TensorFlow 3D 助力理解 3D 场景!

文 / 研究员 Alireza Fathi 和 AI 实习生 Rui Huang,Google Research
过去几年里,3D 传感器(如激光雷达、深度传感摄像头和雷达)越发普及,对于能够处理这些设备所捕获数据的场景理解技术,相应需求也在不断增加。此类技术可以让使用这些传感器的机器学习 (ML) 系统,如无人驾驶汽车和机器人,在现实世界中导航和运作,并在移动设备上创建改进的增强现实体验。
最近,计算机视觉领域开始在 3D 场景理解方面取得良好进展,包括用于移动 3D 目标检测、透明目标检测等的模型,但由于可应用于 3D 数据的可用工具和资源有限,进入该领域本身可能具有挑战性。
为了进一步提高 3D 场景理解能力,降低感兴趣的研究人员的入门门槛,我们发布了 TensorFlow 3D (TF 3D),这一高度模块化的高效库旨在将 3D 深度学习功能引入 TensorFlow。TF 3D 提供了一组流行的运算、损失函数、数据处理工具、模型和指标,使更广泛的研究社区能够开发、训练和部署最先进的 3D 场景理解模型。
TF 3D 包含用于最先进 3D 语义分割、3D 目标检测和 3D 实例分割的训练和评估流水线,并支持分布式训练。它也可实现其他潜在应用,如 3D 目标形状预测、点云配准和点云密化。此外,它还提供了统一的数据集规范和配置,用于训练和评估标准 3D 场景理解数据集。目前支持 Waymo Open、ScanNet 和 Rio 数据集。不过,用户可以将 NuScenes 和 Kitti 等其他流行数据集自由转换为相似格式,并将其用于预先存在或自定义创建的流水线,也可以通过利用 TF 3D 进行各种 3D 深度学习研究和应用,包括快速原型设计以及试验新想法的方式来部署实时推断系统。
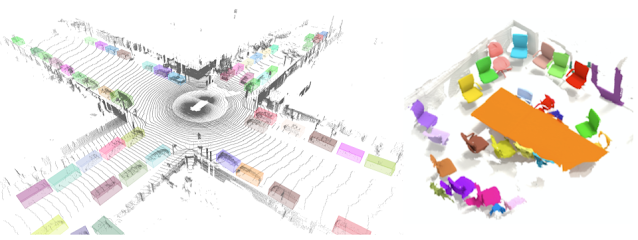
左侧为 TF 3D 中 3D 目标检测模型在来自 Waymo Open 数据集的一帧画面上的示例输出。右侧为 3D 实例分割模型在来自 ScanNet 数据集 的场景上的示例输出
我们将介绍 TF 3D 提供的高效可配置的稀疏卷积主干,它是在各种 3D 场景理解任务上取得最先进结果的关键。此外,我们将分别介绍 TF 3D 目前支持的三种流水线:3D 语义分割、3D 目标检测和 3D 实例分割。
3D 稀疏卷积网络
传感器捕获的 3D 数据通常具有一个场景,其中包含一组感兴趣的目标(如汽车、行人等),其周围大多是有限(或无)兴趣的开放空间。因此,3D 数据本质上是稀疏的。在这样的环境下,卷积的标准实现将需要大量计算并消耗大量内存。因此,在 TF 3D 中,我们使用子流形稀疏卷积和池化运算,旨在更有效地处理 3D 稀疏数据。稀疏卷积模型是大多数户外自动驾驶(如 Waymo、NuScenes)和室内基准(如 ScanNet)中应用的最先进方法的核心。
子流形稀疏卷积
https://arxiv.org/abs/1706.01307
我们还使用多种 CUDA 技术来加快计算速度(例如,哈希处理、在共享内存中分区/缓存过滤器,以及使用位运算)。Waymo Open 数据集上的实验表明,该实现比使用预先存在的 TensorFlow 运算的精心设计实现快约 20 倍。
TF 3D 然后使用 3D 子流形稀疏 U-Net 架构为每个体素 (Voxel) 提取特征。通过让网络同时提取粗略特征和精细特征并将其组合以进行预测,事实证明 U-Net 架构是有效的。U-Net 网络包括编码器、瓶颈和解码器三个模块,每个模块都由许多稀疏卷积块组成,并可能进行池化或解池化运算。
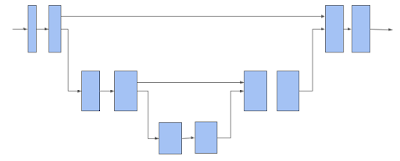
3D 稀疏体素 U-Net 架构。请注意,水平箭头接收体素特征并对其应用子流形稀疏卷积。下移箭头执行子流形稀疏池化。上移箭头将回收池化的特征,与来自水平箭头的特征合并,并对合并后的特征进行子流形稀疏卷积
上述稀疏卷积网络是 TF 3D 中提供的 3D 场景理解流水线的主干。下面描述的每个模型都使用此主干网络提取稀疏体素的特征,然后添加一个或多个附加预测头来推断感兴趣的任务。用户可以更改编码器/解码器层数和每层中卷积的数量以及修改卷积过滤器的大小来配置 U-Net 网络,从而通过不同的主干配置探索大范围的速度/准确率权衡。
3D 语义分割
3D 语义分割模型只有一个输出头,用于预测每个体素的语义分数,语义分数映射回点以预测每个点的语义标签。

来自 ScanNet 数据集的室内场景的 3D 语义分割
3D 语义分割模型
https://arxiv.org/abs/1711.10275
3D 实例分割
在 3D 实例分割中,除了预测语义外,目标是将属于同一目标的体素归于一组。TF 3D 中使用的 3D 实例分割算法基于我们先前的使用深度指标学习的 2D 图像分割研究工作。该模型预测每个体素的实例嵌入向量以及每个体素的语义分数。实例嵌入向量将体素映射到一个嵌入向量空间,其中对应同一目标实例的体素靠得很近,而对应不同目标的体素则相距很远。在这种情况下,输入是点云而不是图像,并使用 3D 稀疏网络而不是 2D 图像网络。在推断时,贪婪的算法每次挑选一个实例种子,并使用体素嵌入向量之间的距离将其分组为段。
深度指标学习的 2D 图像分割研究
https://arxiv.org/abs/1703.10277
3D 目标检测
3D 目标检测模型预测每个体素的大小、中心、旋转矩阵以及目标语义分数。在推断时,采用盒建议机制 (Box proposal mechanism) 将成千上万的各体素的盒预测减少为几个准确的盒建议,然后在训练时,将盒预测和分类损失应用于各体素的预测。我们对预测和基本事实盒顶角之间的距离应用 Huber 损失。由于从其大小、中心和旋转矩阵估计盒顶角的函数是可微的,因此损失将自动传播回这些预测的目标属性。我们采用动态盒分类损失,将与基本事实强烈重合的盒分类为正,将不重合的盒分类为负。

我们在 ScanNet 数据集上的 3D 目标检测结果
在我们最近的论文《DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes》中,我们详细描述了 TF 3D 中用于目标检测的单阶段弱监督学习算法。此外,在后续工作中,我们提出基于 LSTM 的稀疏多帧模型,扩展了 3D 目标检测模型以利用时间信息。我们进一步证明,在 Waymo Open 数据集中,这种时间模型比逐帧方法的性能高出 7.5%。

DOPS 论文中介绍的 3D 目标检测和形状预测模型。3D 稀疏 U-Net 用于提取每个体素的特征向量。目标检测模块使用这些特征建议 3D 盒和语义分数。同时,网络的另一个分支预测形状嵌入向量,用于输出每个目标的网格
DOPS:Learning to Detect 3D Objects and Predict their 3D Shapes
https://arxiv.org/abs/2004.01170
准备好了吗?
这个代码库在我们的 3D 计算机视觉项目中发挥了明显的作用,我们希望对您也一样。我们欢迎对代码库的贡献,也请继续关注我们对框架的进一步更新。要开始使用,请访问我们的 GitHub 仓库。
GitHub 仓库
https://github.com/google-research/google-research/tree/master/tf3d
致谢
TensorFlow 3D 代码库和模型的发布是 Google 研究人员在产品组的反馈和测试下广泛合作的结果。我们要特别强调 Alireza Fathi 和 Rui Huang(在 Google 期间完成的工作)的核心贡献,另外还要特别感谢 Guangda Lai、Abhijit Kundu、Pei Sun、Thomas Funkhouser、David Ross、Caroline Pantofaru、Johanna Wald、Angela Dai 和 Matthias Niessner。
点击 “阅读原文” 访问 GitHub。





