利用Python进行市场购物篮分析——入门篇
python分析师可以使用许多数据分析工具,但知道在哪些情况下使用哪些数据分析工具可能很困难。一种有用的(但却被忽视)的技术称为关联分析,它尝试在大型数据集中查找相关商品之间的关联。一个具体的应用通常称为市场篮子分析。最经典引用的市场篮子分析的例子是所谓的“啤酒和尿布”案例。基本的故事是,大型零售商能够挖掘他们的交易数据,并找到一个意想不到的购买啤酒和婴儿尿布的购买模式。
不幸的是,这个故事很可能是一个数据城市传奇。然而,它是挖掘事务数据可以获得的商业价值的示例。
如果你对Python数据科学有一些基本的了解,可能你的第一个倾向就是考虑scikit学习一个现成的算法。然而,scikit-learn不支持这种算法。幸运的是,Sebastian Raschka 提供了非常有用的具有Apriori算法的MLxtend库的,以方便我们进一步分析我们所掌握的数据。
接下来我将演示一个使用此库来分析相对较大的在线零售数据集的示例,并尝试查找有趣的购买组合。在本文结尾处,我希望你能掌握将其应用于你自己的数据集的基本方法。
为什么是关联分析?
在当今的世界,有许多复杂的数据分析方法(聚类,回归,神经网络,随机森林,SVM等)。这些方法中的很多种所面临的挑战在于它们可能难以调整,并需要相当多的数据准备和特征工程才能获得好的结果。换句话说,它们都非常强大,但需要掌握很多知识才能正确实现。
关联分析对数学知识的掌握要求非常低,而且结果易于向非技术人员解释。此外,它是一种无监督的学习工具,可以查找隐藏的模式,因此对数据准备和特征工程的需求有限。对于某些数据探索案例来说,这是一个很好的开始,并且可以发现使用其他方法深入了解数据的方式。
另外一个额外的好处,MLxtend库中的python实现对于非常熟悉scikit-learn 和pandas应该是非常简单的。由于所有这些原因,我认为这是一个有用的工具来帮助你解决数据分析实际问题。
关联分析101
理解关联分析中常用使用的几个术语很重要。在介绍数据挖掘是为那些有兴趣了解这些定义和算法实现的人,让他们对关联分析的数学方法有一个基本的概念。
关联规则通常如下:{Diapers} - > {Beer},这意味着在同一交易中购买尿布的客户之间和购买啤酒之间存在很强的关系。
在上面的例子中,{Diaper}是前提,{Beer}是后果。前提和后果可以包含很多内容,换句话说,就是类似{Diaper,Gum} - >{Beer,Chips}也是一个有效的关联规则。
信心是对关联规则可靠性的度量。上述例子中有0.5的信心意味着在购买了Diaper和Gum的情况下,有50%的可能去购买Beer和Chips。对于产品推荐,50%的置信度可能是完全可以接受的,但在医疗情况下,此级别可能不够高。
如果两个规则是独立的,Lift是观察到的支持与预期的支持的比率(lift解释详见维基百科)。基本的经验法则是Lift接近1表示规则完全独立。Lift> 1通常更“有趣”,可以表示这是有用的规则模式。
最后一个注意事项,与数据有关。此分析要求将交易的所有数据包含在1行中,并且编码方式应为one-hot编码(了解one-Hot编码)。了解MLxtend 的文档对了解如何运用是非常有用:
本文的具体数据来自UCI机器学习存储库,数据代表了2010-2011年英国零售商的交易数据。这主要代表的是批发商的销售数据,所以它与消费者购买模式略有不同,但仍然是一个有用的案例研究。
代码讲解
可以使用pip安装MLxtend,只有安装了MLxtend下面的代码才能真正运行。一旦安装完毕,下面的代码将会开始工作。我已
经将源代码上传至Github,以方便你的下载。
获取我们的Pandas和MLxtend代码导入并读取数据:

我们需要做一点数据处理。首先,一些数据描述中具有需要删除的空格。我们还会删除没有发票编号的行,并删除信用交易(发票编号包含C)。

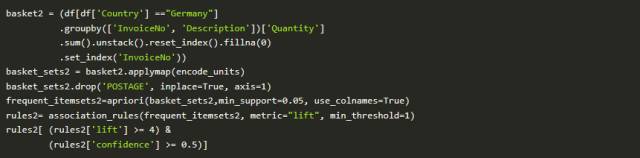
数据清理完成后,我们需要将每个产品进行one-hot编码。为了保持数据集小,我选择只是看法国的销售记录。然而,在下面的其他代码中,我将这些结果与德国的销售进行比较。进一步的国家比较将会是有趣的调查。

以下是前几列的样子(注意,我在列中添加了一些数字来说明这个概念,这个例子中的实际数据全是0).
数据中有很多零,但是我们还需要确保将任何正则转换为1,而将0设置为0。此步骤将完成数据的one-hot编码,并删除邮资列:

既然数据的结构是正确,我们可以生成支持至少7%的频繁项目集(选择这个数字,可以帮助我得到更多有用的例子。)

最后一步是产生相应的信心和提升的规则:

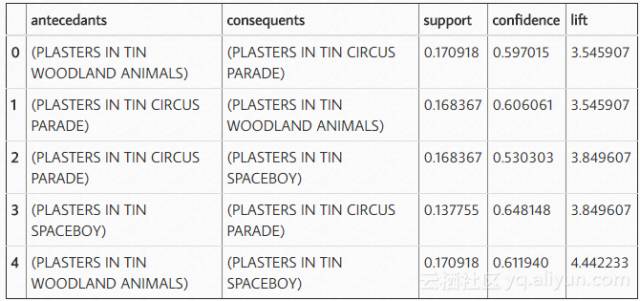
这就是这个项目的一切!
现在,最棘手的部分是弄清楚我们得到的这些结论告诉我们什么了。可能绝大多数程序猿不太关注。例如,我们可以发现很多关联规则具有很高的提升价值,这意味着它的发生频率可能会高于交易和产品组合数量的预期值。这部分分析是行业知识将派上用场的地方。由于我没有,所以我只是想找几个说明性的例子。
我们可以使用标准的pandas code来过滤数据帧。在这种情况下,寻找一个lift(6)和高信度(.8):

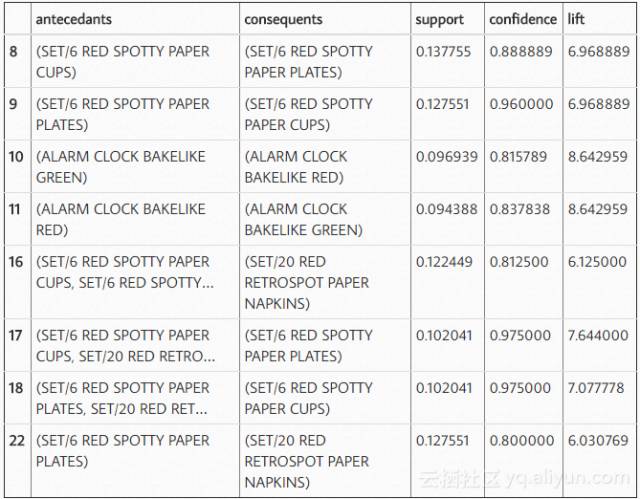
在查看规则时,可以发现似乎绿色和红色闹钟是一起购买的,红纸杯,餐巾纸和纸板是以总体概率提高的方式一起购买的。
您可能想要看看有多大的机会可以使用一种产品的受欢迎程度来推动另一种产品的销售。例如,我们可以看到,我们销售340个绿色闹钟,但只有316个红色闹钟,所以也许我们可以通过科学的方法来推动更多的红色闹钟销售。

我们来看看德国有什么流行的组合呢?
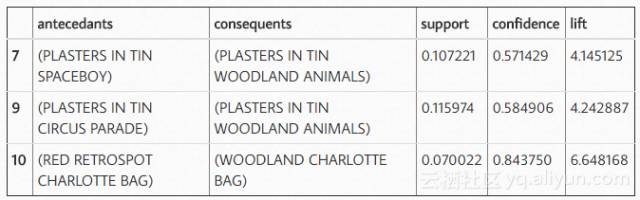
似乎除了大卫·哈塞尔夫以外,德国人喜欢锡太太雄和林地动物的Plaster。
在非常认真的情况下,熟悉数据的分析师可能会有十几个不同的问题,即这种类型的分析可以发挥商业价值。我没有将此分析复制到额外的国家或客户组合,但是由于上述基本的熊猫代码,整个过程将相对简单。
结论
关联分析有一个非常好的方面是它很容易运行,相对容易解释。如果您没有使用MLxtend和关联分析,则使用基本Excel分析找到这些模式将是非常困难。使用python和MLxtend,分析过程相对简单,如果你了解Python,你可以访问python生态系统中的所有其他可视化技术和数据分析工具。
最后,我建议您查看MLxtend库的其余部分。如果您在使用scikit-learn做工作,可以了解并熟悉MLxtend,以及如何增加数据科学工具包中的一些现有工具。
往期精彩文章
0 【沉淀】从中间件到搜索,从安卓到分布式计算,阿里李睿博谈自己的折腾路
1 阿里云最狂热的PostgreSQL技术传播者,2000篇文章让你立马掌握这个技术
-END-

云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维

点击“阅读原文”





