一份问答系统的小结
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要12分钟
跟随小博主,每天进步一丢丢


来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/35667773
作者 | susht
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
Part I:基于知识图谱的QA
Part II:基于阅读理解的QA
Part III:基于多轮交互的对话系统
前言
问答系统是非常热门也是很有前景的一个领域,学术界有很多人在研究,工业界也在积极寻求落地,因此本文对问答系统的发展现状和做法做了一个综述整理。模型非常多,这里不会一一展开介绍,而是把这些方法的特点进行归类。
Part I:基于知识图谱的QA
以知识图谱构建事实性问答系统,也称之为KB-QA,在业界是一种比较靠谱的做法,从知识图谱中寻找答案。对事实性问答任务而言,这种做法依赖于知识图谱,准确率比较高,同时也要求我们的知识图谱是比较大规模的,因为KB-QA无法给出在知识图谱之外的答案。KB-QA又可以分成两类:基于符号表示的KB-QA,基于向量表示的KB-QA。
知识图谱并不是我的领域,但我实验室有人在做知识图谱,所以我也有一些大概了解。
基于符号表示的KB-QA
这种做法主要是利用语义解析的方法对问题进行解析,把问题转换成逻辑表达式,再加上一些规则,得到一个结构化的SQL查询语句,用来查询知识库得到答案。
语义解析的传统做法是:问题->短语检测->资源映射->语义组合->逻辑表达式
短语检测:词性标注、实体识别
资源映射:实体链接、实体消岐、关系抽取
语义组合:将映射得到的资源进行组合,得到逻辑形式。
训练分类器:计算每一种语义解析结果的概率,再对于问答对计算损失函数。
现在的做法一般是:
首先是建图:包含知识库实体(圆角矩形,比如family guy),聚合函数(棱形,比如argmin),中间变量 y 和答案变量 x
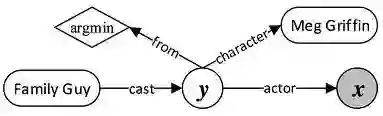
对问题进行信息抽取:提取问题特征(问题词,问题焦点,问题主题词和问题中心动词),识别命名实体,进行词性标注来删除限定词和介词。
确定核心推导链:将自然语言问题,映射为一个谓语序列
增加约束和聚合:增加约束和聚合函数相当于扩展查询图,缩小答案范围
构建查询图特征:主题词链接特征,核心推导链特征,约束聚合特征,总体特征
分类器:对查询图做二分类,只有正确的查询图才是正样本。
基于向量表示的KB-QA
知识表示是近几年很火的方向,就像词向量刚出来那会也发了很多论文,不过现在热度转向知识推理了。基于向量表示的KB-QA主要是对问题和答案学习到一个向量表示,然后进行向量匹配,归根到底就是个匹配问题。这种方法就是我当时差点要入的坑,后来因为项目比较繁琐 时间也不够,选择了基于文本的QA。
我们先把问题和候选答案都映射成向量,
如何学习问题向量:把问题用LSTM进行建模(因为问题本来就是自然语言)
如何学习答案向量:答案不能简单映射成词向量,一般是利用到答案实体,答案类型,答案路径(从问题主题词到答案的知识库路径),答案关系(从主题词到答案之间的知识库关系),答案上下文信息(与答案在一定范围内有连接的知识库实体),然后把这些特征分别映射成不同的向量,作为答案的其中一个向量(而不是直接拼接起来),最后用这些特征向量依次和问题做匹配,把score加起来作为总的score。
接下来我们要对问题和答案进行向量匹配,计算问题-答案score,常见的有,
最简单的方法:直接进行向量点乘,可以用CNN对这种方式做改进
Attention匹配法:计算答案对问题每一步的Attention

我们的训练目标是:一般用Margin Loss,极大化问题对正确答案的score,同时极小化问题对错误答案的score。
当模型训练完成后,通过score进行筛选,取最高分的作为最终答案。
另外,有一些论文加入了Multi-Task Learning,同时使用TranE去训练知识库。
也可以使用记忆网络来做,首先通过Input模块来处理问题,加入知识库信息,将三元组通过输入模块变换为一条一条的记忆向量,再通过匹配主语获得候选记忆,进行cos匹配来获取最终记忆,将最终记忆中的宾语输出作为答案。
现在来比较一下基于符号和向量的方法:
1)基于符号的方法,缺点是需要大量的人工规则,构建难度相对较大。优点是通过规则可以回答更加复杂的问题,有较强的可解释性。
2)基于向量的方法,缺点是目前只能回答简单问题,可解释性差。优点是不需要人工规则,构建难度相对较小。
因此目前可以改进的地方有:
1)复杂问句,目前End2End的模型只能解决简单问答。
2)多源异构知识库问答,对于开放域问答,单一的知识库不能完全回答所有问题。
3)训练语料,知识库中有实体和关系,除此之外还可能有描述实体的文本信息,或许可以结合结构化知识和非结构化文本,也就是Part II要介绍的方法。
Part II:基于阅读理解的QA
这个就是我所研究过的领域了,对非结构化文章进行阅读理解得到答案,又可以分成匹配式QA,抽取式QA和生成式QA,目前绝大部分是抽取式QA。但是我有一段时间没有follow了,不知道能不能跟上时代的步伐,因为阅读理解花样很多,但是基本框架应该差不多的。
匹配式QA
给定文章,问题,和一个候选答案集(一般是实体或者单词),从候选答案中选一个score最高的作为答案。这种形式比较像选择题型,已经基本上没人做了。
具体的问题可以定义为多分类问题:

其中d是document,q是query,a是answer,求概率最大的候选答案。注意:词汇表V 可以定义为 document 和 query 中的所有词,也可以定义为所有的 entity,或者定义为这篇document里面的词,而有的会直接提供包括正确答案在内的 N个候选答案。
重点在于求解g(d, q),g是对document和question建模得到的向量,把这个向量变化到词表空间再进行归一化可以得到所有候选score。求解g的方式比如:
1)LSTM Reader:直接把query跟document拼接起来,输入到双向LSTM中,最终得到一个向量g,这种做法非常粗糙,只是提供一个简单的baseline。
2)Attentive Reader:先对query用LSTM进行建模得到问题向量u,然后也对document建模,接下来用u 给document分配attention,去算文章向量r,再结合u和r得到g。相当于每读完一个问题,然后带着这个问题去读文档。
3)Impatient Reader:这里考虑到了query的每一个token,每个token都去算一个r。相当于每读问题的一个字,都要读一遍文档。(增加计算量)
4)Gated-Attention Reader:相当于带着一个问题,反复读文档,读k遍。
抽取式QA
目前认同度最高的应该是斯坦福的SQuAD数据集,数据形式是给定一篇文章,围绕这个文章提出一些问题,直接从文章中扣答案出来。这个数据集是基于维基百科爬取的真实文章,
目前难度比较高的应该是 TriviaQA数据集,在语义各方面难度都要超过squad。
常见的模型框架基本上是这样:
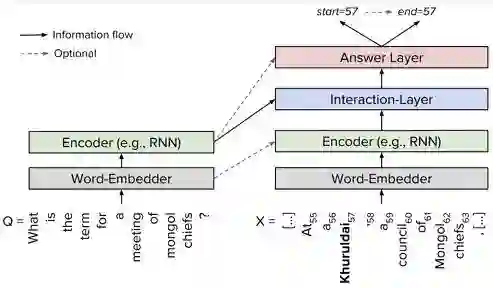
Embedder:对词进行embedding
Encoder:分别对问题和文章用LSTM进行建模。
Interaction Layer:各种Attention机制花式结合问题和文章,对问题和文章进行交互,在原文上得到query-aware的文章表示。(差别主要在这一部分)
Answer Layer:用query-aware的文章表示来预测答案,一般是用两个网络分别预测答案起止位置,或者直接对文章进行答案标注。
这里简单介绍一下,
最简单的就是Match-LSTM:Interaction 层用的是中规中矩的Attention,用到两种预测答案的模式,其中Boundary Model 比较简单好用。
BiDAF 也比较出名:Interaction 层中引入了双向注意力机制,使用Query2Context 和 Context2Query 两种注意力机制,去计算 query-aware 的原文表示。另外在Embedder 层用到词级 embedding 和字符级 embedding,这倒不是什么新奇的做法,我记得很早就看过这种embedding了,比较适合英文。
FastQAExt 主打轻量级:在Interaction 层用了两种轻量级的信息 fusion 策略;Embedder 层加入了一些额外特征(这个确实有用);确定答案范围的时候用到了Beam Search(这个一般用在机器翻译的Decode测试阶段)
R-NET 也是曾经占领过leaderboard第一的模型:双 Interaction 层架构,分别捕捉原文和问题之间的关系(类似于match-lstm),原文内部各词之间的关系(self match);先预测答案开始概率,更新RNN状态,再预测答案截止位置。
其实......看得多了.......感觉都是在堆模型........
生成式QA
目前只有MSRA的MS MARCO数据集,答案形式是这样的:
1)答案完全在某篇原文
2)答案分别出现在多篇文章中
3)答案一部分出现在原文,一部分出现在问题中
4)答案的一部分出现在原文,另一部分是生成的新词
5)答案完全不在原文出现(Yes / No 类型)
MSRA发布这个数据集后,也发布了S-Net,在R-Net基础上使用Multi task Learning,先抽取出答案后,利用这个特征再对文章生成答案。

抽取部分:

这个模型同时做了两个任务,预测答案ID,还有对文档进行排序。左下角是对问题建模,右下角是对文章建模,左上角是预测答案ID,右上角是对文章进行排序,对问题跟答案去算一个score,去做排序。
但是我总觉得右下角画得不够严谨,这里其实是用到所有passages去预测ID,再对单个passage计算score,图中应该是只画了一个passage的多个词。
生成部分:
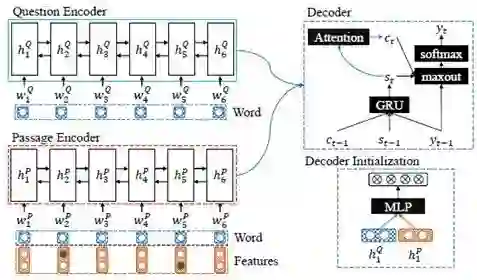
前面花这么大力气标注出答案后,其实.....这里只是作为一个特征信息叠加到文章向量中,对这段文章和问题,重新通过Encoder建模(其实我觉得这里问题所用的LSTM,可以和前面抽取模型中的问题LSTM共享,不需要重新搞一下问题LSTM),得到一个综合的语义向量,再输入到Decoder中生成答案。就是一个简单的seq2seq模型。
这个论文我本来打算follow的,但是数据集处理实在麻烦,而且感觉模型也各种复杂(并不是说他难,而是说他模型庞大,我感觉我可能跑不动)。
然后我刚刚查了一下这个论文的应用,现在渐渐有人去follow这个工作了,比如加上强化学习,同时修正问题和生成答案。OK,这个坑,就留给别人填吧。
然而......有点尴尬的是,自家的数据集,被百度和猿题库刷到前面了,可能MSRA最近也在憋大招,毕竟是长期占领SQuAD排行榜第一的人。
Part III:基于多轮交互的对话系统
我对这个领域了解不多,正在观望。
未完待续






