相同的框架学习后空翻以及用后腿走路
将低级别控制器与高级别规划相结合
尽管基于模型的 RL 能让机器人高效地学习简单的运动技能,但这些技能不足以处理复杂的实际任务。例如,为了穿过办公空间,机器人可能需要多次调整速度、方向和高度,而不是遵循预先设定的速度曲线。传统方法中,人们解决此类复杂任务的方式是将其分解为多层级的子问题,如高级轨迹规划器和低级轨迹跟踪控制器。然而,手动定义一个合适的层级通常比较枯燥乏味,因为需要对每个子问题进行仔细的工程设计。
在我们的第二篇文章中,我们介绍了分层强化学习 (HRL) 框架,此框架经训练后可自动分解复杂的强化学习任务。我们将策略结构分解为高级和低级策略。无需手动设计每个策略,我们只需在策略级别间建立一个简单的通信协议。在此框架中,高级策略(例如,轨迹规划器)通过潜在指令向低级策略(例如运动控制策略)发出命令,并确定在发出新命令之前该的作用的时长。然后,低级策略解释来自高级策略的潜指令,并将电机控制命令传达给机器人。
为便于学习,我们还将观察空间划分为高级别(例如机器人位置和方向)和低级别(IMU,电机位置)观察结果,这些观察结果将馈送到相应的策略。此架构本身支持高级策略的运行时段比低级策略更长,这样可以节省计算资源并降低训练复杂性。
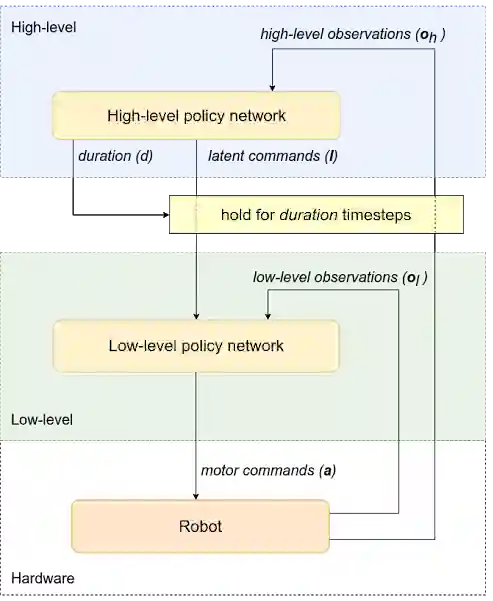
分层策略的框架:此策略从机器人获得观察结果,并发送电机命令以执行期望的动作。此框架分为两个级别(高和低)。高级策略会向低级策略发出潜在命令,同时确定低级策略的运行持续时间
因为高级和低级策略在各自的时段内运行,所以整个策略结构并非端到端可微分,也无法使用诸如 PPO 和 SAC 等基于梯度的标准 RL 算法。为此,我们转而选择通过增强随机搜索 (ARS) 来训练分层策略,这是一种简单的渐进优化方法,在处理强化学习任务时表现出良好的性能。对两个策略级别的权重同时进行训练,目的是让机器人轨迹的总体奖励最大化。
我们用同一个四足机器人执行路径跟踪任务,以此测试我们的框架。除了直走,机器人还需要朝不同方向转弯才能完成任务。请注意,由于低级策略不知道机器人在路径中的位置,因此没有足够的信息独自完成整个任务。然而,在高级和低级策略的协调作用下,机器人的转向行为在潜在的指令空间中自动产生,从而让机器人高效完成路径。在模拟环境中成功训练后,我们通过将 HRL 策略传送给真实的机器人并记录其走过的轨迹,在硬件上验证了我们的结果。

机器人在曲线路径上成功走完的轨迹。左图:机器人走过的轨迹图,轨迹上的点标记高级策略向低级策略发送新的潜在命令的位置;中图:机器人在模拟环境中沿路径行走;右图:机器人在实际环境中绕路径行走
为进一步演示习得的分层策略,我们展示了习得的低级策略在不同潜在命令下的行为。如下图所示,不同的潜在命令可能会让机器人以不同的速度直走、或向左、向右转弯。我们还通过将低级策略迁移到类似域中的新任务来测试其通用性,在我们的例子中,这些任务包括沿不同形状的路径行走。将低级策略的权重设置定值,只训练高级策略,机器人可以成功走完不同的路径。
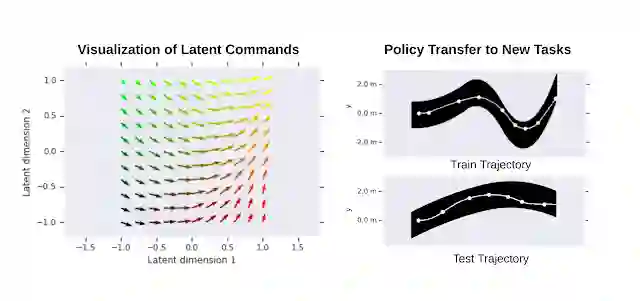
左图:习得的二维潜在命令空间的可视化:矢量方向对应于机器人的移动方向。矢量长度与走过的距离成正比。右图:低级策略的迁移:HRL 策略是在单一路径上训练的(右上)。在其他路径(右下)上训练高级策略时,将重复使用习得的低级策略
结论
通过将控制器设计过程自动化,强化学习为机器人技术的发展开辟了光明的前景。利用基于模型的 RL,我们能够直接在真实机器人上高效学习可泛化的运动行为。借助分层 RL,机器人学会了协调利用不同级别的策略完成更复杂的任务。未来,我们计划将感知引入回路,让机器人能够在现实世界中真正地自主运行。
致谢
Deepali Jain 和 Yuxiang Yang 都是 AI Residency 中的学员,导师为 Ken Caluwaerts 和 Atil Iscen。同时感谢 Jie Tan 和 Vikas Sindhwani 对这项研究的支持,也感谢 Noah Broestl 对纽约 AI 学员计划的管理。
— 推荐阅读 —