HTML 30 年进化史



HTML 的前身 SGML
http://info.cern.ch/ 世界第一个网站,非常简洁。

浏览器大战对 HTML 的影响
<p title='aaa'><input readonly="true" /></p>
<P title=aaa><INPUT READONLY >

HTML 的版本
-
不存在 HTML1.0, 各自为战 -
HTML2.0,从 1995 年 11 月到 2000 年; -
HTML3.2, 从 1996 年 1 月到现在; -
HTML4.0,从 1997 年 12 月到现在; -
HTML4.01,从 1999 年 12 月到现在; -
XHTML 1.0,从 2000 年 1 月 20 日到现在; -
HTML5.0,从 2014 年 10 月 29 日到现在。
早期的浏览器包括了:Tim Berners 的 WorldWideWeb 浏览器,兼具浏览器和编辑器功能,但只能运行在NeXTStep操作系统上;CERN的一位数学实习生 Nicola Pellow 开发出 Line-mode 浏览器,能运行在 UNIX 和 MS-DOS 上;Erwise 是第一个带图形界面的浏览器,支持搜索网页中的单词,由四名芬兰大学生开发,在 1992 年发布;加州伯克利的 Pei-Yuan Wei 在1992 年 4月发布了 ViolaWWW,这个浏览器受到了 Mac 程序 HyperCard 的启发,但他没有 Mac 只能接触到 UNIX 机器,1992 年夏天,斯坦福线性加速器中心物理学家 Tony Johnson 为斯坦福的物理学家发布了图形浏览器 Midas;与此同时,CERN 的 Nicola Pellow 和 Robert Cailliau 发布了第一个Mac浏览器 Samba;基于 Viola和 Midas 的 Mosaic 在 1993 年发布;堪萨斯大学发布了 Lynx;康奈尔大学法学院学生 Tom Bruce 发布了 Cello。——节选自《被遗忘的早期浏览器》
https://validator.w3.org/
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="zh-cmn-Hans-CN">
<head>
<meta http-equiv="Content-Type" content="application/xhtml+xml; charset=utf-8" />
<title>test
</title>
<script type="text/javascript">
<![CDATA[
if(1<2)
{
alert('a');
}
]]>
</script>
</head>
<body>
<p>xhtml,It works.
</p>
</body>
</html>

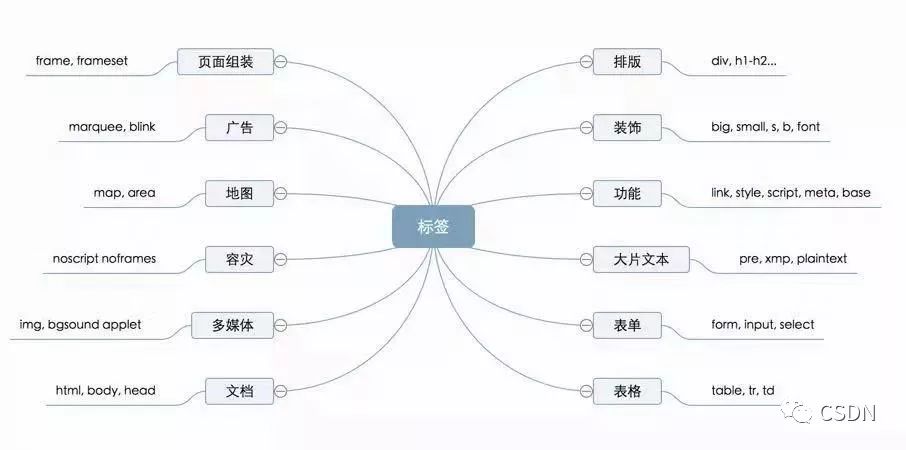
HTML的模块介绍

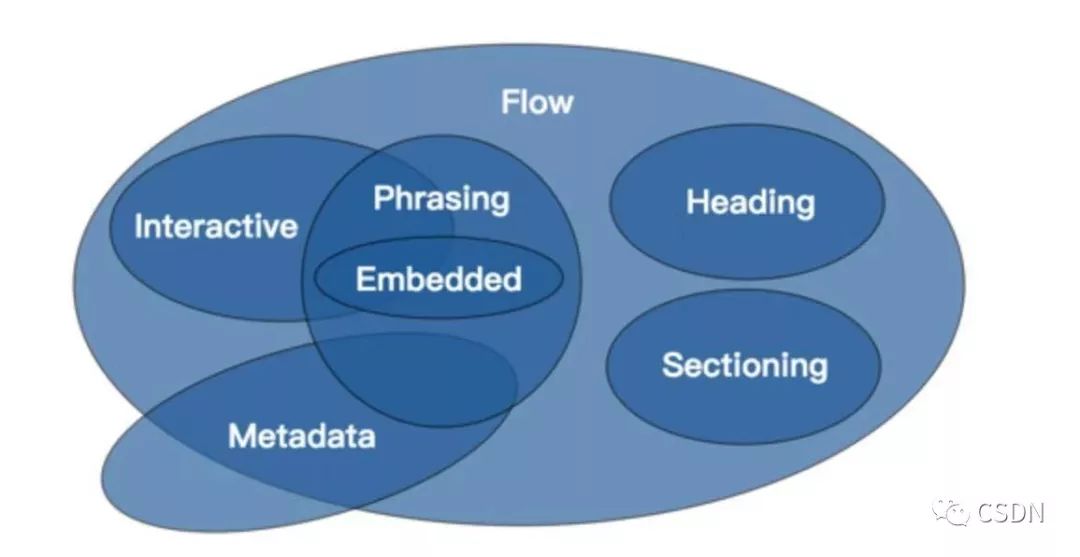
https://www.w3.org/TR/html52/dom.html#content-models
文档模块
功能模块
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0,user-scalable=no">
<!-- Start of Baidu Transcode -->
<meta http-equiv="Cache-Control" content="no-siteapp" />
<meta http-equiv="Cache-Control" content="no-transform" />
<meta name="applicable-device" content="pc,mobile">
<meta name="MobileOptimized" content="width"/>
<meta name="HandheldFriendly" content="true"/>
<meta name="mobile-agent" content="format=html5;url=https://www.jianshu.com/p/b1334dc59dfb">
<!-- End of Baidu Transcode -->
<meta name="description" content="webpack配置文件,增加插件transform-es3-property-literals和transform-es3-member-expression-literal">
<meta name="360-site-verification" content="604a14b53c6b871206001285921e81d8" />
<!-- Apple -->
<meta name="apple-mobile-web-app-title" content="简书">
<!-- Meta for Smart App Banner -->
<meta name="apple-itunes-app" content="app-id=888237539, app-argument=jianshu://notes/10802047">
<!-- End -->
<!-- Meta for Twitter Card -->
<meta content="summary" property="twitter:card">
<meta content="@jianshucom" property="twitter:site">
<meta content="Babel转ES5后IE8下的兼容性问题解决方案" property="twitter:title">
<meta content="1、webpack配置文件,增加插件transform-es3-property-literals和transform-es3-member-expression-liter..." property="twitter:description">
<!-- End -->
<!-- Meta for Facebook Applinks -->
<meta property="al:ios:url" content="jianshu://notes/10802047" />
<meta property="al:ios:app_store_id" content="888237539" />
<meta property="al:ios:app_name" content="简书" />
<meta property="al:android:url" content="jianshu://notes/10802047" />
<meta property="al:android:package" content="com.jianshu.haruki" />
<meta property="al:android:app_name" content="简书" />
<!-- End -->
排版模块
装饰模块
<strong>strong表示内容的重要性
</strong>
<br />
<em>em表示内容的着重点。em可以作为strong的子标签,更加突出重要性
</em>
<br />
<code>Computer code
</code>
<br />
<kbd>Keyboard input
</kbd>
<br />
<tt>Teletype text
</tt>
<br />
<samp>Sample text
</samp>
<br />
<var>Computer variable
</var>
<br />
<dfn>dfn定义一个定义项目
</dfn>
<br />
<abbr>abbr:表示全词的缩写;
</abbr>
<br />
<acronym>acronym:表示标记一个首字母缩写
</acronym>

大片文本的显示模块
xmp 则是在语法高亮没有发明之前,能完整地显示某一段 HTML 片断的结构的唯一标签。
<xmp>
<div>show me</div>
<table>
<tr>
<th style="width: 10%">版本</th>
<th style="width: 15%">更新时间</th>
<th style="width: 20%">贡献者</th>
<th>编辑原因</th>
<th style="width: 10%">操作</th>
</tr>
</table>
</xmp>

表单模块
表单模块是 HTML 最早支持的标签集,包括我们一直熟悉的 <form>、<input type="text" />、<input type="password" />、<input type="radio" />、<input type="checkbox" />、<input type="button" />、<textarea>、<select>、<optgroup>、<option> 。这些元素都是有一个特点,可以通过 tab 键切换下一个表单元素,可以设置 readony 属性防止用户修改它的值,可以设置 disabled 属性忽略该元素的值。在 HTML5 中,还存在 pattern 与 required,实现对表单的自动验证。
<form action="">
<label>姓名:<input type='text' size='20'/></label> <br/>
<label>密码:<input type='password' size='20' value="xxx"/></label> <br/>
<p><input type='radio' value="男"/>男
<input type='radio' value="女"/>女
</p>
<p><input type='checkbox' value="985"/>985
<input type='checkbox' value="211"/>211
<input type='checkbox' value="三本"/>三本
<input type='checkbox' value="大专"/>大专
</p>
<p><select><option selected>随便选些什么</option></select></p>
<p><button type="submit">提交</button></p>
</form>

表格模块
表格开始时用来呈现execl类似的数据, 后来被人们用来做布局用了。许多网页制作工具,如上古时代的 Dreamweave 就是它生成页面。这页面能完美还原大家拖拽出来的效果,但是想再次加工就麻烦了。table 家族包括了 <table>、<thead>、<tbody>、<tfoot>、<th>、<td>、<col>、<colgroup>、<th>。
<table cellspacing=0 border=1 style="bordercolor:#C0C0C0;" align="center" width="100%">
<tr align="center" style="background:#628FC3"><td colspan="5" height="100px" width="100%" >页首
</td></tr>
<tr align="center" style="background:#CBDAEB"><td height="30px" width="20%">标题1
</td><td width="20%">标题2
</td><td width="20%">标题3
</td><td width="20%">标题4
</td><td width="20%">标题5
</td></tr>
<tr align="center"><td height="300px" style="background:#92D050">侧导航栏
</td><td colspan="4" style="background:#00B0F0">主页内容
</td></tr>
<tr align="center"><td height="50px" colspan="5" style="background:#FFC000">页尾
</td></tr>
</table>
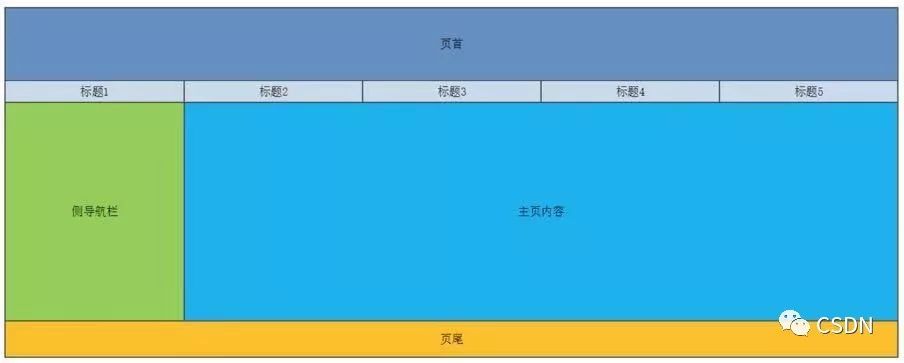
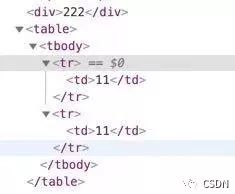
table 模板的标签是具有很强的排他性,只能在 td 与 th 加东西标签与文本,在 tr 或 tbody 之间加东西,它们会漏到外面去。
<table>
<tr><td>11</td></tr>
<div>222</div>
<tr><td>11</td></tr>
</table>
<p><div>xxx</div></p>

页面组装模块
在网速起来后,页面的功能就会越堆越多,于是需要许多人共同开发一个页面。如果协作开发页面,在 JavaScript 没有模块化技术的情况下,浏览器提供了几个标签实现它:<frameset>、<frame>、<iframe>。它们都是自己独立的作用域,不用考虑全局变量的问题,不也用考虑某人的代码出 Bug 影响到其他人的情况。唯一要注意的是,防止别的网站用 frame 来装载我们的网站来做坏事,当然浏览器也会在这些标签上添加越来越多这样的属性。现在许多政府后台系统还是基于框架结构来构建页面。
广告模块


地图模块
地图模块涉及两个特别的标签 <map>、<area> 及一个常见的 <img> 标签。map 标签起来统帅的作用,而 area 标签则起着与其他标签不一样的触发区域。一般的可视标签,都是呈现为矩形。而 area 标签则根据它的 share 属性呈现为各种形状及不规则的多边形。
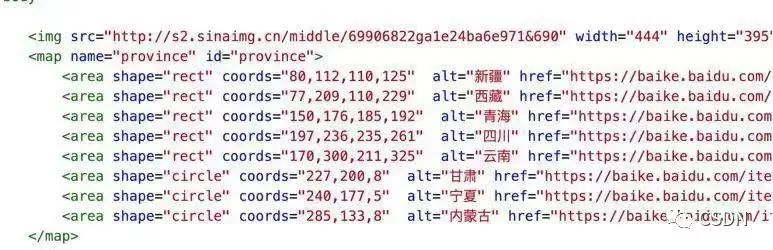
容灾模块
多媒体模块

多种文档的混排
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
HTML 4.01 Strict
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
XHTML 1.0 Frameset
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
XHTML 1.0 Transitional
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
XHTML 1.0 Strict
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
XHTML 1.1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<!DOCTYPE html>
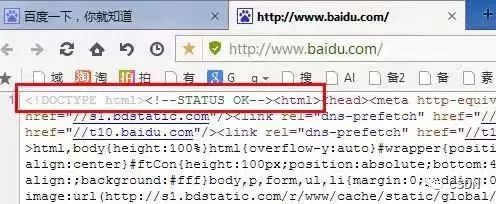
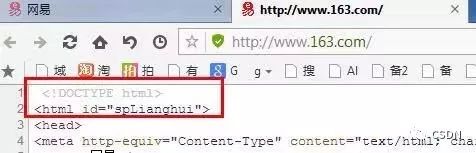
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>HTML/SVG Example
</title>
</head>
<body>
<math>
<mrow>
<mrow>
<msup>
<mi>a
</mi><mn>2
</mn>
</msup>
<mo>+
</mo>
<msup>
<mi>b
</mi><mn>2
</mn>
</msup>
</mrow>
<mo>=
</mo>
<msup>
<mi>c
</mi><mn>2
</mn>
</msup>
</mrow>
<mrow>
<mi>A
</mi>
<mo>=
</mo>
<mfenced open="[" close="]">
<mtable>
<mtr>
<mtd>
<mi>x
</mi>
</mtd>
<mtd>
<mi>y
</mi>
</mtd>
</mtr>
<mtr>
<mtd>
<mi>z
</mi>
</mtd>
<mtd>
<mi>w
</mi>
</mtd>
</mtr>
</mtable>
</mfenced>
</mrow>
</math>
<svg width="150" height="100" viewBox="0 0 3 2">
<rect width="1" height="2" x="0" fill="#008d46" />
<rect width="1" height="2" x="1" fill="#ffffff" />
<rect width="1" height="2" x="2" fill="#d2232c" />
</svg>
</body>
</html>
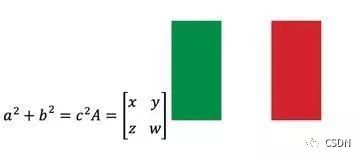

HTML5 的进化
现在我们对 HTML 的关注不如以前了,事实上 WHATWG 对它做了非常宏大的规划,非常多的功能需要逐年来迭代。但 React 这些大型前端框架的出现,掩盖了浏览器的努力。以前 Chrome 每次发版本常常吸引眼球,但 babel 可以让你用上还在讨论中的语言特性!那么让我们略微看一下 HTML5 的新特征吧。
-
装饰性标签基本废弃,使用带语义的装饰化标签代替 -
增加大量的表单元素 -
增加大量的布局标签 -
多媒体标签进化
语义化标签的崛起
<b>加粗文字(bold) <i>倾斜文字(italic) <u>给文字加下划线(underline) <s>给文字加删除线(strike),其实早期是存在<strike>标签
<strong>定义重要性强调的文字(strong) <ins>定义插入的文字(inserted) <em>定义强调的文字(enphasized) <del>定义被删除的文字(deleted)
更多表单元素
早期的表单元素,我们可以从收音机里挖到它们的本源。但经过20年来的发展,网页世界也有自己的创新,各式各样的日历、调试器,于是它们成为浏览器的自带控件了。下面是一些新标签:<meter>、<progress>、<outer>、 <datalist>,此外更多功能是复用到 input 标签,各种类型的日历、月历、年历、时间。

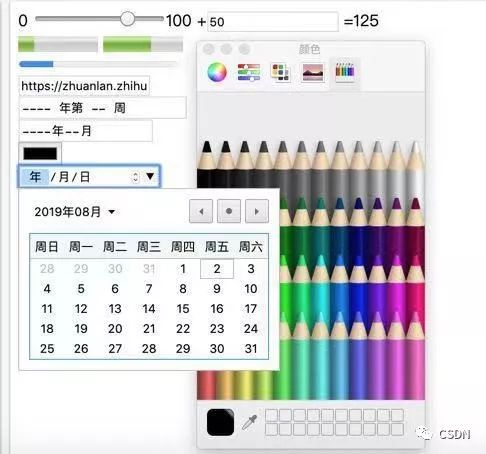
更多布局元素
<body>
<div id="wrapper">
<div id="header">
<h3>header
</h3>
</div>
<div id="out-content">
<div id="content-box">
<div id="content">
<h3>content
</h3>
</div>
</div>
<div id="sidebar">
<h3>sidebar
</h3>
</div>
</div>
</div>
<div id="footer">
<h3>footer
</h3>
</div>
</body>
-
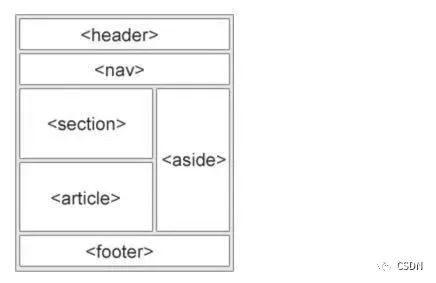
<main> 标签规定文档的主要内容。一个页面只能出现一个<main> 标签。并且它不能被其他布局元素所包含。 -
<header>:描述了文档的头部区域,于定义内容的介绍展示区域。 -
<nav>:定义导航链接的部分。 -
<section>:定义文档中的节(section、区段)。比如章节、页眉、页脚或文档中的其他部分,section通常包含了一组内容及其标题。 -
<article>:定义独立的内容。 -
<aside>:定义页面主区域内容之外的内容(比如侧边栏)。 -
<figure>:标签规定独立的流内容(图像、图表、照片、代码等等)。 -
<figcaption>:定义 <figure>元素的标题。 -
<footer>:述了文档的底部区域,一个页脚通常包含文档的作者,著作权信息,链接的使用条款,联系信息等。
<!-- https://www.w3school.com.cn/tags/tag_dialog.asp -->
<table border="1">
<tr>
<th>一月 <dialog open>这是打开的对话窗口</dialog></th>
<th>二月</th>
<th>三月</th>
</tr>
<tr>
<td>31</td>
<td>28</td>
<td>31</td>
</tr>
</table>
![]()

多媒体的增强

观摩地址:https://gallery.echartsjs.com/editor.html?c=xHku9OE96l
DOM的标准化
自定义标签
http://www.ruanyifeng.com/blog/2019/08/web_components.html
各种页面性能优化方案的内置实现
preload
<link rel=
"preload" href=
"/path/to/style.css"
as=
"style">
prefetch
<link rel="preload" href="./manifest.js" as="script">
<link rel="preload" href="./vendor.js" as="script">
<link rel="preload" href="./app.js" as="script">
<link rel="prefetch" href="./vendor-async.js">
<link rel="prefetch" href="./user.js">
prerender
<link rel="prerender" href="//example.com/next-page.html"/>
prerender与prefetch都是针对下一个页面。
preconnect
<link rel="preconnect" href="//example.com">
<link rel="preconnect" href="//cdn.example.com" crossorigin>
dns-prefetch
<!-- 开启DNS预获取 -->
<meta http-equiv="x-dns-prefetch-control" content="on">
<!-- 设置DNS预获取的域名 -->
<link rel="dns-prefetch" href="//g.alicdn.com" />
defer
async



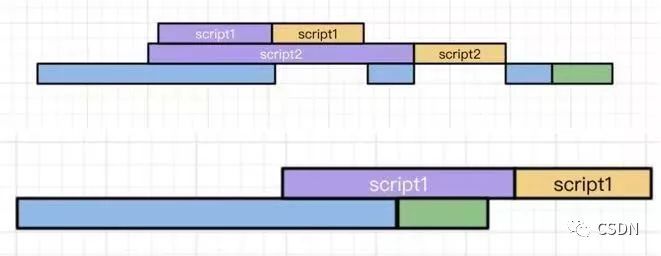
推荐的应用场景

结语
作者简介:司徒正美,拥有十年纯前端经验,著有《JavaScript框架设计》一书,去哪儿网公共技术部前端架构师。爱好开源,拥有mass、Avalon、nanachi等前端框架。目前在主导公司的小程序、快应用的研发项目。
声明:本文图片版权系作者所有,使用需标明出处。



☞主链增幅最高飚至152%,主流币却惊现回落;以太坊发币速度持续放缓
☞字节跳动李航:自学机器学习,研究AI三十载,他说AI发展或进入平缓期
![]()
你点的每个“在看”,我都认真当成了喜欢





