学界 | Alex Smola论文详解:准确稀疏可解释,三大优点兼具的序列数据预测算法LLA| ICML 2017
AI 科技评论按:近日,ICML2017收录的一篇论文引起了AI科技评论的注意。这篇关于序列数据预测的论文是 Alex Smola 和他在 CMU 时的两个博士生 Manzil Zaheer 和 Amr Ahmed 共同完成的,后者目前已经加入谷歌大脑。
Alex Smola是机器学习界的重要人物,他的主要研究领域是可拓展算法、核方法、统计模型和它们的应用,已经发表超过200篇论文并参与编写多本学术专著。他曾在NICTA、雅虎、谷歌从事研究工作,在2013到2016年间任CMU教授,之后来到亚马逊任AWS的机器学习总监。MXNet 在去年成为 Amazon AWS 的官方开源平台,而 MXNet 的主要作者李沐正是 Alex Smola 在 CMU 时的学生。
以下AI 科技评论就对这篇名为「Latent LSTM Allocation: Joint Clustering and Non-Linear Dynamic Modeling of Sequential Data」(潜LSTM分配:序列数据的联合聚类和非线性动态建模)的论文做具体的介绍。

研究背景
序列数据预测是机器学习领域的一个重要问题,这个问题在文本到用户行为的各种行为中都会出现。比如在统计学语言建模应用中,研究目标是在给定的语境下预测文本数据的下一个单词,这和用户行为建模应用中根据用户历史行为预测下一个行为非常类似。准确的用户行为建模就是提供用户相关的、个性化的、有用的内容的重要基础。
一个好的序列数据模型应当准确、稀疏、可解释,然而目前所有的用户模型或者文本模型都不能同时满足这三点要求。目前最先进的序列数据建模方法是使用 LSTM(Long-Short Term Memory)这样的 RNN 网络,已经有许多例子证明他们可以有效地捕捉数据中的长模式和短模式,比如捕捉语言中表征级别的语义,以及捕捉句法规律。但是,这些神经网络学到的表征总的来说不具有解释性,人类也无法访问。不仅如此,模型所含的参数的数量是和模型能够预测的单词类型或者动作类型成正比的,参数数量往往会达到千万级甚至亿级。值得注意的是,在用户建模任务中,字符级别的 RNN 是不可行的,因为描述用户行为的往往不是单词而是 hash 指数或者 URL。
从另一个角度看这个问题,以 LDA 和其它一些变种话题模型为代表的多任务学习潜变量模型,它们是严格的非序列数据模型,有潜力很好地从文本和用户数据中挖掘潜在结构,而且也已经取得了一些商业上的成果。话题模型很热门,因为它们能够在不同用户(或文档)之间共享统计强度,从而具有把数据组织为一小部分突出的主题(或话题)的能力。这样的话题表征总的来说可以供人类访问,也很容易解释。
LLA模型
在这篇论文中,作者们提出了 Latent LSTM Allocation(潜LSTM分配,LLA)模型,它把非序列LDA的优点嫁接到了序列RNN上面来。LLA借用了图模型中的技巧来指代话题(关于一组有关联的词语或者用户行为),方法是在不同用户(或文档)和循环神经网络之间共享统计强度,用来对整个(用户动作或者文档)序列中的话题进化变化建模,抛弃了从单个用户行为或者单词级别做建模的方法。
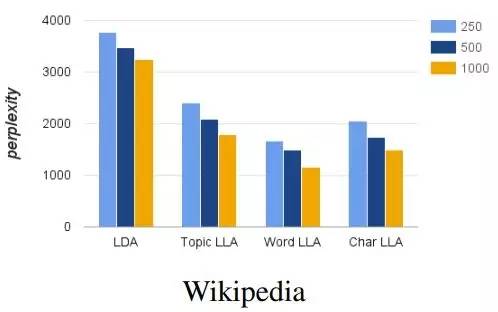
LLA 继承了 LDA 模型的稀疏性和可解释性,同时还具有 LSTM 的准确率。作者们在文中提供了多个 LLA 的变种,在保持解释性的前提下尝试在模型大小和准确率之间找到平衡。如图1所示,在基于Wikipedia数据集对语言建模的任务中,LLA 取得了接近 LSTM 的准确率,同时从模型大小的角度还保持了与 LDA 相同的稀疏性。作者们提供了一个高效的推理算法用于LLA的参数推理,并在多个数据集中展示了它的功效和解释性。
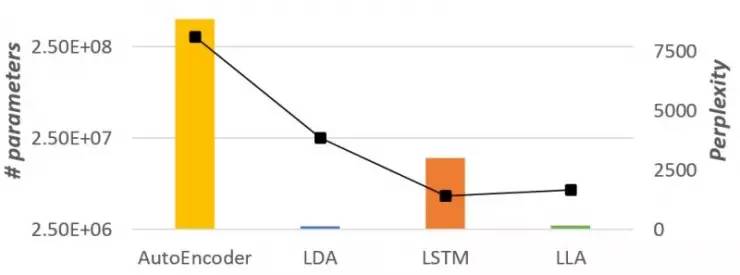
柱状图是参数数量,折线是复杂度。根据图中示意,在基于 Wikipedia 数据集的语言建模任务中,LLA 比 LDA 的复杂度更低,参数数量也比 LSTM 大大减少。
LLA 把分层贝叶斯模型和 LSTM 结合起来。LLA 会根据用户的行为序列数据对每个用户建模,模型还会同时把这些动作分为不同的话题,并且学到所分到的话题序列中的短期动态变化,而不是直接学习行为空间。这样的结果就是模型的可解释性非常高、非常简明,而且能够捕捉复杂的动态变化。作者们设计了一个生成式分解模型,先用 LSTM 对话题序列建模,然后用 Dirichlet 多项式对单词散播建模,这一步就和 LDA 很相似。
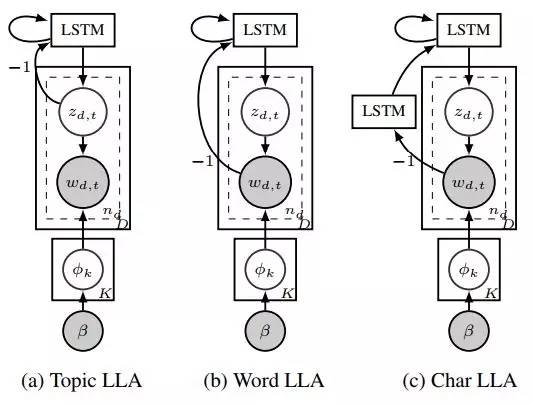
假设话题数目为K、单词库大小为V;有一个文档集D,其中单篇文档d由Nd个单词组成。生成式模型的完整流程就可以表示为(上图 a 的为例):

在这样的模型下,观察一篇指定的文档d的边际概率就可以表示为:
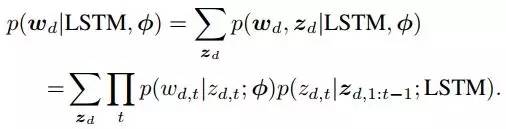
式中,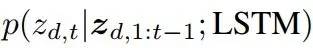
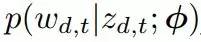
这种修改的好处有两层,首先这样可以获得一个分解模型,参数的数量相比 RRLM 得到了大幅度减少。其次,这个模型的可解释性非常高。
另一方面,为了实现基于 LLA 的推理算法,作者们用随机 EM 方法对模型表示进行了近似,并设计了一些加速采样方法。模型伪码如下:

LLA变体
作者们认为,模型直接使用原始文本会比使用总结出的主题有更好的预测效果。所以在 Topic LLA之外,又提出了两个变体 Word LLA 和 Char LLA (前文 a、b、c 三个模型),分别能够直接处理原文本的单词和字符(Char LLA自己会对字符串做出转换,从而缓和 Word LLA 单词库过大的问题 )。
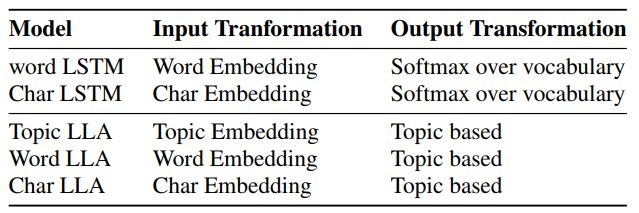
实验结果
在几个实验中,作者们把60%的数据用于训练模型,让模型预测其余40%作为任务目标。同步对比的模型有自动编码器(解码器)、单词级别LSTM、字符级别LSTM、LDA、Distance-dependent LDA。
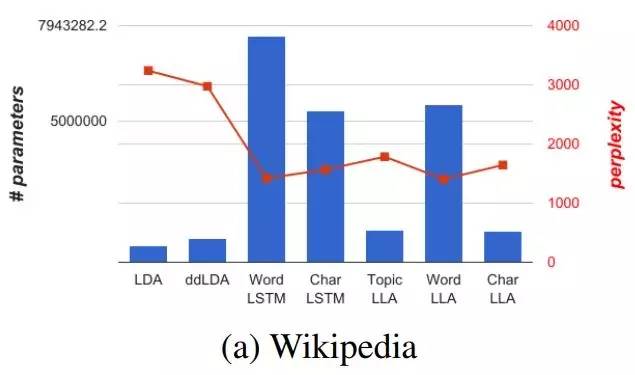
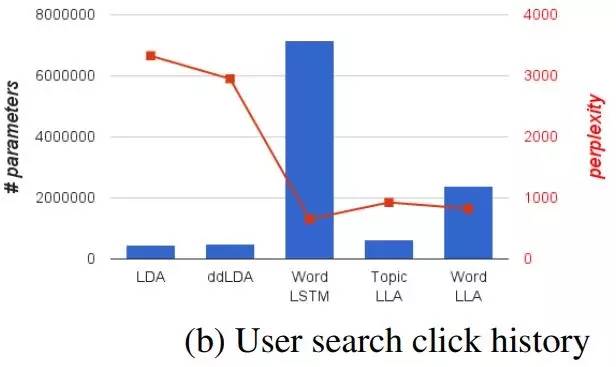
柱状图部分的参数数量用来体现模型大小,折现的复杂度用于体现模型的准确率。可以看到,两个任务中 LDA 仍然保持了最小的模型大小,而单词级别LSTM表现出了最高的准确率,但模型大小要高出一个数量级;从单词级别LSTM到字符级别LSTM,模型大小基本减半,准确度也有所牺牲。
在这样的对比之下就体现出了 LLA 的特点,在保持了与 LDA 同等的解释性的状况下,能够在模型大小和准确度之间取得更好的平衡(目标并不是达到比LSTM更高的准确率)。
其它方面的对比如下:
收敛速度 LLA的收敛速度并没有什么劣势,比快速LDA采样也只慢了一点点。不过基于字符的LSTM和LLA都要比其它的变体训练起来慢一些,这是模型本质导致的,需要在单词和字符层面的LSTM都做反向传播。
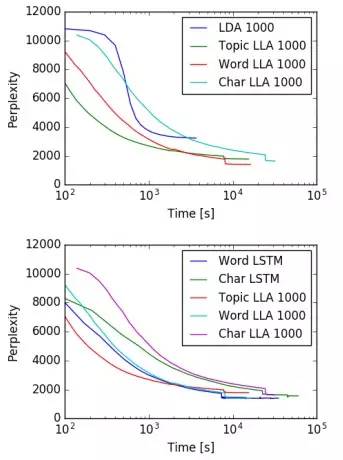
特征效率 作者们做了尝试,只具有250个话题的三种 LLA 模型都比具有1000个话题的 LDA 模型有更高的准确率。这说明 LLA 的特征效率更高。从另一个角度说,LLA 的表现更好不是因为模型更大,而是因为它对数据中的顺序有更好的描述能力。
解释性 LLA和LDA都能对全局主题做出揭示,LLA 总结出的要更加明确。如下表,LDA 会总结出“Iowa”,仅仅因为它在不同的文档中都出现了;而 LLA 追踪短期动态的特性可以让它在句子的不同位置正确切换主题。

联合训练 由于论文中的模型可以切分为 LDA 和 LSTM 两部分,作者们也对比了“联合训练”和“先训练 LDA,再在话题上训练 LSTM”两种不同训练方式的效果。结果表明,联合训练的效果要好很多,因为单独训练的 LDA 中产生的随机错误也会被之后训练的 LSTM 学到,LSTM 的学习表现就是由 LDA 的序列生成质量决定的。所以联合训练的状况下可以提高 LDA 的表现,从而提高了整个模型的表现。

论文地址:http://proceedings.mlr.press/v70/zaheer17a.html
AI 科技评论编译整理
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————





