CVPR 2019轨迹预测竞赛冠军方法总结

总第365篇
2019年 第43篇

背景
CVPR 2019 是机器视觉方向最重要的学术会议,本届大会共吸引了来自全世界各地共计 5160 篇论文,共接收 1294 篇论文,投稿数量和接受数量都创下了历史新高,其中与自动驾驶相关的论文、项目和展商也是扎堆亮相,成为本次会议的“新宠”。

障碍物轨迹预测挑战赛(Trajectory Prediction Challenge)隶属于CVPR 2019 Workshop on Autonomous Driving — Beyond Single Frame Perception(自动驾驶研讨会),由百度研究院机器人与自动驾驶实验室举办,侧重于自动驾驶中的多帧感知,预测和自动驾驶规划,旨在聚集来自学术界和工业界的研究人员和工程师,讨论自动驾驶中的计算机视觉应用。美团无人配送与视觉团队此项比赛获得了第一名。
在该比赛中,参赛队伍需要根据每个障碍物过去3秒的运动轨迹,预测出它在未来3秒的轨迹。障碍物共有四种类型,包括行人、自行车、大型机动车、小型机动车。每种障碍物的轨迹用轨迹上的采样点来表示,采样的频率是2赫兹。美团的方法最终以1.3425的成绩取得该比赛的第一名,同时我们也在研讨会现场分享了算法和模型的思路。
赛题简介
轨迹预测竞赛数据来源于在北京搜集的包含复杂交通灯和路况的真实道路数据,用于竞赛的标注数据是基于摄像头数据和雷达数据人工标注而来,其中包含各种车辆、行人、自行车等机动车和非机动车。
训练数据:每个道路数据文件包含一分钟的障碍物数据,采样频率为每秒2赫兹,每行标注数据包含障碍物的ID、类别、位置、大小、朝向信息。
测试数据:每个道路数据文件包含3秒的障碍物数据,采样频率为每秒2赫兹,目标是预测未来3秒的障碍物位置。
评价指标
平均位移误差:Average displacement error(ADE),每个预测位置和每个真值位置之间的平均欧式距离差值。
终点位移误差:Final displacement error(FDE),终点预测位置和终点真值位置之间的平均欧式距离差值。
由于该数据集包含不同类型的障碍物轨迹数据,所以采用根据类别加权求和的指标来进行评价。
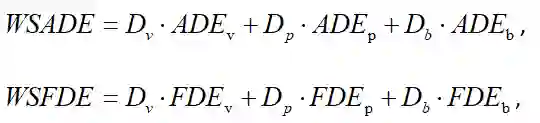
现有方法
这次竞赛要解决的预测问题不依赖地图和其他交通信号等信息,属于基于非结构化数据预测问题,这类问题现在主流的方法主要根据交互性将其区分为两类:1. 独立预测,2. 依赖预测。
独立预测是只基于障碍物历史运动轨迹给出未来的行驶轨迹,依赖预测是会考虑当前帧和历史帧的所有障碍物的交互信息来预测所有障碍物未来的行为。
考虑交互信息的依赖预测,是当前学术界研究比较多的一类问题。但是经调研总结,我们发现其更多的是在研究单一类别的交互,比如在高速公路上都是车辆,那预测这些车辆之间的交互;再比如在人行道上预测行人的交互轨迹。预测所有类别障碍物的之间的交互的方法很少。
以下是做行人交互预测的两个方法模型:
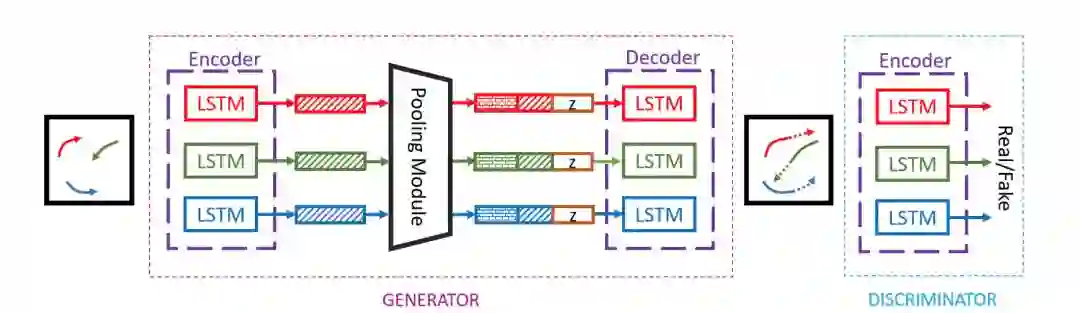
方法1. Social GAN,分别对每个障碍车输入进行Encoder,然后通过一个统一的Pooling模块提取交互信息,再单独进行预测。
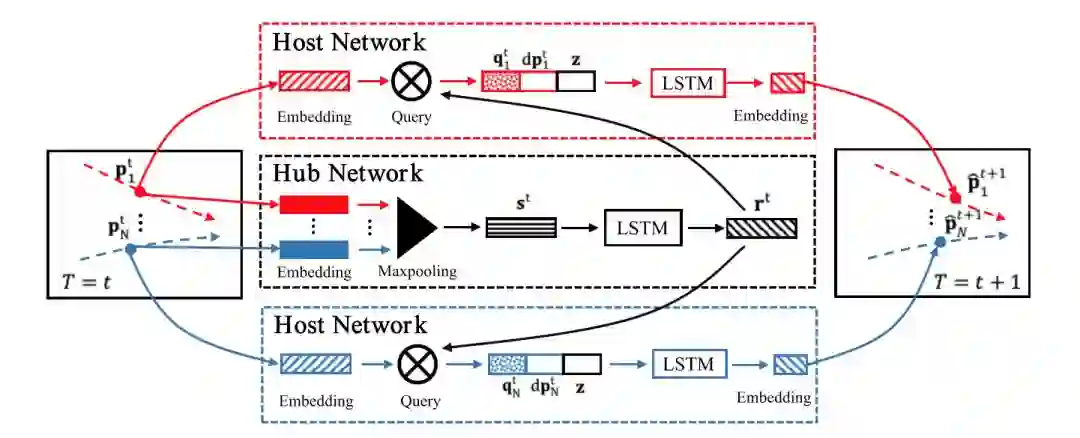
方法2. StarNet,使用一个星型的LSTM网络,使用Hub网络提取所有障碍物的交互信息,然后再输出给每个Host网络独立预测每个障碍物的轨迹。
我们的方法
数据分析
拿到赛题之后,我们首先对训练数据做了分析,由于最终的目标是预测障碍物位置,所以标注数据中的障碍物大小信息不太重要,只要根据类别来进行预测即可。
其次,分析朝向信息是否要使用,经统计发现真值标注的朝向信息非常不准确,从下图可以看到,大部分的标注方向信息都和轨迹方向有较大差距,因此决定不使用朝向信息进行预测。
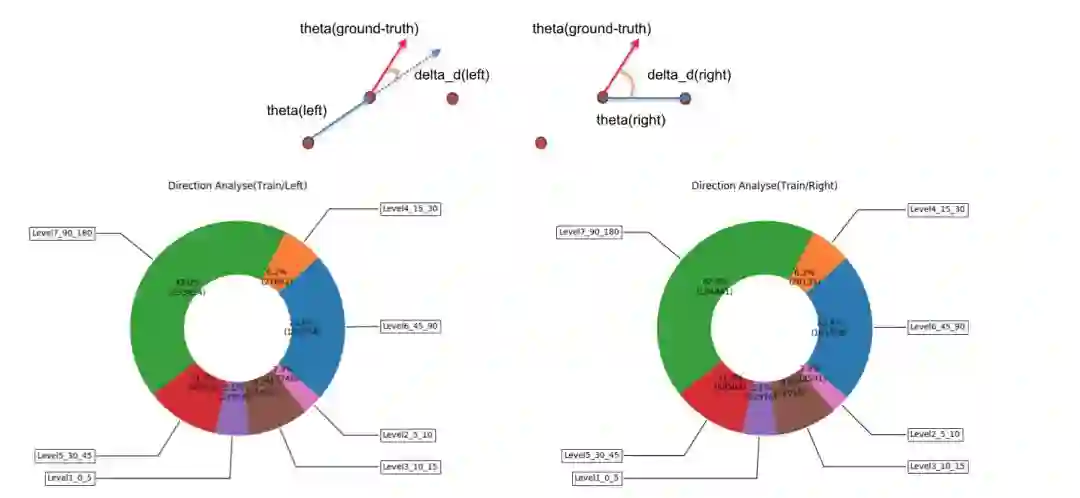
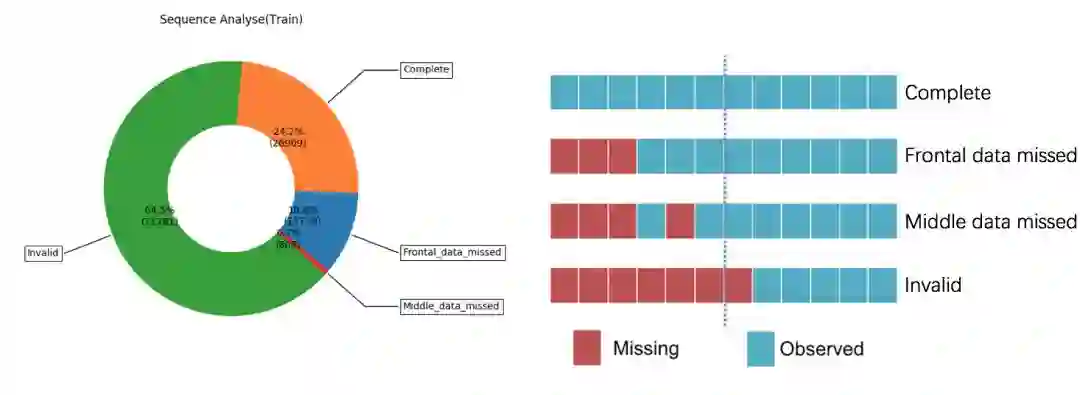
然后,分析数据的完整性,在训练过程中每个障碍物需要12帧数据,才可以模拟测试过程中使用6帧数据来预测未来6帧的轨迹。但是在真实搜集数据的时候,没有办法保证数据的完整性,可能前后或中间都可能缺少数据,因此,我们根据前后帧的位置关系插值生成一些训练数据,以填补数据的缺失。
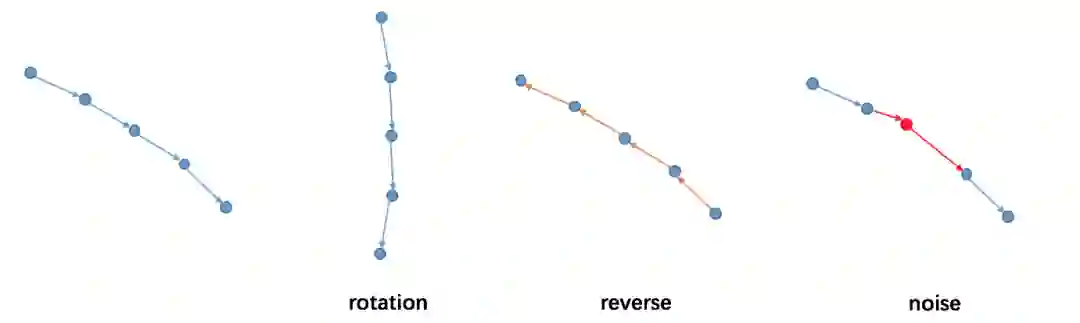
最后,对数据做了增强,由于我们的方法不考虑障碍物之间的交互,仅依赖每个障碍物自身的信息进行训练,因此障碍物轨迹进行了旋转、反向、噪声的处理。
模型结构
由于这次轨迹预测的问题是预测所有类别的轨迹,所以使用解决单一类别的轨迹预测模型不适用于该问题,而且如果把所有的物体放在单一的交互模型中来,不能正确提取出不同障碍物之间的交互特征。我们尝试了一些方法也证实了这一点。
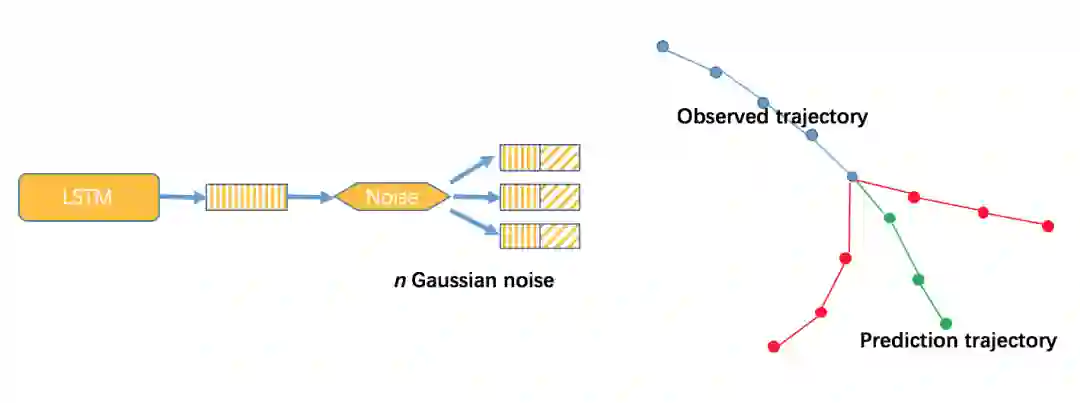
因此在竞赛中,我们使用了多类别的独立预测方法,网络结构如下图,该方法针对每个类别构造一个LSTM的Encoder-Decoder模型,并且在Encoder和Decoder之间加入了Noise模块,Noise模块生成固定维度的高斯噪声,将该噪声和Encoder模块输出的LSTM状态量进行连结作为Decoder模块的LSTM初始状态量,Noise模块主要作用是负责在多轮训练过程中增加数据的扰动,在推理过程中通过给不同的Noise输入,可以生成多个不同的轨迹。
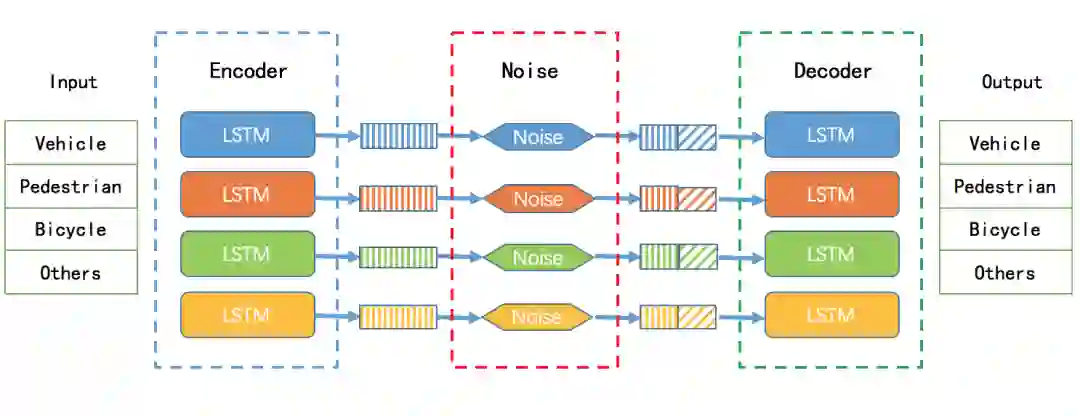
最终,需要在不同的轨迹输出中选择一个最优的轨迹,这里采用了一个简单的规则,选择预测的轨迹方向和历史轨迹方向最接近的轨迹作为最终的轨迹输出。
实验结果
我们仅使用了官方提供的数据进行训练,按照前述数据增强方法先对数据进行增强,然后搭建网络结构进行训练,Loss采用Weighted Sum of ADE(WSADE),采用Adam优化方法,最终提交测试的WSADE结果为1.3425。
| 方法 | WSADE |
|---|---|
| 我们的方法 | 1.3425 |
| StarNet(基于交互的方法) | 1.8626 |
| TrafficPredict(ApolloScape Baseline方法) | 8.5881 |
总结
在这次竞赛中,我们尝试了使用多类别的独立预测方法,通过对数据增强和加入高斯噪声,以及最终人工设计规则选择最优轨迹的方法,在这次障碍物轨迹预测挑战赛(Trajectory Prediction Challenge)中获得了较好的成绩。但是,我们认为,基于交互的方法用的好的话应该会比这种独立预测方法还是要好,比如可以设计多类别内部交互和类别间的交互。另外,也关注到现在有一些基于图神经网络的方法也应用在轨迹预测上,今后会在实际的项目中尝试更多类似的方法,解决实际的预测问题。
参考文献
Yanliang Zhu, Deheng Qian, Dongchun Ren and Huaxia Xia. StarNet: Pedetrian Trajectory Prediction using Deep Neural Network in Star Topology[C]//Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2019.
Gupta A, Johnson J, Fei-Fei L, et al. Social gan: Socially acceptable trajectories with generative adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018: 2255-2264.
Apolloscape. Trajectory dataset for urban traffic. 2018. http://apolloscape.auto/trajectory.html.
作者简介
李鑫,美团无人配送与视觉部PNC组轨迹预测组算法专家。
炎亮,美团无人配送与视觉部PNC组轨迹预测组算法工程师。
德恒,美团无人配送与视觉部PNC组轨迹预测组负责人。
冬淳,美团无人配送与视觉部PNC组负责人。
---------- END ----------
招聘信息
具有扎实的编程能力,能够熟练使用C++或Python作为编程语言;
具有深度学习相关知识,并能熟练使用TensorFlow或Pytorch作为深度学习算法研发框架;
对无人车预测周围障碍物的未来轨迹感兴趣。
也许你还想看
AI Challenger 2018:细粒度用户评论情感分类冠军思路总结





