Gary Marcus又来「整顿」AI圈:LeCun不可信,Nature审稿人没用脑子
选自garymarcus.substack
Gary Marcus 和 Yann LeCun 等人的一系列辩论能否让「AI 的未来何去何从」这一命题越辩越明?

这个周末刚过,我们再次看到了 Gary Marcus 对 AI 圈的最新「整顿」成果。

「四天内关于人工智能和机器学习的三个令人费解的说法、顶级期刊的统计错误,以及 Yann LeCun 的一些说法,你都不应该相信。」
以下是 Gary Marcus 的原文内容:
一些事情即将发生。当《纽约时报》说一场革命即将到来,但事实上并没有发生时,我从不感到惊讶。这种情况已经持续了很长一段时间(实际上是几十年)。
比如,想想 2011 年时 John Markoff 是如何展望 IBM Watson 的。
「对 I.B.M. 来说,这场较量不仅是一场广为人知的宣传和 100 万美元的奖励,还证明了该公司已经朝着一个智能机器能够理解并对人类做出反应,甚至可能不可避免地取代人类的世界迈出了一大步。」
但 11 年之后的今天,John Markoff 所描述的愿景并没有发生。人们仍然缺乏对人工智能的理解,真正被 AI 取代的工作也是极少数。我所知道的每一辆卡车仍然在由人类驾驶(除了一些在受限场景下进行测试的卡车),目前还没有放射科医生被取代。Watson 本身近期也在被拆分出售。
《纽约时报》在 1958 年首次表示,神经网络即将解决人工智能问题。当然,预测 AI 并不是《纽约时报》的强项。

但在过去的几天里,我看到一大堆严肃的研究人员也在提出类似的过度兴奋的主张,他们本应该更了解这个领域的情况。
第一个例子来自斯坦福大学经济学家 Erik Brynjolfsson,是三个例子中最不令人反感的一个,但仍有些过头。

我看过很多种不同类型的狭义智能,一些智能在它们特定的领域能超越人类。人类智能(可能)比目前所有其他智能都更加广泛,但仍然只是智能空间中一个非常狭窄的部分。
Brynjolfsson 认为,人类智能是所有可能的智能空间中非常狭窄的一部分(这是乔姆斯基在我出生前就针对人类语言提出的观点),这个看法完全正确。毫无疑问,比我们更聪明的智能是有可能存在的,而且还可能实现。
但是,且慢——他帖子里的 「probably」是怎么回事呢?他甚至把它放到了括号里。
任何一个正常的 5 岁孩子都可以用他们几年前或多或少从零学到的母语进行对话、爬上一个不熟悉的攀爬架、看懂一部新卡通的情节或口头掌握一个新卡片游戏的规则,而不需要进行成千上万次的尝试。人类孩童在不断地学习新事物,而且通常是从少量的数据中学习。在人工智能的世界里,没有任何东西可以与之相比。
他在帖子里加一个「probably」,就好像我们认为,在人工智能的世界里,人类通用智能存在一个有潜力的竞争对手。事实上并没有。这就好像我说「塞雷娜 · 威廉姆斯可能(could probably)会打败我」一样。
与此同时,Yann LeCun 发布了一系列令人费解的推文,声称他发明的 ConvNet(或其他什么东西)可以解决几乎所有问题,这不是真的,而且从表面上看与他自己几周前告诉 ZDNet 的相矛盾。但是等等,还有更糟的。LeCun 继续写了下面的话,这真的让我摸不着头脑:
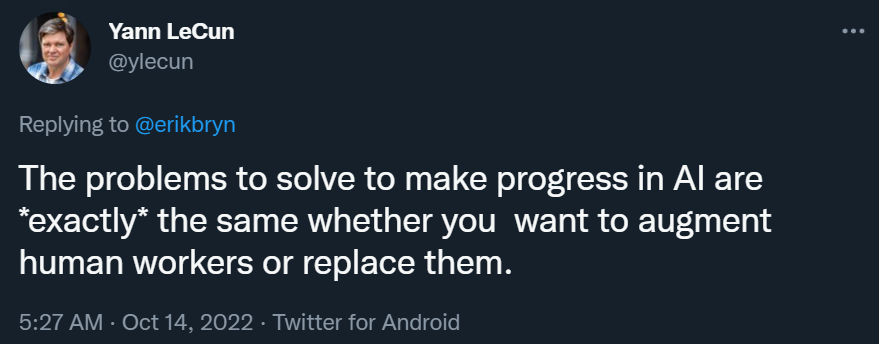
无论你是想增强人力还是取代人力,在 AI 领域取得进展所要解决的问题都是「完全」相同的。
我不同意他的看法。增强人的能力要简单得多,因为你不需要把整个问题都解决掉。计算器可以增强会计的能力,但它不知道哪些钱是可扣除的,也不知道税法中哪里可能存在漏洞。我们知道如何建造能做数学运算的机器(增强),但不知道如何制造能够阅读税法代码的机器(取代)。
我们再来看看放射学:
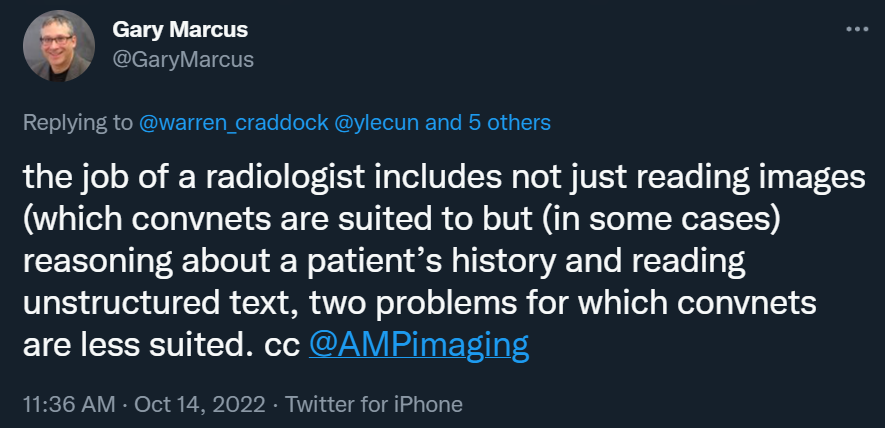
放射科医师的工作不仅包括阅读图像(卷积网络适用),而且(在某些情况下)包括推理患者的病史以及阅读非结构化文本,这两个问题卷积网络就不太适用了。
医疗 AI 领域以压倒性多数和一致的方式支持我的论点:
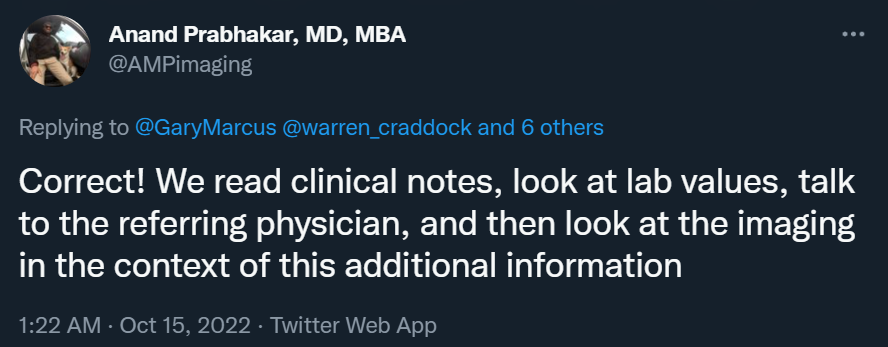
说得对!我们会阅读临床记录、查看 lab value、与转诊医生交流,然后在这些附加信息的背景下查看成像结果。
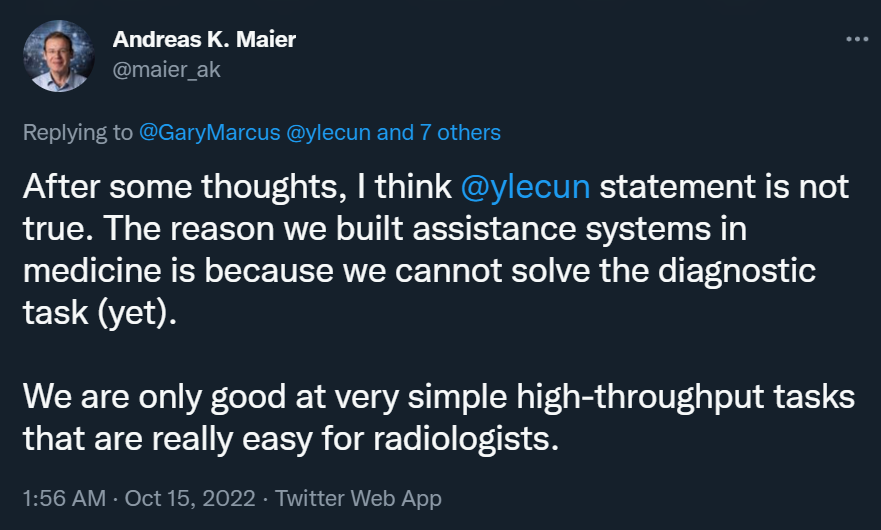
经过一番思考,我们认为 LeCun 的说法不正确。我们在医学上建立辅助系统的原因是我们还无法解决诊断任务。我们只擅长非常简单的高通量任务,而这些任务对放射科医生来说真的很容易。
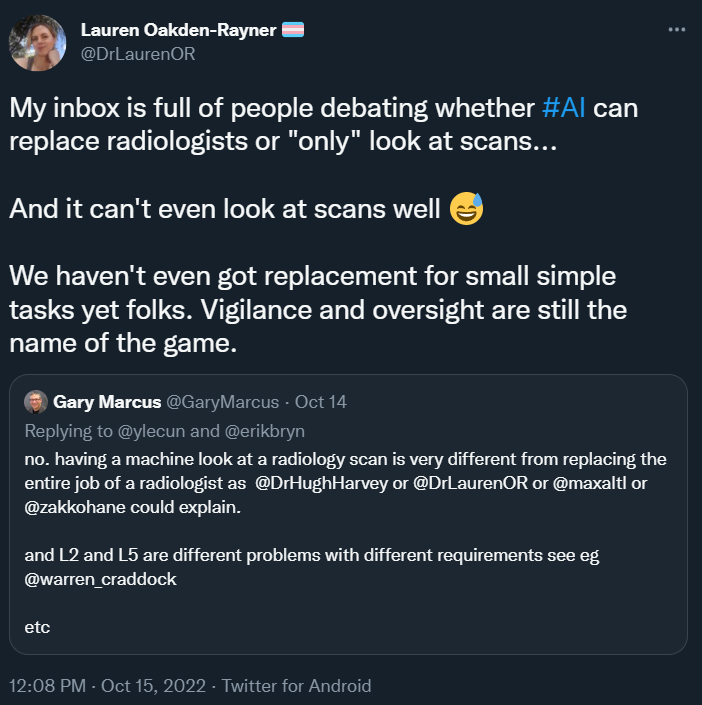
我的收件箱里全都是争论「AI 是否可以取代放射科医生?还是只能看扫描结果」的内容,然而 AI 甚至还不能很好地看懂影像……
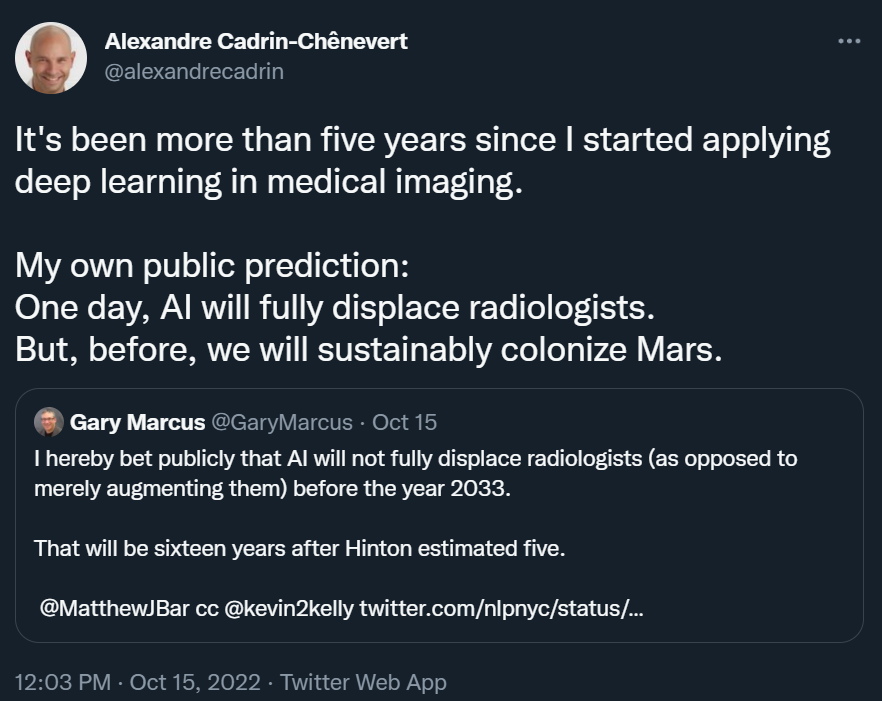
我已经在医学成像中用了五年的深度学习。我自己的公开预测是:有朝一日,人工智能将完全取代放射科医生。但是在此之前,我们将先实现移民火星的梦想。
人工智能可以解决放射学某些方面的问题,但这并不意味着它可以解决所有方面的任何问题。
正如 Una Health 联合创始人兼首席医疗官 Matthew Fenech 所说:「主张在一段不长的时间里取代放射科医生是从根本上误解了他们的角色。」
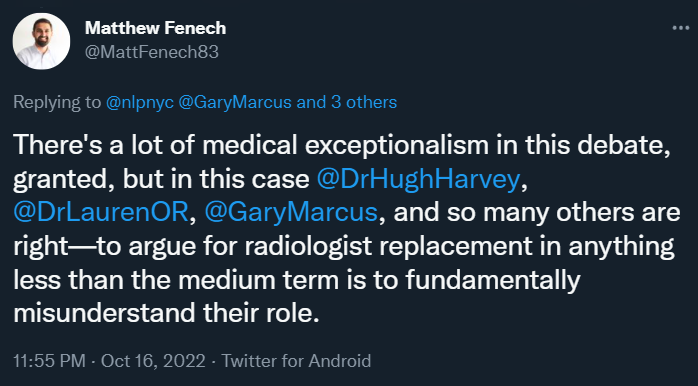
但这些只是即兴的推文。也许我们可以原谅他们仓促的表达。但更令我惊讶的是,《自然》杂志的一篇关于语言神经科学的文章中出现了大量有利于深度学习的统计错误。
这篇文章(《Deep language algorithms predict semantic comprehension from brain activity(深度语言算法通过大脑活动预测语义理解)》)由一些 MetaAI 的研究人员撰写:

表面上看,这个结果对于深度学习爱好者来说是个好消息,揭示了深度学习和人脑之间的相关性。该研究的主要作者在推特上的同一系列帖子中声称,GPT-2 的「内部工作」与人类大脑之间存在「直接联系」:

但细节很重要;我们看到的只是一种相关性,观察到的相关性是良好的,但不是决定性的,R = 0.50。
这足够发表文章了,但也意味着还有很多未知的地方。当两个变量像这般相关时,并不意味着 A 导致 B(反之亦然)。这甚至不意味着他们步调一致。它类似于身高和体重之间的相关性的大小:如果我只知道你的身高,而对你一无所知,我可以对你的体重做出一个稍微有根据的猜测——可能很接近,但也可能相去甚远,这些都是无法保证的。
这篇论文本身解决了这个问题,但是当它这样做时,它犯了一个大错,再次将太多结果归因于深度学习。他们是这样说的:(了解自己统计数据的人可能会立即发现错误)。

正如 Stats 101 告诉我们的,所解释的变化量不是 R,而是 R 的平方。因此,如果你有 R = 0.5 的相关性,实际上「解释」的(实际上只是「预测」)只有 25 % 的方差——这意味着四分之三(而不是一半)的可变性仍未得到解释。这是一个巨大的差异。(在一则私信中,我向作者 King 指出了错误,他和我意见一致,并承诺他会联系期刊进行更正。)
预测仅 25% 的方差意味着允许进行「推测」,但这肯定不意味着你已经确定了答案。最后,我们真正拥有的证据只是表明,对 GPT 很重要的东西对大脑也很重要(例如频率和复杂性)。但我们还不能说,两个弱相关的东西实际上在以相同的方式运作。
现在事情就是这样。但《自然》杂志的同行评审并没有注意到这个点,这让我感到震惊。它告诉我的是人们喜欢这个故事,却并没有仔细阅读。(仔细阅读是同行评审员的首要工作。)
当审稿人喜欢这个故事但没有批判性地阅读时,这表明他们是用心投票,而不是用大脑投票。
原文链接:https://garymarcus.substack.com/p/too-much-benefit-of-the-doubt?utm_source=twitter&sd=pf
扩展阅读:
Gary Marcus 公开喊话 Hinton、马斯克:深度学习就是撞墙了,我赌十万美金
终于,Yann LeCun 发文驳斥 Gary Marcus:别把一时的困难当撞墙
深度学习十年后是撞墙了吗?Hinton、LeCun、李飞飞可不这么认为

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



