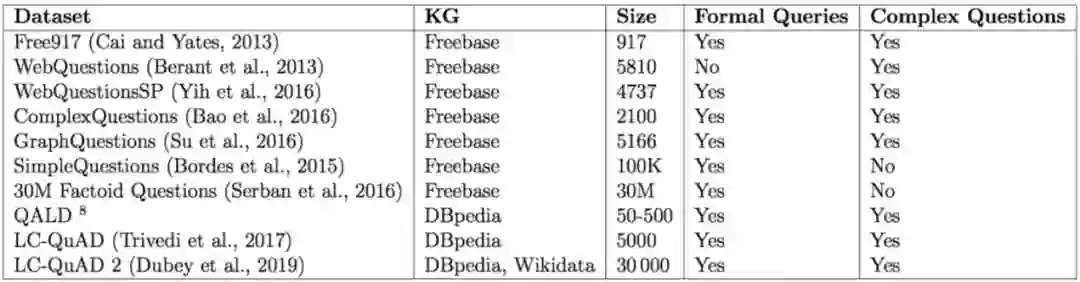
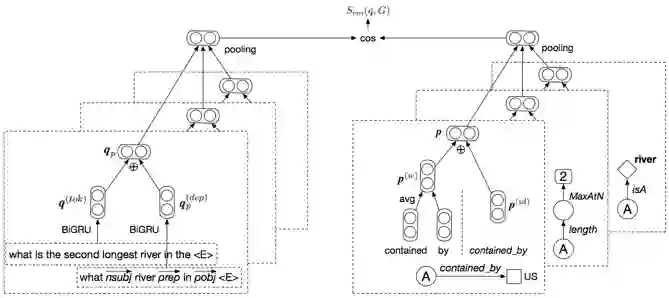
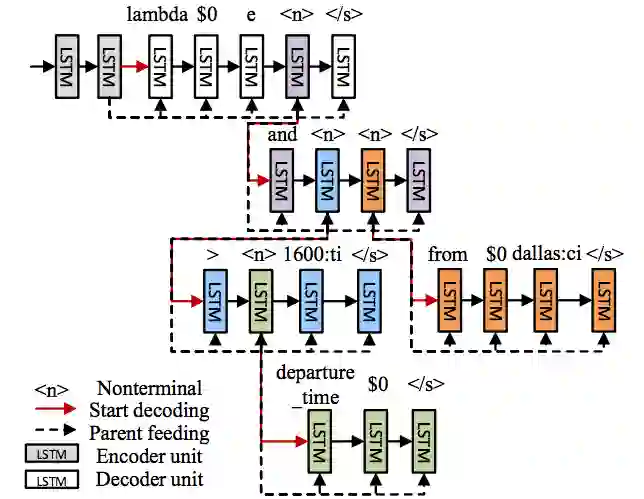
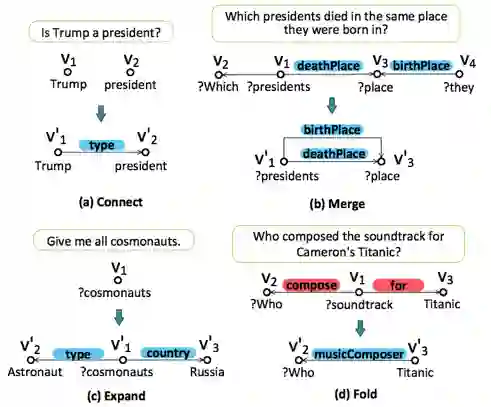
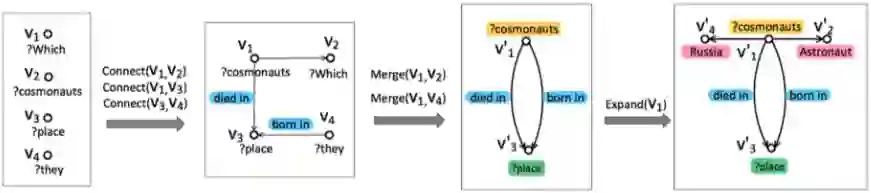
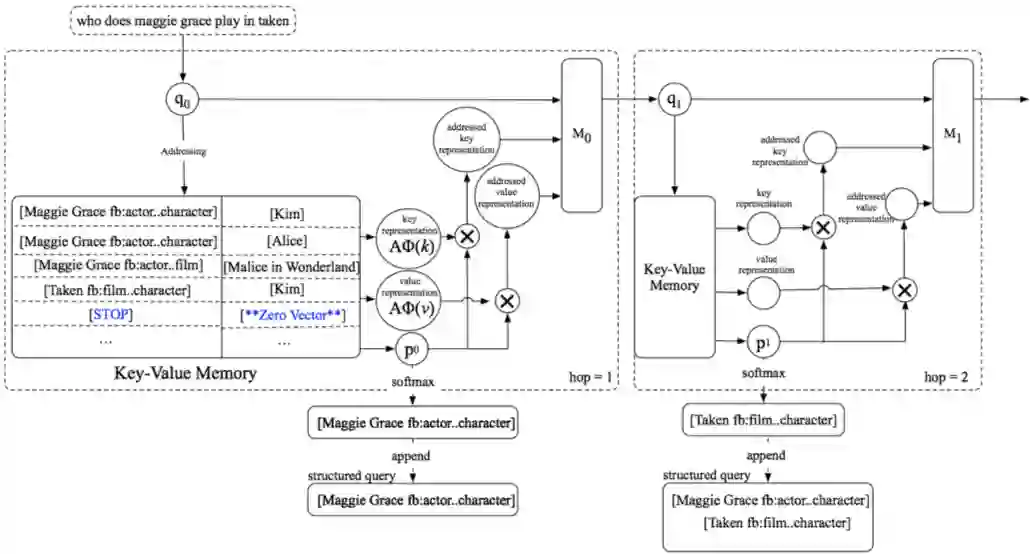
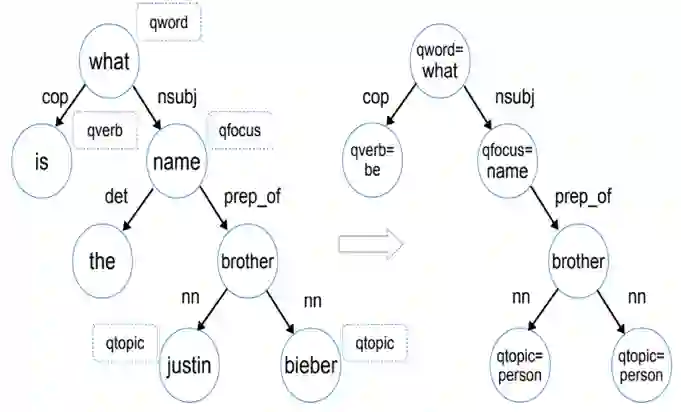
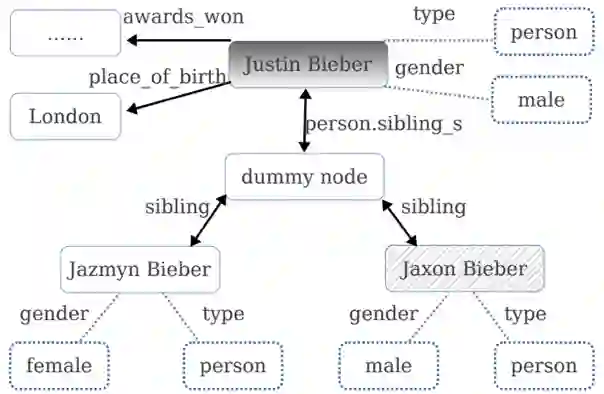
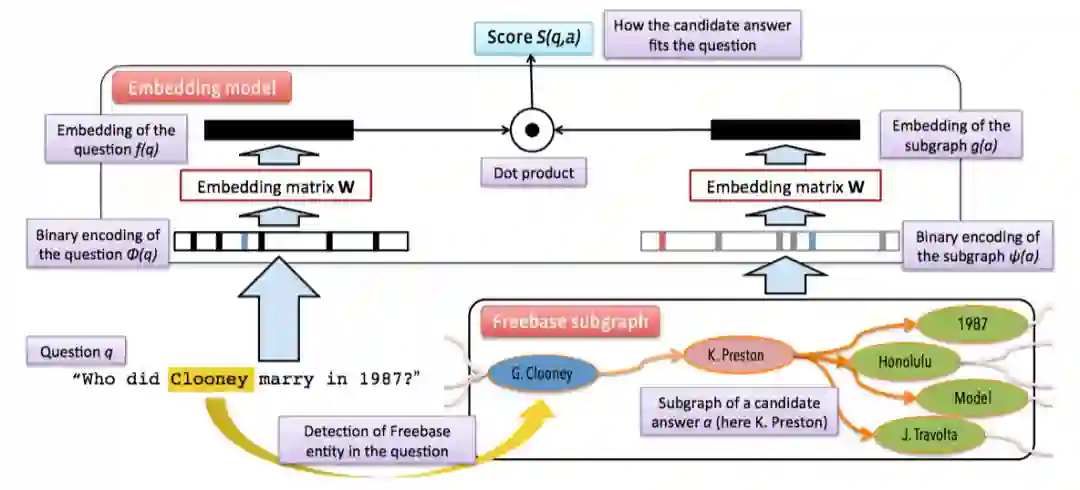
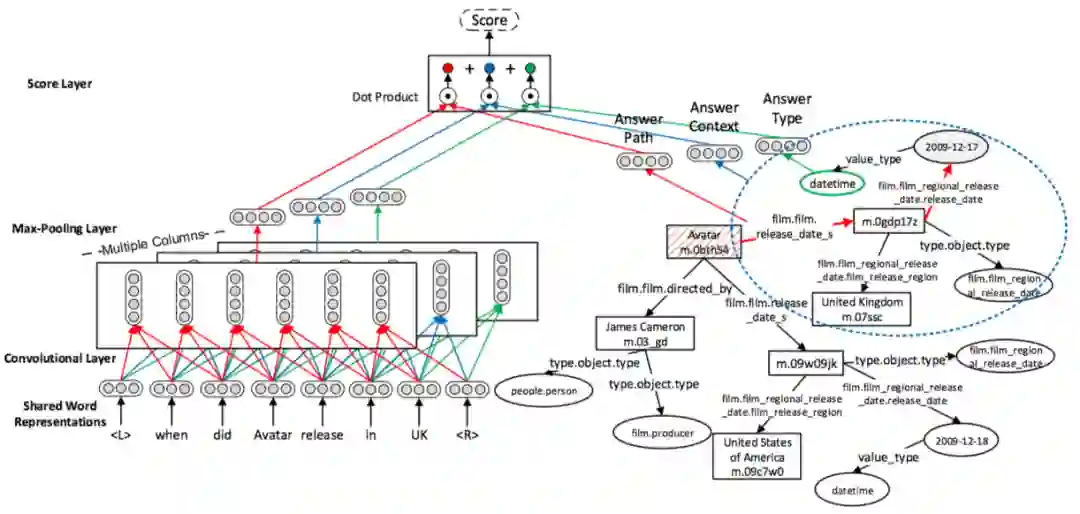
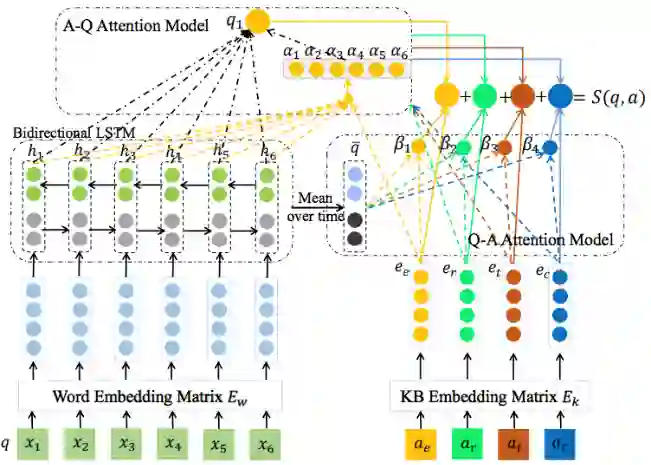
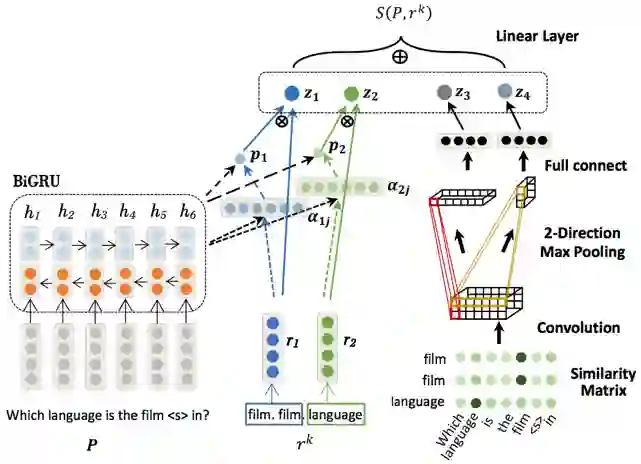
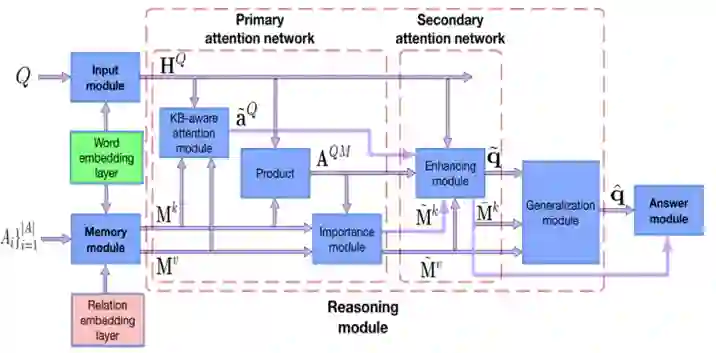
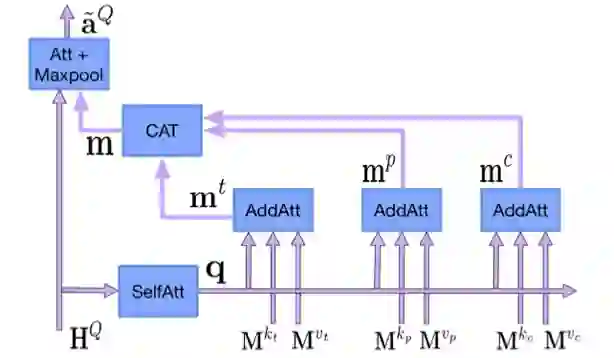
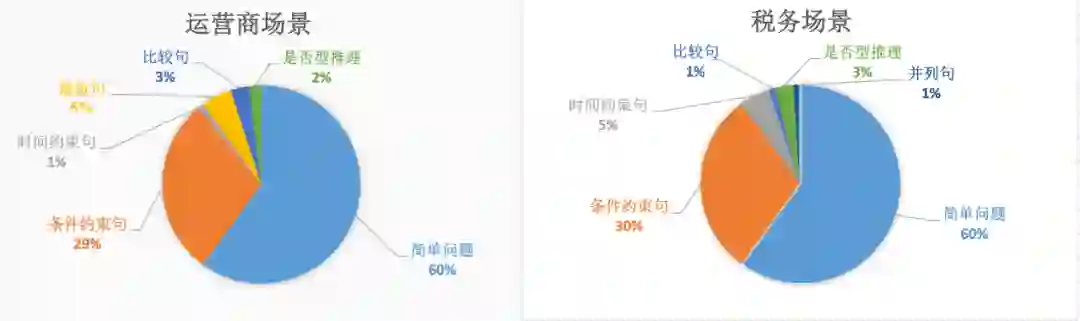
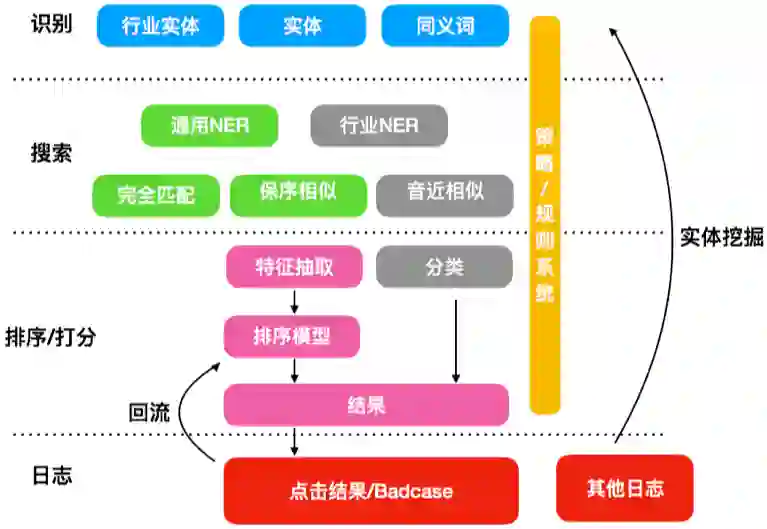
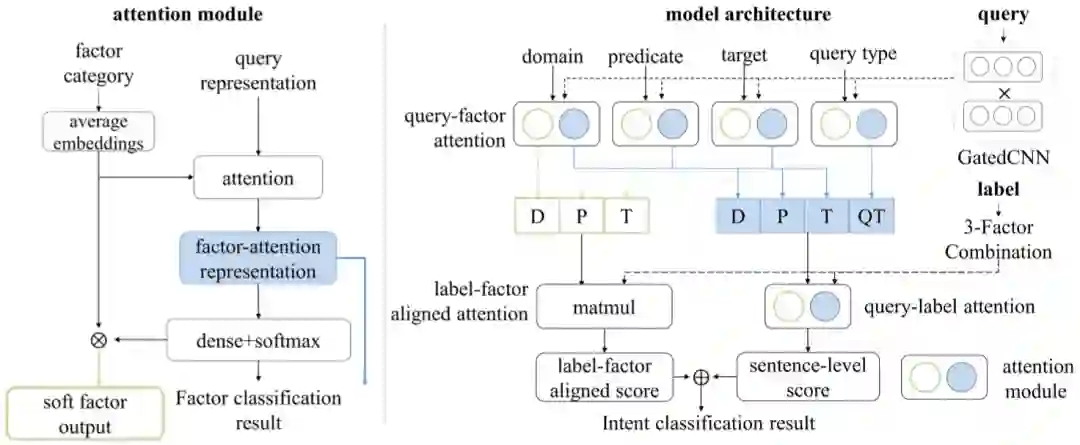
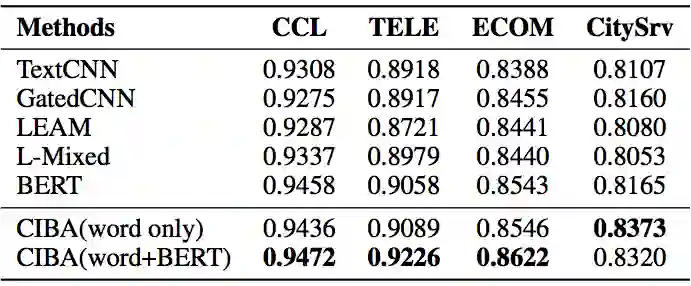
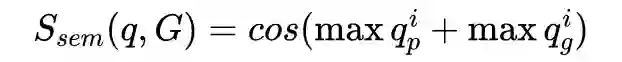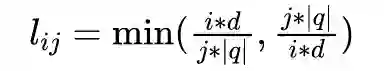WebQuestions [3] 是为了解决真实问题构造的数据集,问题来源于 Google Suggest API,答案使用 Amazon Mechanic Turk 标注生成,是目前使用最广泛的评测数据集,但该数据集有 2 点不足: ① 数据集中只有问答对,没有包含逻辑形式;② 简单问题占比在 84%,缺乏复杂的多跳和推理型问题; 针对第一类问题,微软基于该数据集构建了 WebquestionsSP [4],为每一个答案标注了 SPARQL 查询语句,并去除了部分有歧义、意图不明或者没有明确答案的问题。 针对第二类问题,为了增加问题的复杂性,ComplexQuestions [5] 在 WebQuestions 基础上,引入包含类型约束、显式或者隐式的时间约束、多实体约束、聚合类约束(最值和求和)等问题,并提供逻辑形式的查询。
2.2 QALD系列(Question Answering over Linked Data)
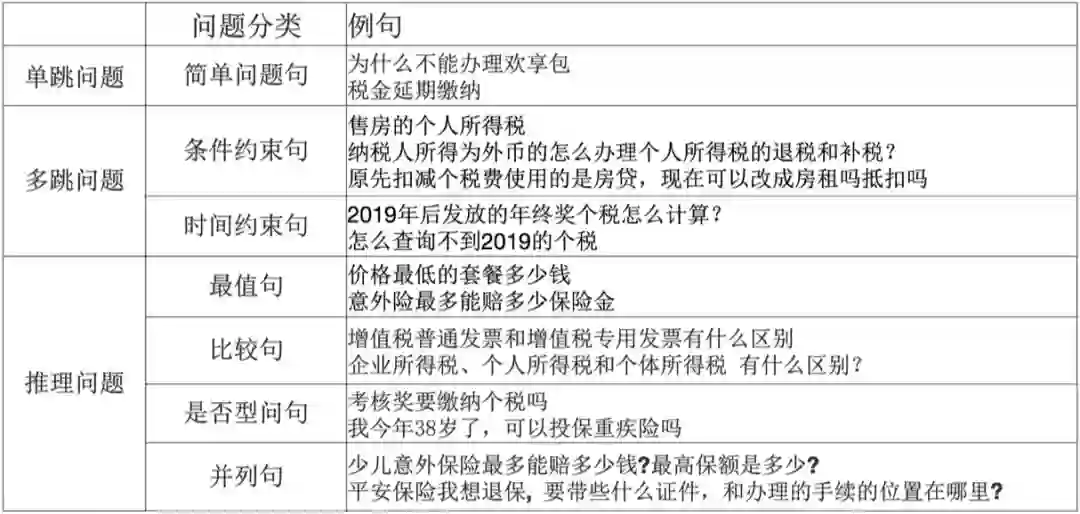
QALD 是 CLEF 上的一个评测子任务,自 2011 年开始,每年举办一届,每次提供若干训练集和测试集,其中复杂问题占比约 38% [6]。 该数据集不仅包括多个关系和多个实体,如:“Which buildings in art deco style did Shreve, Lamb and Harmon design?”;还包括含有时间、比较级、最高级和推理类的问题,如:“How old was Steve Jobs’s sister when she first met him?”[7]。
Trivedi [8] 等人在 2017 年公布了一个针对 DBpedia 的复杂问题数据集,该数据集中简单的单跳问题占比 18%,典型的问句形式如:“What are the mascots of the teams participating in the turkish handball super league?”。 该数据集的构建,先利用一部分 SPARQL 模板,一些种子实体和部分关联属性通过 DBpedia 生成具体的 SPARQL,然后再利用定义好的问句模板半自动利用 SPARQL 生成问句,最后通过众包形成最后的标注问题。 Dubey 等人也使用同样的方法,构建了一个数据量更大更多样的数据集 LcQuAD 2.0 [9]。
[1] Yang Z, Qi P, Zhang S, et al. Hotpotqa: A dataset for diverse, explainable multi-hop question answering[J]. arXiv preprint arXiv:1809.09600, 2018.[2] Saha A, Pahuja V, Khapra M M, et al. Complex sequential question answering: Towards learning to converse over linked question answer pairs with a knowledge graph[C]//Thirty-Second AAAI Conference on Artificial Intelligence. 2018.[3] Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 conference on empirical methods in natural language processing. 2013: 1533-1544.[4] Yih W, Richardson M, Meek C, et al. The value of semantic parse labeling for knowledge base question answering[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2016: 201-206.[5] Bao J, Duan N, Yan Z, et al. Constraint-based question answering with knowledge graph[C]//Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. 2016: 2503-2514.[6] 刘康,面向知识图谱的问答系统. AI前沿讲习班第8期PPT[7] 赵军, 刘康, 何世柱, 陈玉博. 知识图谱[B]. 2018.[8] Trivedi P, Maheshwari G, Dubey M, et al. Lc-quad: A corpus for complex question answering over knowledge graphs[C]//International Semantic Web Conference. Springer, Cham, 2017: 210-218.[9] Dubey M, Banerjee D, Abdelkawi A, et al. Lc-quad 2.0: A large dataset for complex question answering over wikidata and dbpedia[C]//International Semantic Web Conference. Springer, Cham, 2019: 69-78.[10] Liang C, Berant J, Le Q, et al. Neural symbolic machines: Learning semantic parsers on freebase with weak supervision[J]. arXiv preprint arXiv:1611.00020, 2016.[11] Steedman M. A very short introduction to CCG[J]. Unpublished paper. http://www. coqsci. ed. ac. uk/steedman/paper. html, 1996.[12] Liang P. Lambda dependency-based compositional semantics[J]. arXiv preprint arXiv:1309.4408, 2013.
[13] Dahl D A, Bates M, Brown M, et al. Expanding the scope of the ATIS task: The ATIS-3 corpus[C]//Proceedings of the workshop on Human Language Technology. Association for Computational Linguistics, 1994: 43-48.
[14] Yih S W, Chang M W, He X, et al. Semantic parsing via staged query graph generation: Question answering with knowledge base[J]. 2015.
[15] Yang Y, Chang M W. S-mart: Novel tree-based structured learning algorithms applied to tweet entity linking[J]. arXiv preprint arXiv:1609.08075, 2016.
[16] Yu M, Yin W, Hasan K S, et al. Improved neural relation detection for knowledge base question answering[J]. arXiv preprint arXiv:1704.06194, 2017.
[17] Luo K, Lin F, Luo X, et al. Knowledge base question answering via encoding of complex query graphs[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2185-2194.
[18] Zhu S, Cheng X, Su S. Knowledge-based question answering by tree-to-sequence learning[J]. Neurocomputing, 2020, 372: 64-72.
[19] Wu P, Zhang X, Feng Z. A Survey of Question Answering over Knowledge Base[C]//China Conference on Knowledge Graph and Semantic Computing. Springer, Singapore, 2019: 86-97.
[20] Dong L, Lapata M. Language to logical form with neural attention[J]. arXiv preprint arXiv:1601.01280, 2016.
[21] Xu K, Wu L, Wang Z, et al. Exploiting rich syntactic information for semantic parsing with graph-to-sequence model[J]. arXiv preprint arXiv:1808.07624, 2018.
[22] Hu S, Zou L, Zhang X. A state-transition framework to answer complex questions over knowledge base[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2098-2108.[23] Cheng J, Reddy S, Saraswat V, et al. Learning structured natural language representations for semantic parsing[J]. arXiv preprint arXiv:1704.08387, 2017.[24] Dyer C, Ballesteros M, Ling W, et al. Transition-based dependency parsing with stack long short-term memory[J]. arXiv preprint arXiv:1505.08075, 2015.[25] Weston J, Chopra S, Bordes A. Memory networks[J]. arXiv preprint arXiv:1410.3916, 2014.[26] Miller A, Fisch A, Dodge J, et al. Key-value memory networks for directly reading documents[J]. arXiv preprint arXiv:1606.03126, 2016.[27] Xu K, Lai Y, Feng Y, et al. Enhancing Key-Value Memory Neural Networks for Knowledge Based Question Answering[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 2937-2947.[28] Yao X, Van Durme B. Information extraction over structured data: Question answering with freebase[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2014: 956-966.[29] Bordes A, Chopra S, Weston J. Question answering with subgraph embeddings[J]. arXiv preprint arXiv:1406.3676, 2014.[30] Dong L, Wei F, Zhou M, et al. Question answering over freebase with multi-column convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2015: 260-269.[31] Hao Y, Zhang Y, Liu K, et al. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017: 221-231.[32] Qu Y, Liu J, Kang L, et al. Question answering over freebase via attentive RNN with similarity matrix based CNN[J]. arXiv preprint arXiv:1804.03317, 2018, 38.[33] Sukhbaatar S, Szlam A, Weston J, et al. Weakly supervised memory networks[J]. CoRR, abs/1503.08895, 2.[34] Bordes A, Usunier N, Chopra S, et al. Large-scale simple question answering with memory networks[J]. arXiv preprint arXiv:1506.02075, 2015.[35] Jain S. Question answering over knowledge base using factual memory networks[C]//Proceedings of the NAACL Student Research Workshop. 2016: 109-115.[36] Chen Y, Wu L, Zaki M J. Bidirectional attentive memory networks for question answering over knowledge bases[J]. arXiv preprint arXiv:1903.02188, 2019.[37] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.[38] Reddy S, T_ckstr_m O, Collins M, et al. Transforming dependency structures to logical forms for semantic parsing[J]. Transactions of the Association for Computational Linguistics, 2016, 4: 127-140.[39] Abujabal A, Yahya M, Riedewald M, et al. Automated template generation for question answering over knowledge graphs[C]//Proceedings of the 26th international conference on world wide web. 2017: 1191-1200.[40] Cui W, Xiao Y, Wang H, et al. KBQA: learning question answering over QA corpora and knowledge bases[J]. arXiv preprint arXiv:1903.02419, 2019.[41] Talmor A, Berant J. The web as a knowledge-base for answering complex questions[J]. arXiv preprint arXiv:1803.06643, 2018.[42] Vakulenko S, Fernandez Garcia J D, Polleres A, et al. Message Passing for Complex Question Answering over Knowledge Graphs[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1431-1440.[43] Qiu Y, Wang Y, Jin X, et al. Stepwise Reasoning for Multi-Relation Question Answering over Knowledge Graph with Weak Supervision[C]//Proceedings of the 13th International Conference on Web Search and Data Mining. 2020: 474-482.[44] Petrochuk M, Zettlemoyer L. Simplequestions nearly solved: A new upperbound and baseline approach[J]. arXiv preprint arXiv:1804.08798, 2018.[45] Zhang J, Ye Y, Zhang Y, et al. Multi-Point Semantic Representation for Intent Classification[J]. AAAI. 2020.[46] Jia R, Liang P. Adversarial examples for evaluating reading comprehension systems[J]. arXiv preprint arXiv:1707.07328, 2017.[47] Chakraborty N, Lukovnikov D, Maheshwari G, et al. Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs[J]. arXiv preprint arXiv:1907.09361, 2019.[48] Ribeiro M T, Singh S, Guestrin C. Semantically equivalent adversarial rules for debugging nlp models[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 856-865.