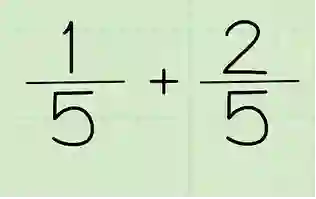![]()
本文约6113字,建议阅读10分钟
本文介绍了科大讯飞在计算机视觉领域发展中
的探索、沉淀、全面爆发。
![]()
人工智能技术从开始到真实产生应用的突破是以时间为代价的。需要无数的科学家带着甘做冷板凳的决心潜心钻研,一坐就是十年、二十年。
从1956年Dartmouth会议上第一次提出人工智能的概念到2006年深度学习概念首次问世,神经网络从诞生到真正意义上拥有了深度,经过了超50年的时间。
随着大数据和算力发展的助推,深度学习爆发出巨大的威力,一轮又一轮的研究热点在各项领域开花结果,全社会都热血澎湃地张望未来。
2010年,人类尝试复刻人脑聆听和处理人类语音的方式,DNN(深度神经网络)在语音识别方面出现革命性的突破。2012年,CNN(卷积神经网络)在图像识别上大获成功。至此,人工智能多项技术到达真正意义上“可用”的阶段。
从技术转向产业,2010年前后同样是个值得书写的年份:移动互联网时代来到发展的沸腾临界点,BAT格局已然成形,而后被无数资本追捧的AI四小龙,也都在2010年后相继成立。
而彼时,殷保才和吴嘉嘉还是两名就读人工智能相关专业的学生,在代码、公式和论文交错的实验室里,痴迷地探索着计算机视觉领域里一切可能的方向。
从校招入职,到如今成为科大讯飞AI研究院计算机视觉方向(CV)的领跑者,吴嘉嘉正带领着团队攻克图文识别领域内喜马拉雅山式的挑战——篇章级公式识别,并不断将技术扩展到更加复杂和深入的应用场景;殷保才牵头视觉领域的最前瞻技术探索,从视觉交互、遥感图像到多模态感知、3D感知,用自由的眼光看更远的未来。
因名字中的“才”和“嘉”,在科大讯飞研究院里,大家都津津乐道地称他们为“才”子“嘉”人。和他们一起的,是科大讯飞超百人规模的计算机视觉团队的研究员们,带领着科大讯飞计算机视觉多项技术保持着国际领先水平。
后来被问到,为什么在那个计算机视觉领域风起云涌的时代选择加入一家以人工智能“语音”技术而闻名的公司时,他们都给出了相似的答案:“发挥自己的作用,让科大讯飞的计算机视觉技术也达到国际领先水平。”
如今,从国际医学影像领域权威评测LUNA上刷新世界纪录、在计算机视觉顶级会议CVPR 2019和文档分析与识别顶级会议ICDAR 2019上的多项评测任务中获得冠军、到刷新目前公认自动驾驶领域内最具权威性的图像语义分割评测集Cityscapes全部两项子任务的世界纪录,无一不在向世界宣示着,科大讯飞早已不是那个只做“语音”的公司了。
而这一切的背后,是这群对技术无比热爱之人的初心坚守。
因为从小就是典型的理科生,殷保才自觉对文字表达不感兴趣,思维比较发散,难以集中注意力,连小说都读不进去。在他的大脑里,似乎只有数学符号和图像是可理解的,“算是一种空间型思维吧”。
就连在职期间继续攻读中科大的博士学位也是院长费了好大力气劝说后才去的,因为“就是不想写论文”。
同样,在与吴嘉嘉交流的过程中,我们也发
现了类似的特点。
只要我们说出文本行识别、公式识别这些词,他立马会连珠炮弹般把整个技术链路里里外外介绍一遍,尽管我们当时问的是“这项技术背后有什么故事?”。多次提醒后,他依然沉浸在分享这些细节中。这些精微的技术细节,仿佛才是他眼中的事件记忆。
“不想写论文”、“不会讲故事”的他们痴迷于技术本身。在他们的思维里,故事不是被抹杀了,而是在一个抽象空间里,将所有的累积汇聚成一体。在思维成形之前,空间里只有无逻辑关联的碎片。一旦关键的碎片找到后,思维成形,便是“灵感爆发”时刻。
尽管都是空间型思维,但这对“才”子“嘉”人也有着不同的思维习惯。
殷保才偏好直觉,比如在带领团队参加LUNA比赛时,创新性地采用了3D框架,“几乎是一瞬间就想到了。”
吴嘉嘉则偏好逻辑,比如在解释技术的时候,每一次都像是在发送逻辑缜密的文档,还是当场生成的。
接下来,就让我们深入科大讯飞这对计算机视觉领域“才”子“嘉”人的更多亲身经历,一探科大讯飞计算机视觉技术之究竟。
或许是语音的标签太过耀眼,科大讯飞在计算机视觉方向上的发展并不为外界所熟知。
2008年以前,科大讯飞的技术储备还是集中在与语音相关的技术方向上,从语音合成、语音评测到语音识别技术,科大讯飞在全球语音技术领域内已是全面领先地位。
而2008年,几位探索计算机视觉领域内图文识别(OCR)技术方向的研究员们已默默的开始了漫长的征程。从探索、沉淀、到全面爆发,一等就是十年。
“OCR一开始在研究院是一个很小的方向。当时很多人不理解,大家觉得OCR就是识别字符,落地的场景就是类似街边的街景字符的识别。回头来看,随着信息化时代的到来,
OCR应用的场景非常广泛,带来的社会价值是巨大的
。”吴嘉嘉说道。
比如在教育领域,差不多也就在2013、2014年左右,我们非常清楚地看到了人工智能在教育里应用的潜力,从智能阅卷、评分测评、到现在“因材施教”的个性化教育,OCR技术几乎是所有教育应用的入口。
“OCR技术一定要结合实际场景的需求,定义OCR技术问题也必须来自于实际场景的重大刚需问题,只做技术是不行的,这也是人工智能落地里科大讯飞探索出来的方法论。”
2014年,吴嘉嘉开始攻关文本行识别技术,在此之前,吴嘉嘉已率先尝试用深度学习的CNN技术来做孤立字识别,识别精度相对基线版本大幅提升了30%,并在讯飞输入法上得到了很好的落地。
但后来他发现,孤立字识别技术根本不适应文本行识别问题,文本行识别的一个常规思路是首先对字符进行切分,然后进行单字符识别。由于涉及手写字体,很多人写字会习惯性地连笔,这就让切分变得困难了。
在投入语音识别技术的时候,很少有人能想到语音识别技术的逻辑和方式能够被同为模式识别分支的字符识别所借鉴。
语音技术深厚的积累给团队带来了无尽的宝藏,在文本行识别的研究中,他们找到了融合的契机——语音识别要将连续的波形转化出分离的字符,而波形和手写字类似,也是无法拆分的。
AI研究院的小伙伴们快速完成了语音识别到计算机视觉之间的算法框架迁移和借鉴,将语音识别中的HMM模型框架引入到文本行识别,精度大幅提升。
吴嘉嘉开始形成自己的方法论——他山之石,可以攻玉。
技术的进步常比想象中走得更快,而在发展之前,则是默默耕耘与长期投入。
在OCR生根发芽之际,科大讯飞又开启了计算机视觉领域其他技术方向探索的征程,从人脸识别、医学影像到辅助驾驶、虚拟形象。
科大讯飞对于新方向的探索
多是从参与国际顶尖比赛开始的,探索技术的可达性
。
2016年,人工智能+医疗概念逐步兴起,作为医疗影像领域最具代表性、最受关注的国际测评任务之一,LUNA(LUng Nodule Analysis)测评吸引了大批国内外学术界和产业界的团队参与。但 LUNA任务的难度系数极高,核心原因在于肺结节检测输入的信息量巨大,而目标非常小。
几乎所有参赛团队都采用了2D或2.5D的解决方案,其中2D方案就是只处理单张影像;2.5D则是通过纵向、斜向地对整个影像序列切割出2D数据,再进行处理。
“但这些方案都不可避免导致原始信息的丢失,必须用3D模型。”
因为LUNA所要处理的数据是3D数据。所谓3D数据,即CT影像是一个数百张影像的集合,每一张通过扫描身体部位的一个断层得到。所谓3D框架,指的是其专门用于处理3D形式的数据。在竞争榜单上,殷保才是少有的熟知尚不成熟的3D图像识别技术的人。
不难看出,这种解决方案简单直接,与问题本身天然匹配。
在这场比赛中,殷保才团队开发的框架最终获得了94.1%的召回率(召回率高意味着对阳性患者的漏诊率低),这一成绩也刷新了当时的榜单世界纪录。
“才子”的这种源源不断的直觉,其实离不开长期的技术积累沉淀。
吴嘉嘉团队此时已解决了文本行识别,正在为突破公式识别而努力。传统文本行识别都是非常定式的从左到右、从上到下的识别顺序,模式比较单一。而公式会有各种嵌套结构、左右上下的杂糅。
分数加法算式就是一个左右上下混合的简单例子,比如1/5是一个上下结构,1/5+2/5又是一个左右结构。
嵌套结构则包括指数、连根式、连分式等等,“这种式子没有最复杂,只有更复杂,比如连分式可以是无穷嵌套的。”
比起文本行识别,问题难度又上升了一阶。团队在起初用了很多传统方法去做结构的分析。比如在两个分数的加法中,先将字符单独识别出来,再分析字符间的空间关系等等,“一般就是多阶段模型,最后会变成非常复杂的系统工程,泛化性也不好。”
后来源于科大讯飞研究院在机器翻译上的技术积累,他们发现公式识别任务和机器翻译任务很像,因此可以把基于注意力机制的Encoder-Decoder模型运用到公式识别上来。
在语音识别技术和自然语言理解技术领域所使用的序列建模和神经网络中的注意力机制,成为OCR技术“灵感的缪斯”。进一步地,团队联合NELSLIP基于Encoder-Decoder模型构建了新的无切分公式识别算法。
不到一年的时间,吴嘉嘉团队在公式识别上已经达到了96%的准确率。
随后,在国际顶级手写公式识别挑战赛中,团队先后获得2019年ICDAAR CROHME、2020年ICFHR OffRaSHME多个国际冠军。
同样地,在OCR技术应用在教育领域的过程中,这对“才”子“嘉”人也发现
图文分析任务与其他计算机视觉任务的一致性
,殷保才基于早期在计算机视觉任务上的积累,很快将多种技术方案应用到了文档图像处理及版面分析任务中。
现在这对“才”子“嘉”人也正在
联手打造全链路的图文识别技术,实现Read Anything的目标
。
OCR的不断突破,来自于技术间的跨领域创新式与交汇融合式的思想迁移。而人工智能助力行业的发展,则来源于厚积薄发式的积累和沉淀。
2020年疫情爆发初期,殷保才接到了紧急通知,要针对新冠疫情开发医疗辅助系统,帮助医生诊断肺炎症状。
疫情期间影像科医生的压力是巨大的。每诊断一个病例,影像科医生需要对CT的数百张切片逐层分析,需要大约为5至15分钟时间。而针对新冠确诊患者,医生还需要回顾患者历史影像,阅片量至少再翻一倍。
三天后,第一个版本的系统正式上线。之后一个月,殷保才团队每天都会将系统更新一个版本。通过系统可在3秒内完成一例病例辅助诊断,极大提高了医生工作效率,也有效降低漏诊误诊。
与时间赛跑,与病毒较量,殷保才团队也充分发挥技术优势,为疫情防控贡献科技力量。
但突发式攻关的背后,殷保才直觉的来源,是
多年的经验与知识的积累,是那段少有人知的刻苦经历
。
曾为落地胸科诊断技术,殷保才多次登门拜访向专业医生寻求数据标注的建议。“结合专业知识在AI医疗影像中是非常关键的部分,耗费成本也很高。同时,3D数据标注更为复杂,不同医生的标注也有方差。”奈何医生太忙,每次只落下零星几句话,然后甩给他一本上千页的胸科诊断指南。
殷保才只能自学医疗知识,开始探索这条少有人走的路,“不仅数据少,现有的代码也少。”如今,他早已成为了人工智能领域里的半个医学专家。
无论是交汇融合式的思想迁移,还是厚积薄发式的灵感闪现,殷保才和吴嘉嘉都在一步一个脚印,在正确的方向长期投入和无悔坚持。
这份热爱,既源于他们自身,也在科大讯飞AI研究院的支撑下,源源不绝。
科大讯飞AI研究院分为计算机视觉、认知、语音三个大方向,"但在这里,你可以随意和任何一个方向的人聊技术,每个人都很乐于分享,只要你够主动。"
“我们内部有很多基于深度学习为主的研究方向,这些不同的领域之间可借鉴性很强,不同方向之间互相借鉴然后做一些跨领域、融合式的创新是我们AI研究院所擅长的。”殷保才说道。“比如我们首席科学家魏思在多年前就发起了'王牌飞行员'计划,加强不同团队的沟通交流,促进内部的信息交流和技术迁移应用,当然也为了培养一批批的'科学家'。”
研究院简单真诚的氛围"就和在学校里差不多,大家都非常纯粹。"
这份纯粹让他们自由而一往无前,技术水平更具前瞻性,使得公司不受外界干扰而保持战略的定力。
科大讯飞AI研究院首席科学家魏思曾经说过,"
在整个工业界里去做研究这一块的工作,科大讯飞AI研究院不输于世界上任何一家研究机构
。"
他们也并不害怕承认——研究院并不对发论文有狂热的偏爱。
殷保才说道,"在我们看来,
技术核心在于能不能为社会真正创造价值,能否立足场景解决刚需问题
。"
西方国家点燃了深度学习的火炬,但最大的受益者将会是中国,这种全球性的变化是由两方面的转变引起的:从发明的年代转变为实干的年代;从专家的年代转变为数据的年代。
此外,一位ACM高级科学家曾经告诉我们,现在AI学界研究的风气大变,灌水现象也特别严重,"将从学界拿到的论文用于技术落地时,对其结论首先都要打一个问号。"
业界做AI学术被质疑理论不够扎实,学界在缺少资源的情况下,亦难以研究大规模的问题。或许两者汇集之后我们才能提出更好的基础研究问题。
"我们也发现了一个现象:在企业研究院发论文对于学生而言很有吸引力,能为他们的简历增光。但这个现象持续下去,是否对整个行业有促进作用,值得探讨。"殷保才补充道。
企业研究不仅需要在技术水平上"顶天",又要在技术价值上"立地"。这其实也正是科大讯飞AI研究院一直秉承的价值观——顶天立地。
在资源投入上,科大讯飞以市场导向分配"弹药",遵循"
721研发投入模式
"。
"我们每年拿出20%以上的营收投入到研发中,其中70%的资源投入当前的主导产品,20%投入战略新产品,10%投入探索型的、不追求一定要有回报的方向,它可以很自由地探索未来。”而殷保才主要就在负责2和1的部分。
指尖交互、手势交互、多模态识别、遥感方向、智慧畜牧等都是他将投入的方向
。
"视觉前瞻的每一个尝试,基于我们的业务需求、未来趋势判断以及扩展研究院的能力建设,但最终都是为了能够拓宽整个视觉领域的应用边界。"殷保才补充道。
吴嘉嘉则将继续深耕OCR,打通OCR技术链路。在整个职业生涯中,吴嘉嘉前三、四年聚焦于钻研技术,带团队之后,开始思考整个技术链路的问题。
从孤立字识别到文本行识别,是从1到10的阶段跨越;而从文本行识别到公式识别,则是从10到100的飞跃。
如今,团队正在攻关一个“300”难度的任务——篇章级公式识别,"当然,说不定是1000。"
从孤立字识别、文本行识别、公式识别到篇章级识别,是一场从点到线到面再到网络的升维进化,科大讯飞亦在OCR领域建立起了较高的技术壁垒。在实际应用中,以教育为例,学生作业试卷文档存在版面结构复杂、书写风格差异显著等难点问题也变得可解。
如今作为OCR条线的负责人,面对团队日渐增长的团队规模,他也有了新的梦想,“保持核心技术的领先水平,屹立于世界的前沿。同时让人工智能技术应用到更多的领域内,让科技所带来的改变惠及大众。”
这对“才”子“嘉”人在科大讯飞的成长故事,也是科大讯飞不断扩展的缩影。
专注AI多年的科大讯飞,自身已成一个神经网络——很宽、很深的生成式神经网络。
一个典型的生成式神经网络包括了输入层、编码层、输出层。对于一个AI企业而言,输入是AI三要素:算力、数据、算法,输出是技术和产品,编码层则是企业的组织方式和技术方法论,以及企业的人才。
各个节点并非孤立,紧密链接,由此在“技术顶天”与“应用落地”这一天地两端,用人工智能建设美好世界。