语音识别概论


文章作者:洪青阳
内容来源:《语音识别:原理与应用》
导读:语音识别是一门综合性学科,涉及的领域非常广泛,包括声学、语音学、语言学、信号处理、概率统计、信息论、模式识别和深度学习等。语音识别的基础理论包括语音的产生和感知过程、语音信号基础知识、语音特征提取等,关键技术包括高斯混合模型 ( Gaussian Mixture Model,GMM )、隐马尔可夫模型 ( Hidden Markov Model,HMM )、深度神经网络 ( Deep Neural Network,DNN ),以及基于这些模型形成的GMM-HMM、DNN-HMM和端到端 ( End-to-End,E2E ) 系统。语言模型和解码器也非常关键,直接影响语音识别实际应用的效果。
为了让读者更好地理解语音信号的特性,接下来我们首先介绍语音的产生和感知机制。
01
如图1-1所示,人的发音器官包括:肺、气管、声带、喉、咽、鼻腔、口腔和唇。肺部产生的气流冲击声带,产生振动。声带每开启和闭合一次的时间是一个基音周期 ( Pitch period ) T,其倒数为基音频率 ( F0=1/T,基频 ),范围在70Hz~450Hz。基频越高,声音越尖细,如小孩的声音比大人尖,就是因为其基频更高。基频随时间的变化,也反映声调的变化。

声道主要由口腔和鼻腔组成,它是对发音起重要作用的器官,气流在声道会产生共振。前五个共振峰频率 ( F1、F2、F3、F4和F5 ),反映了声道的主要特征。共振峰的位置、带宽和幅度决定元音音色,改变声道形状可改变共振峰,改变音色。
语音可分为浊音和清音,其中浊音是由声带振动并激励声道而得到的语音,清音是由气流高速冲过某处收缩的声道所产生的语音。
语音的产生过程可进一步抽象成如图1-2所示的激励模型,包含激励源和声道部分。在激励源部分,冲击序列发生器以基音周期产生周期性信号,经过声带振动,相当于经过声门波模型,肺部气流大小相当于振幅;随机噪声发生器产生非周期信号。声道模型模拟口腔、鼻腔等声道器官,最后产生语音信号。我们要发浊音时,声带振动形成准周期的冲击序列。发清音时,声带松弛,相当于发出一个随机噪声。
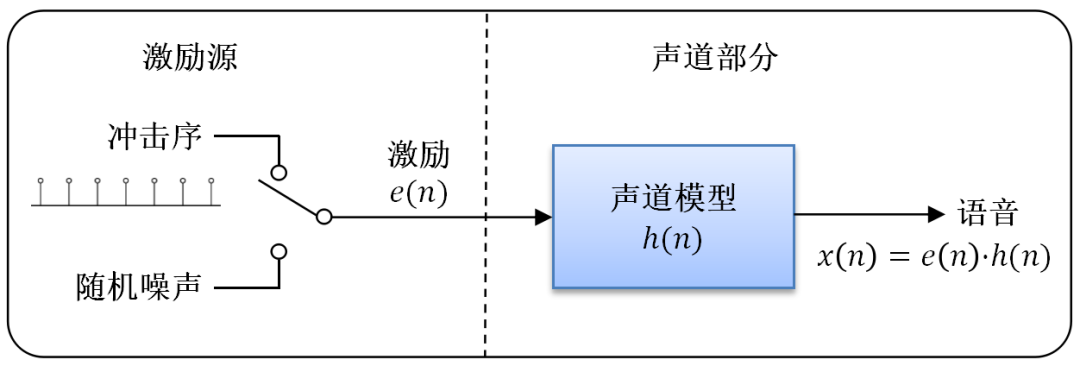
图1-2 产生语音的激励模型
如图1-3所示,人耳是声音的感知器官,分为外耳、中耳和内耳三部分。外耳的作用包括声源的定位和声音的放大。
外耳包含耳翼和外耳道,耳翼的作用是保护耳孔,并具有定向作用。外耳道同其他管道一样也有共振频率,大约是3400 Hz。鼓膜位于外耳道内端,声音的振动通过鼓膜传到内耳。中耳由三块听小骨组成,作用包括放大声压和保护内耳。中耳通过咽鼓管与鼻腔相通,其作用是调节中耳压力。内耳的耳蜗实现声振动到神经冲动的转换,并传递到大脑。
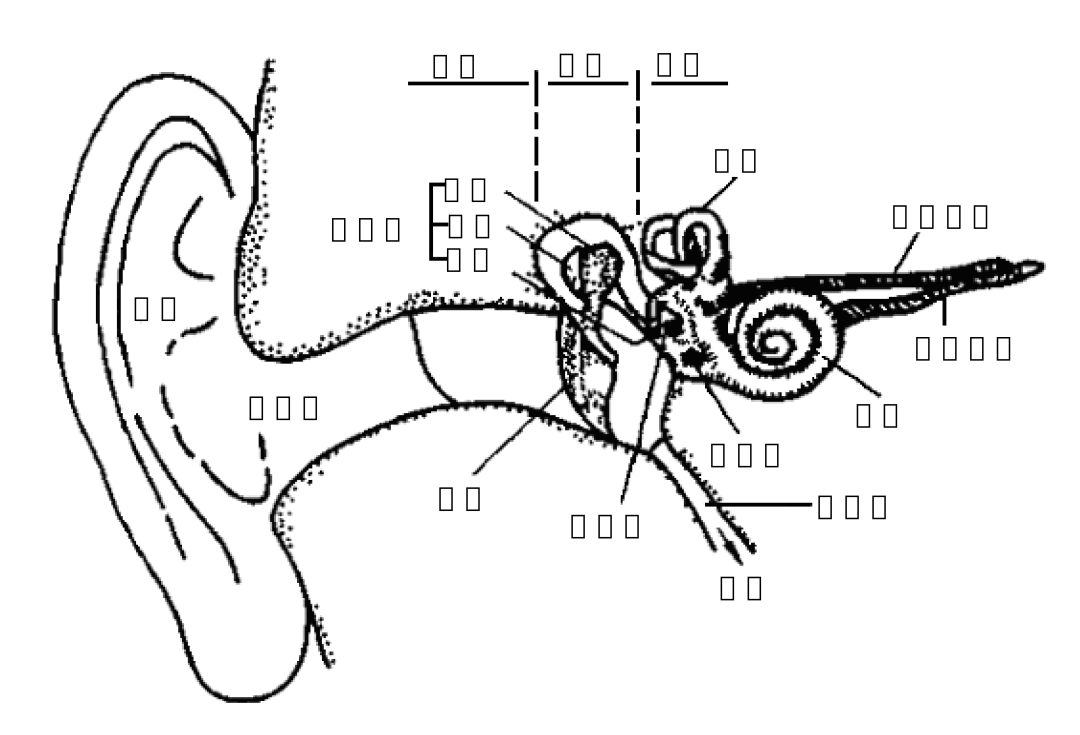
正常人耳能感知的频率范围为20 Hz~20 kHz,强度范围为0 dB~120 dB。人耳对不同频率的感知程度是不同的。音调是人耳对不同频率声音的一种主观感觉,单位为mel。mel频率与在1kHz以下的频率近似成线性正比关系,与1kHz以上的频率成对数正比关系。
人耳接收到声音后,经过神经传导到大脑分析,判断声音类型,并进一步分辨可能的发音内容。人的大脑从婴儿出生开始,就不断在学习外界的声音,经过长时间的潜移默化,最终才听懂人类的语言。机器跟人一样,也需要学习语言的共性和发音的规律,才能进行语音识别。
音素 ( phone ) 是构成语音的最小单位。英语中有48个音素 ( 20个元音和28个辅音 )。采用元音和辅音来分类,汉语普通话有32个音素,包括元音10个,辅音22个。
但普通话的韵母很多是复韵母,不是简单的元音,因此拼音一般分为声母 ( initial ) 和韵母 ( final )。汉语中原来有21个声母和36个韵母,经过扩充 ( 增加a o e y w v ) 和调整后,包含27个声母和38个韵母 ( 不带声调 ) ,如表1-1所示。

音节 ( syllable ) 是听觉能感受到的最自然的语音单位,由一个或多个音素按一定的规律组合而成。英语音节可单独由一个元音构成,也可由一个元音和一个或多个辅音构成。汉语的音节由声母、韵母和音调构成,其中音调信息包含在韵母中。所以,汉语音节结构可以简化为:声母+韵母。
汉语中有409个无调音节,约1300个有调音节。
汉字与汉语音节并不是一一对应的。一个汉字可以对应多个音节,一个音节可对应多个汉字,例如:
和 —— hé hè huó huò hú
tián —— 填 甜
语音识别过程是个复杂的过程,但其最终任务归结为,找到对应观察值序列O的最可能的词序列W。按贝叶斯准则转化为:
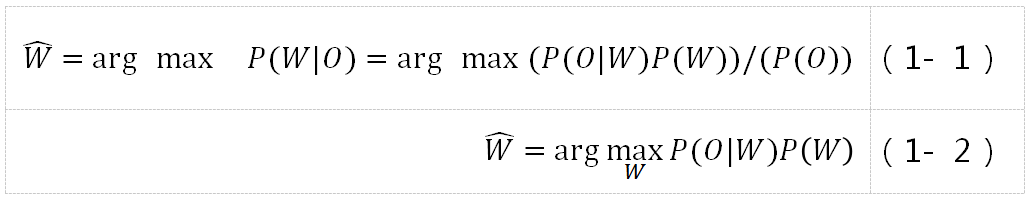
其中,P(O)与P(W)没有关系,可认为是常量,因此P(W|O)的最大值可转换为P(O|W)和P(W)两项乘积的最大值,第一项P(O|W)由声学模型决定,第二项P(W)由语言模型决定。
图1-4所示是典型的语音识别过程。为了让机器识别语音,首先提取声学特征,然后通过解码器得到状态序列,并转换为对应的识别单元。一般是通过词典将音素序列 ( 如普通话的声母和韵母 ),转换为词序列,然后用语言模型规整约束,最后得到句子识别结果。
例如,对"今天天气很好"进行词序列、音素序列、状态序列的分解,并和观察值序列对应,如图1-5所示。其中每个音素对应一个HMM,并且其发射状态 ( 深色 ) 对应多帧观察值。
从图1-5中可看出,人的发音包含双重随机过程,即说什么不确定,怎么说也不确定,很难用简单的模板匹配技术来识别。更合适的方法是用HMM这种统计模型来刻画双重随机过程。
我们来看一个简单的例子,假设词典包含:
今天 j in1 t ian1

则"今天"的词HMM由"j"、"in1"、"t"和"ian1"四个音素HMM串接而成,形成一个完整的模型以进行解码识别。这个解码过程可以找出每个音素的边界信息,即每个音素 ( 包括状态 ) 对应哪些观察值 ( 特征向量 ),均可以匹配出来。音素状态与观察值之间的匹配关系用概率值衡量,可以用高斯分布或DNN来描述。
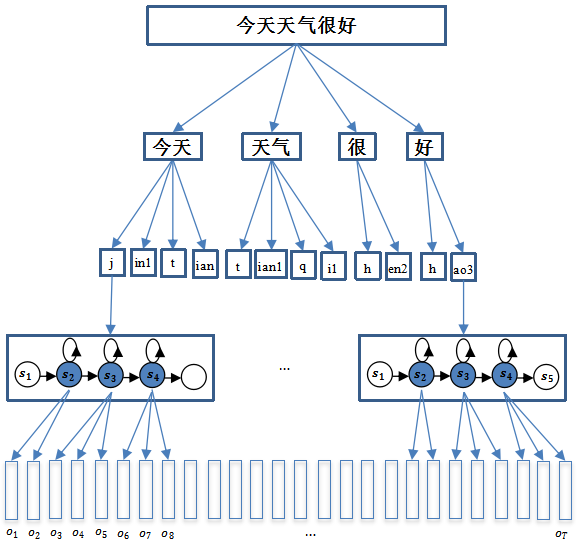
图1-5 从句子到状态序列的分解过程
语音识别任务有简单的孤立词识别,也有复杂的连续语音识别,工业应用普遍要求大词汇量连续语音识别 ( LVCSR )。图1-6所示是主流的语音识别系统框架。对输入的语音提取声学特征后,得到一序列的观察值向量,再将它们送到解码器识别,最后得到识别结果。解码器一般是基于声学模型、语言模型和发音词典等知识源来识别的,这些知识源可以在识别过程中动态加载,也可以预先编译成统一的静态网络,在识别前一次性加载。发音词典要事先设计好,而声学模型需要由大批量的语音数据 ( 涉及各地口音、不同年龄、性别、语速等方面 ) 训练而成,语言模型则由各种文本语料训练而成。为保证识别效果,每个部分都需要精细的调优,因此对系统研发人员的专业背景有较高的要求。
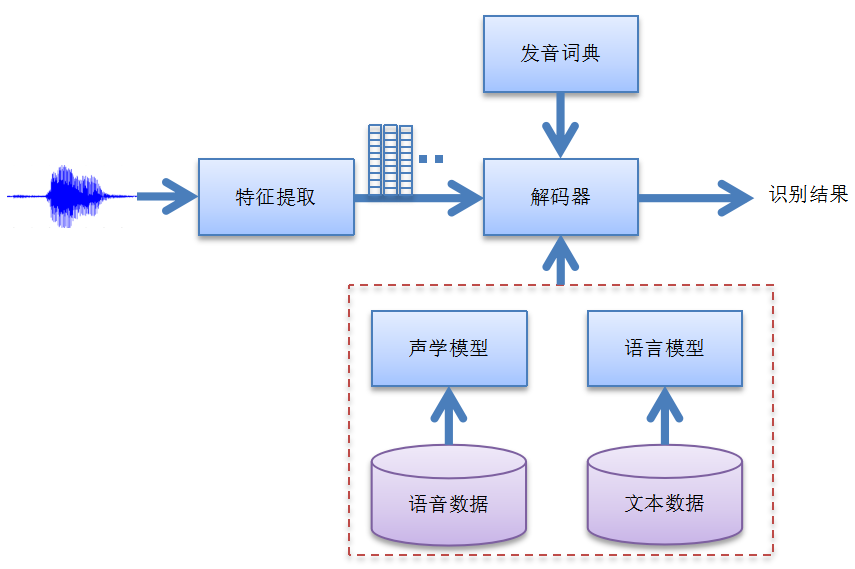
图1-6 主流的语音识别系统框架
罗马城不是一天建成的,语音识别近些年的爆发也并非一朝一夕可以做到的,而是经过了一段漫长的发展历程。从最初的语音识别雏形,到高达90%以上准确率的现在,经过了大约100年的时间。在电子计算机被发明之前的20世纪20年代,生产的一种叫作"Radio Rex"的玩具狗被认为是世界上最早的语音识别器。每当有人喊出"Rex"这个词时,这只狗就从底座上弹出来,以此回应人类的"呼唤"。但是实际上,它使用的技术并不是真正意义上的语音识别技术,而是使用了一个特殊的弹簧,每当该弹簧接收到频率为500Hz的声音时,它就会被自动释放,而500Hz恰好就是人们喊出"Rex"时的第一个共振峰的频率。"Radio Rex"玩具狗被视为语音识别的雏形。
真正意义上的语音识别研究起源于20世纪50年代。先是美国的AT&T Bell实验室的Davis等人成功开发出了世界上第一个孤立词语音识别系统——Audry系统,该系统能够识别10个英文数字的发音[1],正确率高达98%。1956年,美国普林斯顿大学的实验室使用模拟滤波器组提取出元音的频谱后,通过模板匹配,建立了针对特定说话人的包括10个单音节词的语音识别系统。1959年,英国伦敦大学的科学家Fry和Denes等人第一次利用统计学的原理构建出了一个可以识别出4个元音和9个辅音的音素识别器。在同一年,美国麻省理工学院林肯实验室的研究人员则首次实现了可以针对非特定人的可识别10个元音音素的识别器[2]。
图1-7给出了语音识别技术的发展历史,主要包括模板匹配、统计模型和深度学习三个阶段。
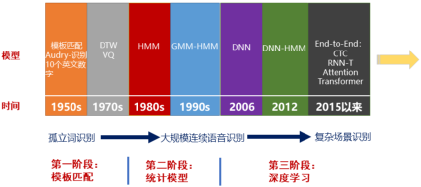
图1-7 语音识别发展历史
第一阶段:模板匹配 ( DTW )
20世纪60年代,一些重要的语音识别的经典理论先后被提出和发表出来。1964年,Martin为了解决语音时长不一致的问题,提出了一种时间归一化的方法,该方法可以可靠地检测出语音的端点,这可以有效地降低语音时长对识别结果的影响,使语音识别结果的可变性减小了。1966年,卡耐基梅隆大学的 Reddy 利用动态跟踪音素的方法进行了连续语音识别,这是一项开创性的工作。1968年,前苏联科学家Vintsyuk首次提出将动态规划算法应用于对语音信号的时间规整。虽然在他的工作中,动态时间规整的概念和算法原型都有体现,但在当时并没有引起足够的重视。这三项研究工作,为此后几十年语音识别的发展奠定了坚实的基础。虽然在这10年中语音识别理论取得了明显的进步,但是这距离实现真正实用且可靠的语音识别系统的目标依旧十分遥远。
20世纪70年代,语音识别技术飞速发展,又取得了几个突破性的进展。1970年,来自前苏联的Velichko和Zagoruyko将模式识别的概念引入语音识别中。同年,Itakura提出了线性预测编码 ( Linear Predictive Coding,LPC ) 技术,并将该技术应用于语音识别。1978年,日本人Sakoe和Chiba在前苏联科学家Vintsyuk的工作基础上,成功地使用动态规划算法将两段不同长度的语音在时间轴上进行了对齐,这就是我们现在经常提到的动态时间规整 ( Dynamic Time Warping,DTW )[3][4]。该算法把时间规整和距离的计算有机地结合起来,解决了不同时长语音的匹配问题。在一些要求资源占用率低、识别人比较特定的环境下,DTW是一种很经典很常用的模板匹配算法。这些技术的提出完善了语音识别的理论研究,并且使得孤立词语音识别系统达到了一定的实用性。此后,以IBM公司和Bell实验室为代表的语音研究团队开始将研究重点放到大词汇量连续语音识别系统 ( Large Vocabulary Continuous Speech Recognition,LVCSR ),因为这在当时看来是更有挑战性和更有价值的研究方向。20世纪70年代末,Linda的团队提出了矢量量化 ( Vector Quantization,VQ )[5]的码本生成方法,该项工作对于语音编码技术具有重大意义。美国国防部下属的一个名为美国国防高级研究计划局 ( Defense Advanced Research Projects Agency,DARPA ) 的行政机构,在20世纪70年代介入语音领域,开始资助一项旨在支持语言理解系统的研究开发工作的10年战略计划。在该计划推动下,诞生了一系列不错的研究成果,如卡耐基梅隆大学推出了Harpy系统,其能识别1000多个单词且有不错的识别率。
第二阶段:统计模型 ( GMM-HMM )
到了20世纪80年代,更多的研究人员开始从对孤立词识别系统的研究转向对大词汇量连续语音识别系统的研究,并且大量的连续语音识别算法应运而生,例如分层构造 ( Level Building ) 算法等。同时,20世纪80年代的语音识别研究相较于20世纪70年代,另一个变化是基于统计模型的技术逐渐替代了基于模板匹配的技术。统计模型两项很重要的成果是声学模型和语言模型,语言模型以n元语言模型 ( n-gram ) 为代表,声学模型以HMM为代表。HMM的理论基础在1970年前后由Baum等人建立[6],随后由卡耐基梅隆大学 ( CMU ) 的Baker和IBM的Jelinek等人应用到语音识别中。在20世纪80年代中期,Bell实验室的L.R. Rabiner等人对HMM进行了深入浅出的介绍[7],并出版了语音识别专著Fundamentals of Speech Recognition[8],有力地推动了HMM在语音识别中的应用。Mark Gales和Steve Young在2007年对HMM在语音识别中的应用做了详细阐述[9]。随着统计模型的成功应用,HMM开始了对语音识别数十年的统治,直到现今仍被看作是领域内的主流技术。在DARPA的语音研究计划的资助下,又诞生了一批著名的语音识别系统,其中包括李开复 ( K.F.Lee ) 在卡耐基梅隆大学攻读博士学位时开发的SPHINX系统。该系统也是基于统计模型的非特定说话人连续语音识别系统,其采用了如下技术:① 用HMM对语音状态的转移概率建模;② 用高斯混合模型 ( Gaussian Mixture Model,GMM ) 对语音状态的观察值概率建模。这种把上述二者相结合的方法,称为高斯混合模型-隐马尔可夫模型 ( Gaussian Mixture Model-Hidden Markov Model,GMM-HMM )[9][10]。在深度学习热潮出现之前,GMM-HMM一直是语音识别最主流最核心的技术。值得注意的是,在20世纪80年代末,随着分布式知识表达和反向传播算法 ( Backpropagation,BP ) 的提出,解决了非线性学习问题,于是关于神经网络的研究兴起,人工神经网络 ( Artificial Neural Network,ANN )[11]被应用到语音领域并且掀起了一定的热潮。这是具有里程碑意义的事件,它为若干年后深度学习在语音识别中的崛起奠定了一定的基础。但是由于人工神经网络其自身的缺陷还未得到完全解决,它相对于GMM-HMM系统并没有什么优势可言,研究人员还是更倾向于基于统计模型的方法。在20世纪80年代还有一个值得一提的事件,美国国家标准技术署 ( NIST ) 在1987年第一次举办了NIST评测,这项评测在后来成为了全球最权威的语音评测。
20世纪90年代,语音识别进入了一个技术相对成熟的时期,主流的GMM-HMM框架得到了更广泛的应用,在领域中的地位越发稳固。声学模型的说话人自适应 ( Speaker Adaptation ) 方法和区分性训练 ( Discriminative Training ) 准则的提出,进一步提升了语音识别系统的性能。1994年提出的最大后验概率估计 ( Maximum A Posteriori Estimation,MAP )[12]和1995年提出的最大似然线性回归 ( Maximum Likelihood Linear Regression,MLLR )[13],帮助HMM实现了说话人自适应。最大互信息量 ( Maximum Mutual Information,MMI )[14]和最小分类错误 ( Minimum Classification Error,MCE )[15]等声学模型的区分性训练准则相继被提出,使用这些区分性准则去更新GMM-HMM的模型参数,可以让模型的性能得到显著提升。此外,人们开始使用以音素为代表的字词单元作为基本单元,一些支持大词汇量的语音识别系统被陆续开发出来,这些系统不但可以做到支持大词汇量非特定人连续语音识别,而且有的产品在可用性方面达到了很好的性能,例如微软公司的Whisper、贝尔实验室的PLATO、麻省理工学院的SUMMIT系统、IBM的ViaVioce系统。英国剑桥大学Steve Young开创的语音识别工具包HTK ( Hidden Markov Tool Kit )[10],是一套开源的基于HMM的语音识别软件工具包,它采用模块化设计,而且配套了非常详细的HTKBook 文档,这既方便了初学者的学习、实验 ( HTKBook 文档做得很好 ),也为语音识别的研究人员提供了专业且便于搭建的开发平台。HTK自1995年发布以来,被广泛采用。即便如今,大部分人在接受语音专业启蒙教育时,依然还是要通过HTK辅助将理论知识串联到工程实践中。可以说,HTK对语音识别行业的发展意义重大。
进入21世纪头几年,基于GMM-HMM的框架日臻成熟完善,人们对语音识别的要求已经不再满足于简单的朗读和对话,开始将目光着眼于生活中的普通场景,因此研究的重点转向了具有一定识别难度的日常流利对话、电话通话、会议对话、新闻广播等一些贴近人类实际应用需求的场景。但是在这些任务上,基于GMM-HMM框架的语音识别系统的表现并不能令人满意,识别率达到80%左右后,就无法再取得突破。人们发现一直占据主流的GMM-HMM框架也不是万能的,它在某些实际场景下的识别率无法达到人们对实际应用的要求和期望,这个阶段语音识别的研究陷入了瓶颈期。
第三阶段:深度学习 ( DNN-HMM,E2E )
2006年,变革到来。Hinton在全世界最权威的学术期刊Science上发表了论文,第一次提出了"深度置信网络"的概念[16][17]。深度置信网络与传统训练方式的不同之处在于它有一个被称为"预训练" ( pre-training ) 的过程,其作用是为了让神经网络的权值取到一个近似最优解的值,之后使用反向传播算法 ( BP ) 或者其他算法进行"微调" ( fine-tuning ),使整个网络得到训练优化。Hinton给这种多层神经网络的相关学习方法赋予了一个全新的名词——"深度学习" ( Deep Learning,DL )[18]。深度学习不仅使深层的神经网络训练变得更加容易,缩短了网络的训练时间,而且还大幅度提升了模型的性能。以这篇划时代的论文的发表为转折点,从此,全世界再次掀起了对神经网络的研究热潮,揭开了属于深度学习的时代序幕。
在2009年,Hinton和他的学生Mohamed将深层神经网络 ( DNN ) 应用于声学建模,他们的尝试在TIMIT音素识别任务上取得了成功。然而TIMIT数据库包含的词汇量较小,在面对连续语音识别任务时还往往达不到人们期望的识别词和句子的正确率。2012年,微软研究院的俞栋和邓力等人将深度学习与HMM相结合,提出了上下文相关的深度神经网络 ( Context Dependent Deep Neural Network,CD-DNN ) 与HMM融合的声学模型 ( CD-DNN-HMM )[19],在大词汇量的连续语音识别任务上取得了显著的进步,相比于传统的GMM-HMM系统获得超过20%的相对性能提升。这是深度学习在语言识别上具有重大意义的成果。从此,自动语音识别 ASR 的准确率得到了快速提升,深度学习彻底打破了GMM-HMM 的传统框架对于语音识别技术多年的垄断,使得人工智能获得了突破性的进展。由Daniel Povey领衔开发在2011年发布的Kaldi[20],是DNN-HMM系统的基石,在工业界得到广泛应用。大多数主流的语音识别解码器基于加权有限状态转换器 ( WFST )[21],把发音词典、声学模型和语言模型编译成静态解码网络,这样可大大加快解码速度,为语音识别的实时应用奠定基础。
近几年,随着机器学习算法的持续发展,各种神经网络模型结构层出不穷。循环神经网络 ( Recurrent Neural Network,RNN ) 可以更有效、更充分地利用语音中的上下文信息[22],卷积神经网络 ( Convolutional Neural Network,CNN ) 可以通过共享权值来减少计算的复杂度,并且CNN被证明在挖掘语音局部信息的能力上更为突出。引入了长短时记忆网络 ( Long Short Term Memory,LSTM ) 的循环神经网络 RNN,能够通过遗忘门和输出门忘记部分信息来解决梯度消失的问题[23]。由LSTM 也衍生出了许多变体,较为常用的是门控循环单元 ( Gated Recurrent Unit,GRU ),在训练数据很大的情况下GRU相比LSTM参数更少,因此更容易收敛,从而能节省很多时间。LSTM及其变体使得识别效果再次得到提升,尤其是在近场的语音识别任务上达到了可以满足人们日常生活的标准。另外,时延神经网络 ( Time Delay Neural Network,TDNN )[24]也获得了不错的识别效果,它可以适应语音的动态时域变化,能够学习到特征之间的时序依赖。
深度学习技术在近十几年中,一直保持着飞速发展的状态,它也推动语音识别技术不断取得突破。尤其是最近几年,基于端到端的语音识别方案逐渐成了行业中的关注重点,CTC ( Connectionist Temporal Classification )[25]算法就是其中一个较为经典的算法。在LSTM-CTC的框架中,最后一层往往会连接一个CTC模型,用它来替换HMM。CTC的作用是将Softmax层的输出向量直接输出成序列标签,这样就实现了输入语音和输出结果的直接映射,也实现了对整个语音的序列建模,而不仅仅是针对状态的静态分类。2012年,Graves等人又提出了循环神经网络变换器RNN Transducer[26],它是CTC的一个扩展,能够整合声学模型与语言模型,同时进行优化。自 2015 年以来,谷歌、亚马逊、百度等公司陆续开始了对CTC模型的研发和使用,并且都获得了不错的性能提升。
2014年,基于 Attention ( 注意力机制 ) 的端到端技术在机器翻译领域中得到了广泛的应用并取得了较好的实验结果[27],之后很快被大规模商用。于是,Jan Chorowski在2015年将Attention的应用扩展到了语音识别领域[28],结果大放异彩。在最近的两年里,有一种称为Seq2Seq ( Sequence to Sequence ) 的基于Attention的语音识别模型[29]在学术界引起了极大的关注,相关的研究取得了较大的进展。在加拿大召开的国际智能语音领域的顶级会议ICASSP2018上,谷歌公司发表的研究成果显示,在英语语音识别任务上,基于 Attention 的 Seq2Seq 模型表现强劲,它的识别结果已经超越了其他语音识别模型[30]。但 Attention 模型的对齐关系没有先后顺序的限制,完全靠数据驱动得到,对齐的盲目性会导致训练和解码时间过长。而 CTC 的前向后向算法可以引导输出序列与输入序列按时间顺序对齐。因此 CTC 和 Attention 模型各有优势,可把两者结合起来,构建 Hybrid CTC/Attention模型[31],并采用多任务学习,以取得更好的效果。
2017年,Google和多伦多大学提出一种称为Transformer[32]的全新架构,这种架构在Decoder和Encoder中均采用Attention机制。特别是在Encoder层,将传统的RNN完全用Attention替代,从而在机器翻译任务上取得了更优的结果,引起了极大关注。随后,研究人员把Transformer应用到端到端语音识别系统[33][34]中,也取得了非常明显的改进效果。
另外,生成式对抗网络 ( Generative Adversarial Network,GAN ) 是近年来无监督学习方面最具前景的一种新颖的深度学习模型,Ian J. Goodfellow等人于2014年10月发表论文"Generative Adversarial Nets"[36],文中提出了一个通过对抗过程估计生成模型框架的全新方法。通过对抗学习,GAN可用于提升语音识别的噪声鲁棒性。GAN网络在无监督学习方面展现出了较大的研究潜质和较好的应用前景。
从一个更高的角度来看待语音识别的研究历程,从HMM到GMM,到DNN,再到CTC和Attention,这个演进过程的主线是如何利用一个网络模型实现对声学模型层面更精准的刻画。换言之,就是不断尝试更好的建模方式以取代基于统计的建模方式。
在2010年以前,语音识别行业水平普遍还停留在80%的准确率以下。在接下来的几年里,机器学习相关模型算法的应用和计算机性能的增强,带来了语音识别准确率的大幅提升。到 2015年,识别准确率就达到了 90%以上。谷歌公司在2013年时,识别准确率还仅仅只有77%,然而到2017年5月时,基于谷歌深度学习的英语语音识别错误率已经降低到4.9%,即识别准确率为95.1%,相较于2013年的准确率提升了接近20个百分点。这种水平的准确率已经接近正常人类。2016年10月18日,微软语音团队在Switchboard语音识别测试中打破了自己的最好成绩,将词错误率降低至 5.9%。次年,微软语音团队研究人员通过改进语音识别系统中基于神经网络的声学模型和语言模型,在之前的基础上引入了CNN-BLSTM ( Convolutional Neural Network Combined with Bidirectional Long Short-Term Memory,带有双向LSTM的卷积神经网络 ) 模型,用于提升语音建模的效果。2017年8月20日,微软语音团队再次将这一纪录刷新,在Switchboard测试中将词错误率从5.9%降低到5.1%,即识别准确率达到 94.9%,与谷歌一起成为了行业新的标杆。另外,亚马逊 ( Amazon ) 公司在语音行业可谓后发制人,其在2014年底正式推出了Echo智能音箱,并通过该音箱搭载的Alexa语音助理,为使用者提供种种应用服务。Echo 智能音箱一经推出,在消费市场上取得了巨大的成功,如今已成为美国使用最广的智能家居产品,至今累计销量已超过2000万台。投资机构摩根士丹利分析师称智能音箱是继iPad之后"最成功的消费电子产品"。
国内最早的语音识别研究开始于1958年,中国科学院声学所研究出一种电子管电路,该电子管可以识别10个元音。1973年,中国科学院声学所成为国内首个开始研究计算机语音识别的机构。受限于当时的研究条件,我国的语音识别研究在这个阶段一直进展缓慢。
改革放开以后,随着计算机应用技术和信号处理技术在我国的普及,越来越多的国内单位和机构具备了语音研究的成熟条件。而就在此时,外国的语音识别研究取得了较大的突破性进展,语音识别成为科技浪潮的前沿,得到了迅猛的发展,这推动了包括中科院声学所、中科院自动化所、清华大学、中国科技大学、哈尔滨工业大学、上海交通大学、西北工业大学、厦门大学等许多国内科研机构和高等院校投身到语音识别的相关研究当中。大多数的研究者将研究重点聚焦在语音识别基础理论研究和模型、算法的研究改进上。
1986年3月,我国的"863"计划正式启动。"863"计划即国家高技术研究发展计划,是我国的一项高科技发展计划。作为计算机系统和智能科学领域的一个重要分支,语音识别在该计划中被列为一个专项研究课题。随后,我国展开了系统性的针对语音识别技术的研究。因此,对于我国国内的语音识别行业来说,"863"计划是一个里程碑,它标志着我国的语音识别技术进入了一个崭新的发展阶段。但是由于研究起步晚、基础薄弱、硬件条件和计算能力有限,导致我国的语音识别研究在整个20世纪80年代都没有取得显著的学术成果,也没有开发出具有优良性能的识别系统。
20世纪90年代,我国的语音识别研究持续发展,开始逐渐地紧追国际领先水平。在"863"计划、国家科技攻关计划、国家自然科学基金的支持下,我国在中文语音识别技术方面取得了一系列研究成果。
21世纪初期,包括科大讯飞、中科信利、捷通华声等一批致力于语音应用的公司陆续在我国成立。语音识别龙头企业科大讯飞早在2010年,就推出了业界首个中文语音输入法,引领了移动互联网的语音应用。2010年以后,百度、腾讯、阿里巴巴等国内各大互联网公司相继组建语音研发团队,推出了各自的语音识别服务和产品。在此之后,国内语音识别的研究水平在之前建立的坚实基础上,取得了突飞猛进的进步。如今,基于云端深度学习算法和大数据的在线语音识别系统的识别率可以达到95%以上,科大讯飞、百度、阿里巴巴都提供了达到商业标准的语音识别服务,如语音输入法、语音搜索等应用,语音云用户达到了亿级规模。
人工智能和物联网的迅猛发展,使得人机交互方式发生重大变革,语音交互产品也越来越多。国内消费者接受语音产品也有一个过程,最开始的认知大部分是从苹果Siri开始。亚马逊的Echo音箱刚开始推出的两三年,国内的智能音箱市场还不温不火,不为消费者所接受,因此销量非常有限。但自2017年以来,智能家居逐渐普及,音箱市场开始火热,为抢占语音入口,阿里巴巴、百度、小米、华为等大公司纷纷推出了各自的智能音箱。据Canalys报告,2019年第1季度中国市场智能音箱出货量全球占比51%,首次超过美国,成为全球最大的智能音箱市场。据奥维云网 ( AVC ) 数据显示,2019年上半年中国智能音箱市场销量为1556万台,同比增长233%。
随着语音市场的扩大,国内涌现出一批具有强大竞争力的语音公司和研究团队,包括云知声、思必驰、出门问问、声智科技、北科瑞声、天聪智能等。他们推出的语音产品和解决方案主要针对特定场景,如车载导航、智能家居、医院的病历输入、智能客服、会议系统、证券柜台业务等,因为采用深度定制,识别效果和产品体验更佳,在市场上获得了不错的反响。针对智能硬件的离线识别,云知声和思必驰等公司还研发出专门的语音芯片,进一步降低功耗,提高产品的性价比。
在国内语音应用突飞猛进的同时,各大公司和研究团队纷纷在国际学术会议和期刊上发表研究成果。2015年,张仕良等人提出了前馈型序列记忆网络 ( feed-forward sequential memory network,FSMN ),在DNN 的隐层旁增加了一个“记忆模块”,这个记忆模块用来存储对判断当前语音帧有用的语音信号的历史信息和未来信息,并且只需等待有限长度的未来语音帧。随后,科大讯飞进一步提出了深度全序列卷积神经网络 ( DFCNN )。2018年,阿里巴巴改良并开源了语音识别模型DFSMN ( Deep FSMN )。2018年,中科院自动化所率先把Transformer应用到语音识别任务,并进一步拓展到中文语音识别。
不管是在研究成果还是在产品性能体验上,国内的语音行业整体水平已经达到甚至超越了国际尖端水平。2016年10月,时任百度首席科学家的吴恩达在对微软的语音识别技术与人类水平持平的消息表示祝贺的同时声称,百度的汉语语音识别在2015年就已经超越了人类的平均水平,也就是说百度比微软提前一年实现了这一成绩。2016年11月,搜狗、百度和科大讯飞三家公司相继召开了三场发布会,分别向外界展示了他们各自在语音识别等方面的最新进展。这三家公司几乎不约而同地宣布各自的中文语音识别准确率达到了97%,这充分说明大数据和深度神经网络的成功应用使得国内的语音识别技术取得了质的突破。
尽管如此,当前语音识别系统依然面临着不少应用挑战,其中包括以下主要问题:
鲁棒性。目前语音识别准确率超过人类水平主要还是在受限的场景下,比如在安静环境的情况下,而一旦加入干扰信号,尤其是环境噪声和人声干扰,性能往往会明显下降。因此,如何在复杂场景 ( 包括非平稳噪声、混响、远场 ) 下,提高语音识别的鲁棒性,研发"能用=>好用"的语音识别产品,提升用户体验,仍然是要重点解决的问题。
口语化。每个说话人的口音、语速和发声习惯都是不一样的,尤其是一些地区的口音 ( 如南方口音、山东重口音 ),会导致准确率急剧下降。还有电话场景和会议场景的语音识别,其中包含很多口语化表达,如闲聊式的对话,在这种情况下的识别效果也很不理想。因此语音识别系统需要提升自适应能力,以便更好地匹配个性化、口语化表达,排除这些因素对识别结果的影响,达到准确稳定的识别效果。
低资源。特定场景、方言识别还存在低资源问题。手机APP采集的是16kHz宽带语音,有大量的数据可以训练,因此识别效果很好,但特定场景如银行/证券柜台很多采用专门设备采集语音,保存的采样格式压缩比很高,跟一般的16kHz或8kHz语音不同,而相关的训练数据又很缺乏,因此识别效果会变得很差。低资源问题同样存在于方言识别,中国有七大方言区,包括官话方言 ( 又称北方方言 )、吴语、湘语、赣语、客家话、粤语、闽语 ( 闽南语 ),还有晋语、湘语等分支,要搜集各地数据 ( 包括文本语料 ) 相当困难。因此如何从高资源的声学模型和语言模型迁移到低资源的场景,减少数据搜集的代价,是很值得研究的方向。
语种混杂 ( code-switch )。在日常交流中,还可能存在语种混杂现象,如中英混杂 ( 尤其是城市白领 )、普通话与方言混杂,但商业机构在这方面的投入还不多,对于中英混杂语音一般仅能识别简单的英文词汇 ( 如"你家Wi-Fi密码是多少" ),因此如何有效提升多语种识别的准确率,也是当前语音识别技术面临的挑战之一。
语音识别建模方法主要分为模板匹配、统计模型和深度模型几种类型,以下分别介绍DTW、GMM-HMM、DNN-HMM和端到端模型。
1. DTW
当同一个人说同一个词时,往往会因为语速、语调等差异导致这个词的发音特征和时间长短各不相同,这样就造成通过采样得到的语音数据在时间轴上无法对齐的情况。如果时间序列无法对齐,那么传统的欧氏距离是无法有效地衡量出这两个序列间真实的相似性的。而DTW的提出就是为了解决这一问题,它是一种将两个不等长时间序列进行对齐并且衡量出这两个序列间相似性的有效方法。
如图 1-8 所示,DTW 采用动态规划的算法思想,通过时间弯折,实现P和Q两条语音的不等长匹配,将语音匹配相似度问题转换为最优路径问题。DTW是模板匹配法中的典型方法,非常适合用于小词汇量孤立词语音识别系统。但DTW过分依赖端点检测,不适合用于连续语音识别,DTW对特定人的识别效果较好。
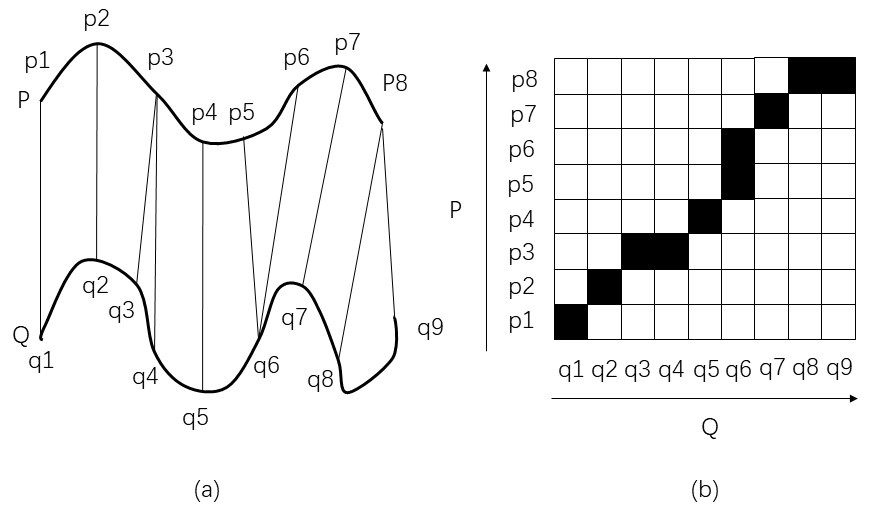
2. GMM-HMM
HMM是一种统计分析模型,它是在马尔可夫链的基础上发展起来的,用来描述双重随机过程。HMM有算法成熟、效率高、易于训练等优点,被广泛应用于语音识别、手写字识别和天气预报等多个领域,目前仍然是语音识别中的主流技术。
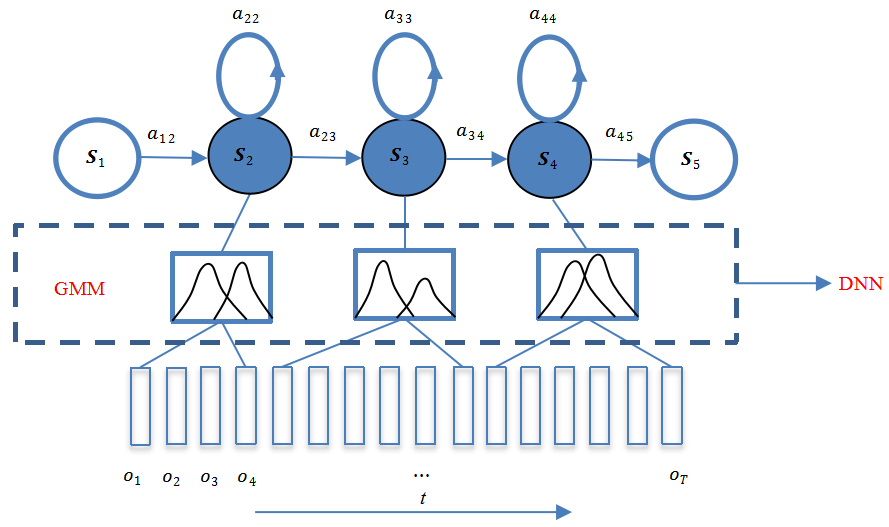
如图1-9所示,HMM包含S1、S2、S3、S4和S55个状态,每个状态对应多帧观察值,这些观察值是特征序列 ( o1、o2、o3、o4,...,oT ),沿时刻t递增,多样化而且不局限取值范围,因此其概率分布不是离散的,而是连续的。自然界中的很多信号可用高斯分布表示,包括语音信号。由于不同人发音会存在较大差异,具体表现是,每个状态对应的观察值序列呈现多样化,单纯用一个高斯函数来刻画其分布往往不够,因此更多的是采用多高斯组合的 GMM 来表征更复杂的分布。这种用 GMM 作为 HMM 状态产生观察值的概率密度函数 ( pdf ) 的模型就是GMM- HMM,如图1-9所示,每个状态对应的GMM由2个高斯函数组合而成。
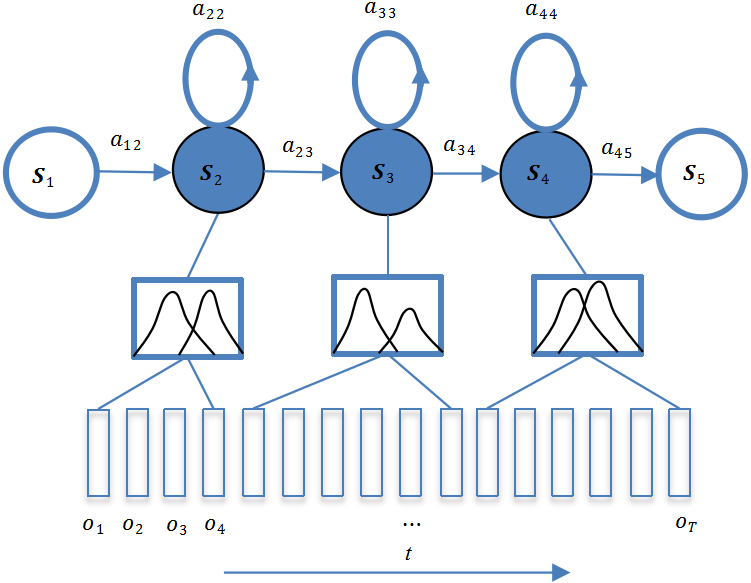
3. DNN-HMM
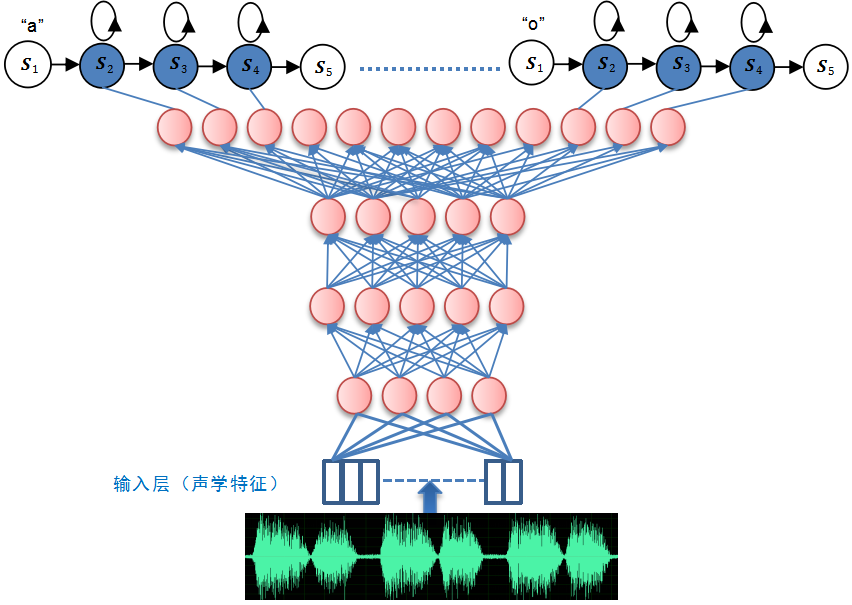
DNN拥有更强的表征能力,其能够对复杂的语音变化情况进行建模。把GMM-HMM的GMM用DNN替代,如图1-10所示,HMM的转移概率和初始状态概率保持不变。
DNN的输出节点与所有HMM ( 包括"a"、"o"等音素 ) 的发射状态一一对应 ( 如图1-11所示 ),因此可通过DNN的输出得到每个状态的观察值概率。
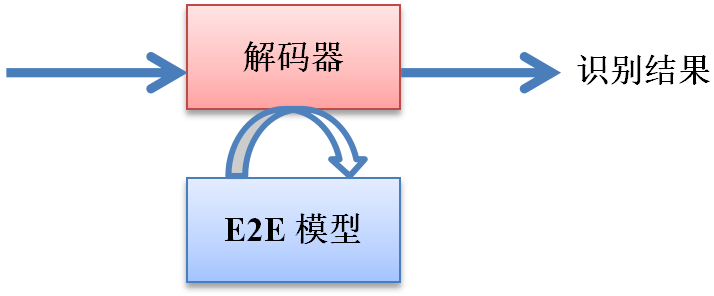
4. 端到端
从2015年,端到端模型开始流行,并被应用于语音识别领域。如图1-12所示,传统语音识别系统的发音词典、声学模型和语言模型三大组件被融合为一个E2E模型,直接实现输入语音到输出文本的转换,得到最终的识别结果。
HTK ( HMM Toolkit ) 是一个专门用于建立和处理HMM的实验工具包[10],由剑桥大学的Steve Young等人开发,非常适合GMM-HMM系统的搭建。2015年DNN-HMM推出,该新版本主要由张超博士开发。
Kaldi是一个开源的语音识别工具箱[20],它是基于C++编写的,可以在Windows和UNIX平台上编译,主要由Daniel Povey博士在维护。Kaldi适合DNN-HMM系统 ( 包括Chain模型 ) 的搭建,支持TDNN/TDNN-F等模型。其基于有限状态转换器 ( FST ) 进行训练和解码,可用于x-vector等声纹识别系统的搭建。
Espnet是一个端到端语音处理工具集[35],其侧重于端到端语音识别和语音合成。Espnet是使用Python开发的,它将Chainer和Pytorch作为主要的深度学习引擎,并遵循Kaldi风格的数据处理方式,为语音识别和其他语音处理实验提供完整的设置,支持CTC/Attention等模型。
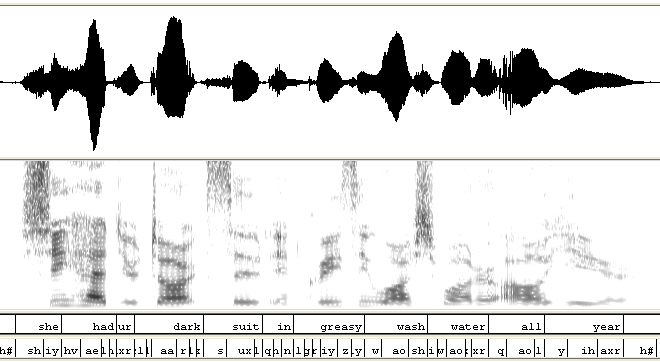
TIMIT——经典的英文语音识别库,其中包含,来自美国8个主要口音地区的630人的语音,每人10句,并包括词和音素级的标注。图1-13给出了一条语音的波形图、语谱图和标注。这个库主要用来测试音素识别任务。
SwitchBoard——对话式电话语音库,采样率为8 kHz,包含来自美国各个地区543人的2400条通话录音。研究人员用这个数据库做语音识别测试已有20多年的历史。
LibriSpeech——免费的英文语音识别数据库,总共1000小时,采样率为16kHz,包含朗读式语音和对应的文本。
Thchs-30——清华大学提供的一个中文示例,并配套完整的发音词典,其数据集有30小时,采样率为16 kHz。
AISHELL-1——希尔贝壳开源的 178 小时中文普通话数据,采样率为16kHz。包含400位来自中国不同口音地区的发音人的语音,语料内容涵盖财经、科技、体育、娱乐、时事新闻等。
语音识别数据库还有很多,包括16kHz和8kHz的数据。海天瑞声、数据堂等数据库公司提供大量的商用数据库,可用于工业产品的开发。
假设"我们明天去动物园"的语音识别结果如下:

识别结果包含了删除、插入和替换错误。
度量语音识别性能的指标有许多个,通常使用测试集上的词错误率 ( Word Error Rate,WER ) 来判断整个系统的性能,其公式定义如下:
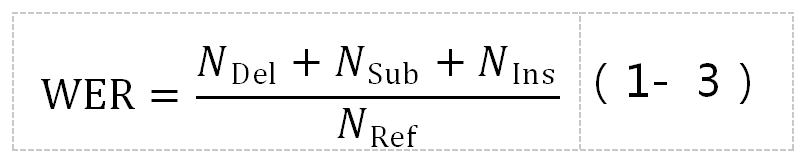
其中,NRef表示测试集所有的词数量,NDel表示识别结果相对于实际标注发生删除错误的词数量,NSub代表发生替换错误的词数量,而NIns则表示发生插入错误的词数量。
针对中文普通话,评价指标也经常采用字错误率 ( CER ),即用单字而不是词来计算错误率。
作者介绍:
洪青阳,厦门大学副教授,天聪智能创始人,主要研究方向是语音识别、声纹识别,先后主持国家自然基金两项,科技部创新基金两项。牵头组建厦门大学智能语音实验室,带领xmuspeech团队连续两届获东方语种识别 ( OLR ) 竞赛第一名,成功研发国内第一套闽南语合成系统。具有丰富的工业界研发经验,与华为、云从、掌数科技等知名企业合作,承担过大量的智能语音项目,核心技术应用到华为智能手机和全国十五个省市的司法/社保/证券/电力系统。长期从事本科生、研究生的语音识别教学工作,从动态时间规整 ( DTW )、隐马尔可夫模型 ( HMM ) 到E2E语音识别框架,与时俱进更新教学内容,积累了丰富的教学经验。
在文末分享、点赞、在看,给个三连击呗~~

本书特色:解析GMM-HMM、DNN-HMM和E2E框架,WFST和LF-MMI等关键技术全貌;系统梳理经典算法、前沿技术;工程实践Kaldi和Espnet。
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,7万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇




