这是一本正在写作的新书,目前前四章已经放出了草稿。
过去几年,GPT-3 等几个大模型展示了大数据、大算力的力量,它们的效果毋庸置疑,但在现实世界中训练和部署这些模型是非常昂贵的,这阻碍了大模型在现实世界中的广泛应用,比如很多效果很好的大模型根本无法在手机上运行。因此,我们需要想办法把模型做得更加高效(在尽量不损失性能的前提下把模型做得更小)。
为了解答这个问题,谷歌机器学习工程师 Gaurav Menghani 和独立研究者 Naresh Singh 正在撰写一本新书。这本书将涵盖谷歌研究院、Facebook AI 研究院(FAIR,现 Meta AI)及其他著名人工智能实验室的研究员和工程师在各种设备(从大型服务器到小型控制器)上训练和部署模型时所使用的算法和技术,如量化、剪枝、蒸馏等。
![]()
第一章是
对全书内容的整体概括
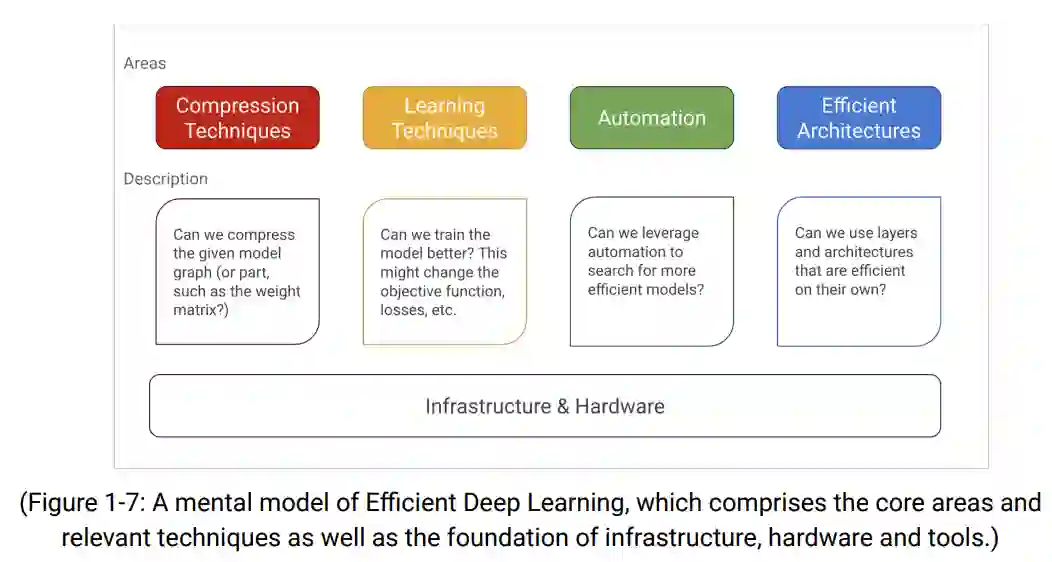
。作者首先概述了深度学习的现状、应用和快速增长,然后探讨了提高模型效率的动机及相关核心技术,包括压缩技术、学习技术、自动化、高效模型 & 层、基础设施等。
![]()
![]()
第二章
围绕压缩技术展开
。压缩技术旨在减少模型占用空间(大小、延迟、内存等)。我们可以通过减少可训练参数的数量来减少模型的占用。然而,这种方法有两个缺点。首先,我们很难确定在不显著影响性能的情况下可以删除哪些参数或层。如果可能的话,我们需要进行许多试验和评估才能得到一个更小的模型。其次,这种方法不能很好地泛化,因为模型设计是针对具体问题的主观设计。
在这一章,作者介绍了能够解决上述两个问题的模型压缩技术 —— 量化。首先,他们介绍了压缩的概念,然后是量化的细节及其在深度学习中的应用,最后是代码实现细节以及实践项目。
![]()
模型质量是评价深度学习模型性能的重要基准。例如,使用低质量模型的语言翻译应用将很难被用户接受,因为它无法帮助用户与说不同语言的人有效交流。第三章的重点将放在能够帮我们实现质量目标的技术上。在移动和边缘设备等空间受限的环境中,高质量模型具有额外的优势,它们可以灵活地牺牲一些质量来减少空间占用。
在第一章,作者简要介绍了能够提高质量的学习技术,如正则化、dropout、数据增强和蒸馏。这些技术可以提高准确度、精确度和召回率等指标,这些都是我们在考虑质量问题时重点关心的指标。在第三章,作者选择了上述技术中的两种进行介绍,即
数据增强和蒸馏
。这是因为,首先,正则化和 dropout 在任何现代深度学习框架中都是相当直接的;其次,数据增强和蒸馏可以在训练阶段带来显著的效率增益,这是本章的重点。
![]()
截止到第三章,作者已经讨论了与模型架构无关的通用技术。这些技术可以应用于自然语言处理、视觉、语音或其他领域。然而,由于其增量性质,它们提供的收益非常有限。此时,尝试另一种更适合该任务的架构收获可能更大。打个比方,在改善房子采光的时候,你可以把墙壁重新刷成鲜艳的颜色,或者升级到更强的灯具。然而,如果在结构上做些改变,比如增加几扇窗户和一个阳台,采光效果会很好。类似地,为了在占用空间或质量方面获得数量级的增益,我们应该考虑采用合适的高效架构。
深度学习的进展是架构上的突破所驱动的,这些突破可以降本增效。多层感知机的发展是神经网络领域最大的架构突破之一。它引入了堆叠层来学习复杂关系。卷积神经网络是另一个重要的突破,它能够在输入中学习空间特征。循环神经网络有利于从序列和时间数据中学习。这些突破促成了越来越大的模型。虽然它们提高了解决方案的质量,但是更大的模型带来了部署挑战。一个不能在实际应用中部署的模型用途是有限的。
高效的架构旨在通过提出新的方法来减少模型空间占用并提高推理效率,同时保留大模型的问题解决能力,从而提高模型的可部署性。在第一章,作者简要介绍了
depthwise 可分离卷积、注意力机制和 hashing trick 等架构
。在第四章中,作者将深入研究它们的架构,并使用它们将大型复杂模型转换为能够在移动和边缘设备上运行的小型高效模型。他们还使用这些高效的层和架构建立了几个编程项目,以获得实际的模型优化体验。
![]()
至于第四章之后的内容,我们目前只能看到目录,相信作者也会很快上传 PDF 草稿,大家可以持续关注该书官网。
![]()
![]()
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com